
Digital Resilience Pays Off
Download this e-book to learn about the role of Digital Resilience across enterprises.
AWS Lambda has emerged as an increasingly popular option for developers who want to run code without provisioning or managing servers. From web applications that can quickly scale in response to user traffic, to real-time data processing and alerting on social signals, Lambda enables companies to increase the pace of software innovation – but presents its own set of monitoring and observability challenges. In this blog, we’ll elaborate on a few things to keep in mind when monitoring AWS Lambda, and how to do so with Splunk Infrastructure Monitoring.
AWS Lambda is Amazon Web Services’ serverless computing or FaaS (function-as-a-service) offering. Serverless computing refers to a specific category in cloud computing where applications run in stateless compute containers that are event-triggered, ephemeral, and completely managed by a third party. AWS Lambda and other serverless computing services run functions—blocks of code that carry out a single, short lived task. Functions are self-contained, have no dependencies on any other code, and can be deployed and executed wherever and whenever they are needed.
The main benefit of AWS Lambda is that it abstracts many operational tasks away from developers. With AWS Lambda, there is no longer any need to provision infrastructure, manage scaling resources, maintain security patches, or perform other administrative tasks – making it possible for developers to run backend code without needing to manage their own server systems or server applications.
More recently, serverless computing has grown such that it’s become another option alongside containerized microservices for organizations who want to increase development velocity and the scalability of their systems. Some teams will deploy both “traditional” microservices running in containers and serverless applications, while others have chosen to run the entirety of their workloads on AWS Lambda or other serverless platforms.
In serverless environments, you’re not given access to the underlying host that your function runs on, meaning that there is no way to install an agent as is common with most metrics monitoring systems, or with traditional APM solutions. If you want to go beyond the basic reporting provided by a service like AWS CloudWatch, collecting metrics and traces from Lambda functions typically requires that you wrap or modify the function itself so that it can report to your monitoring and alerting tool of choice.
Something that is often repeated these days is the phrase “serverless is not without servers”. When your function is invoked, AWS initializes a container to run your function. When this happens for the first time in a while, there may not be an idle container available to run your code – adding latency to the total time needed for your function to execute. This occurrence is referred to as a “cold start”. Tracking cold starts and metrics that represent the business logic of your applications will provide better visibility into your Lambda functions,and highlight ways in which you can optimize performance.
Functions are highly ephemeral and are spun up and down in seconds, if not milliseconds. An ideal monitoring solution for serverless applications provides immediate and ongoing visibility into function performance so that you can make adjustments to your functions or resolve issues before customers are impacted.
Key Lambda metrics to monitor include:
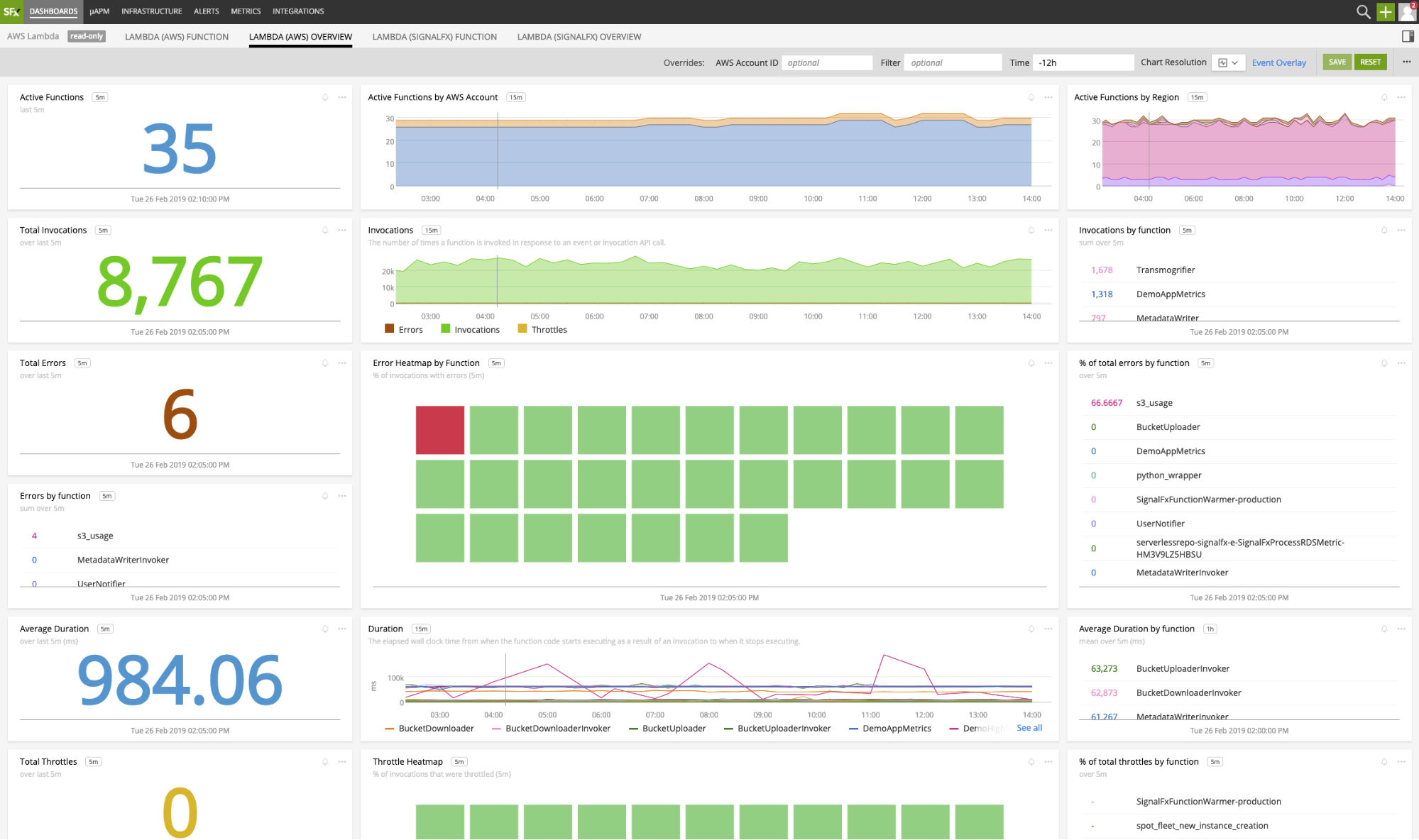
As is the case with monitoring other AWS services, you can sync CloudWatch metrics for your Lambda functions to Splunk. Simply add AWS Lambda-specific statements to your Policy Document, and you’ll be able to view Lambda metrics in the Infrastructure Navigator and a number of pre-built dashboards.
Alongside other services viewed in the Infrastructure Navigator, we give you an aggregated view of system metrics across all of your functions, and the ability to filter down to the subset of functions you’re interested in using a variety of dimensions sent by default, or custom tags you’ve applied.
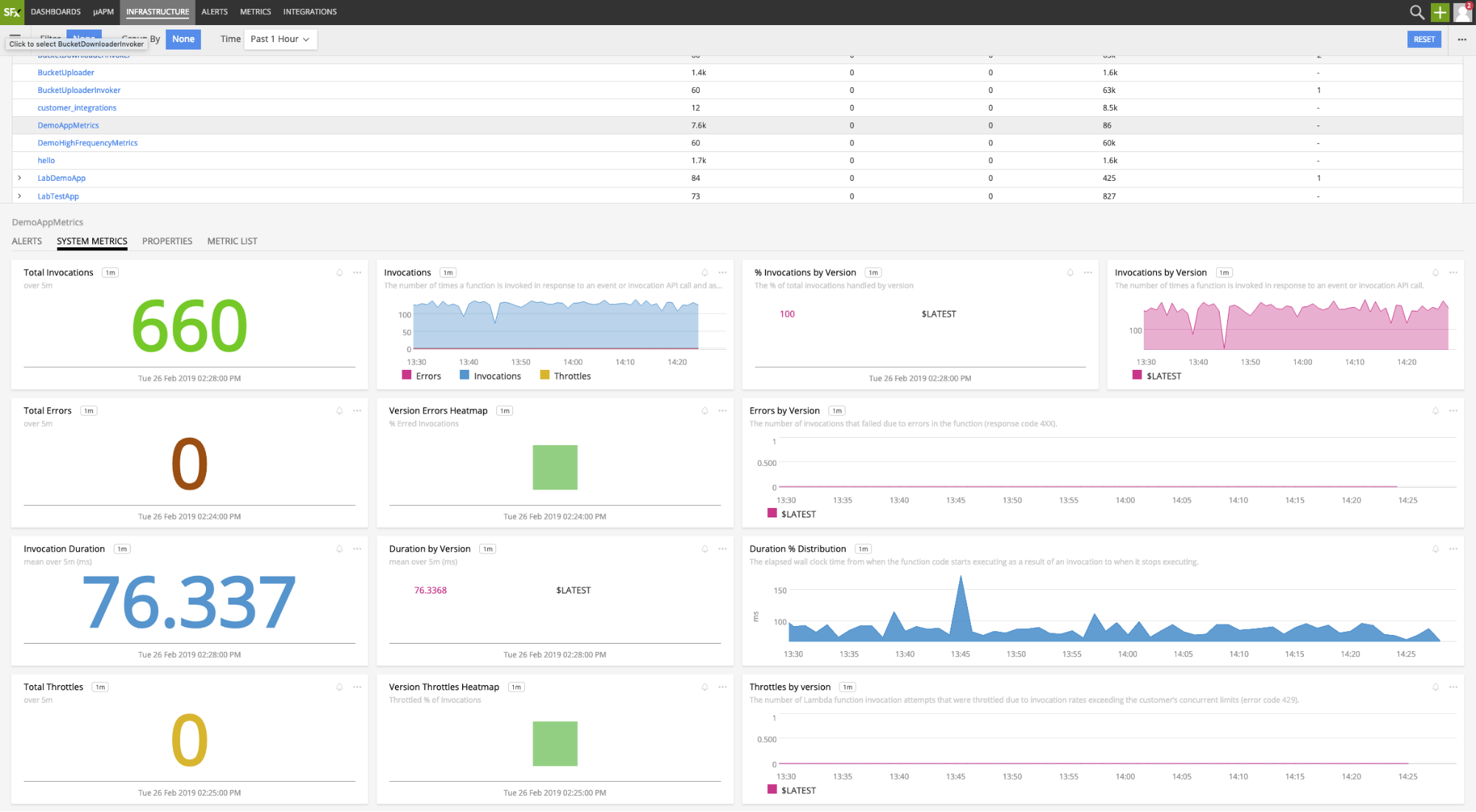
For situations when you need to track function invocations or errors at a level more granular than what CloudWatch can deliver, we provide a function wrapper that includes calls to Splunk with the count of invocations and errors, the execution duration, and whether the functions being called are being impacted by a cold start. We currently provide Lambda wrappers in Node.js, Java, Python, and C#.
The wrapper also provides an easy mechanism to instrument your code for custom metrics that matter to you – simply add a few additional lines within your function to capture and send those metrics to Splunk:

Charts that use data collected by the wrapper can be configured to update more frequently than is possible with CloudWatch, and the default Lambda dashboard will now also include information on whether your functions are being impacted by cold starts.
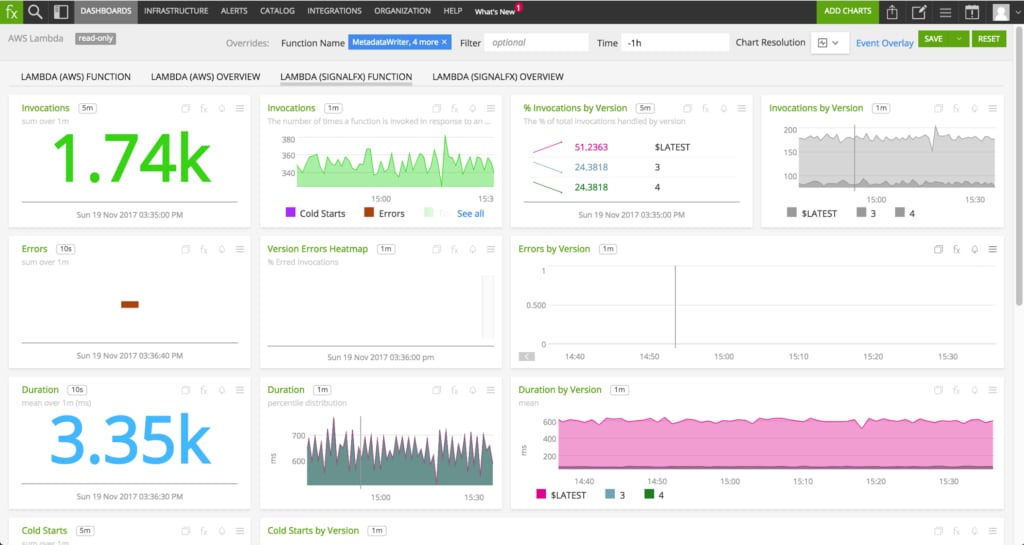
You can also trace your Go, Java, Python, and Node.js Lambda functions with Splunk Infrastructure Monitoring, providing you with even greater visibility into the performance of your serverless applications. After instrumenting your functions and deploying the Splunk Smart Gateway, you’ll be able to observe request latency, duration, and errors for every transaction across your AWS Lambda environment.
We recommend instrumenting with the OpenTracing APIs, and the Jaeger tracer client library that corresponds with the programming language your function is written in. More information on how to instrument in your language is provided in our documentation, and our language-specific guides and tracing examples:
Splunk provides a dynamically generated service map that you can use to quickly isolate services that are contributing to latency or otherwise anomalous performance.
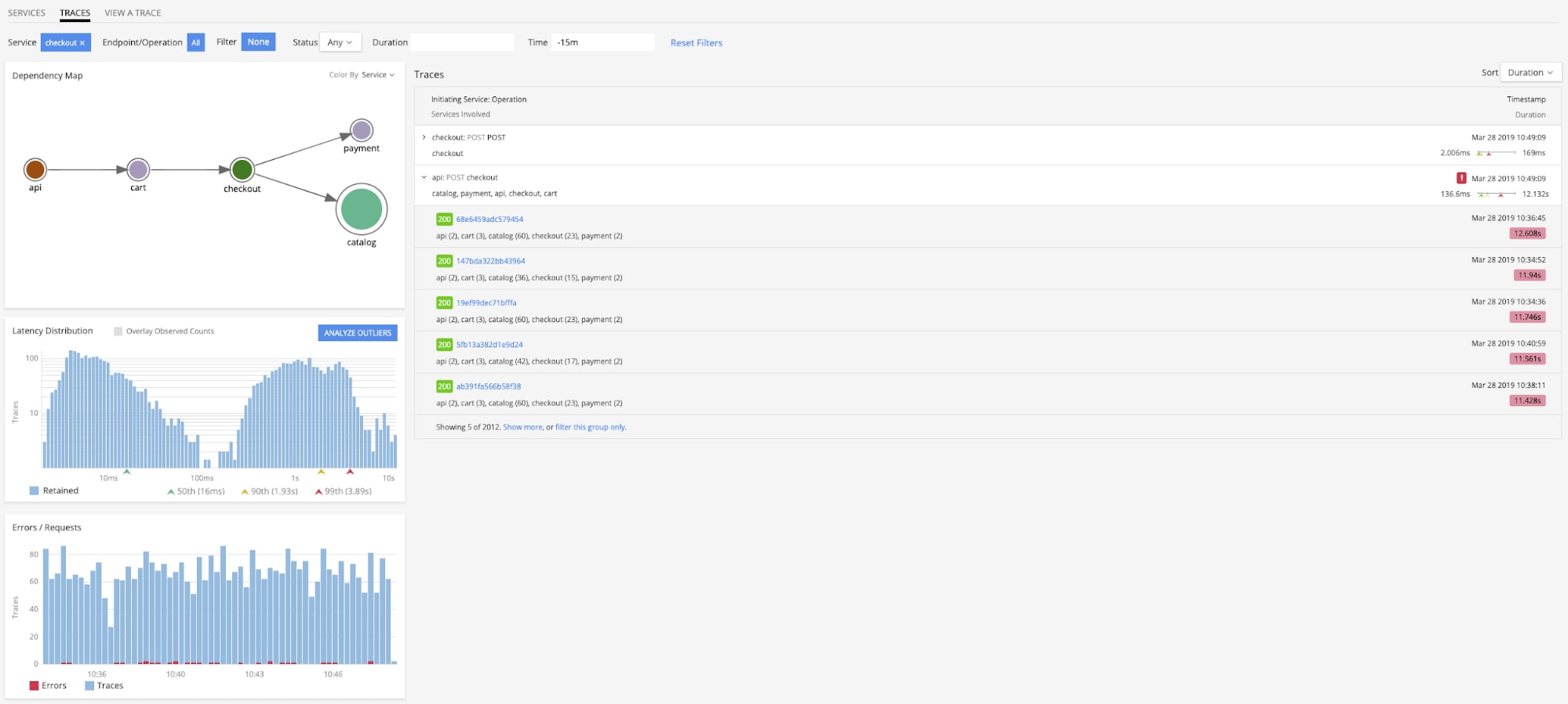
When further investigation is required, you can use the Outlier Analyzer to immediately uncover patterns relating trace metadata tags to request duration, and begin to explain what might be contributing to degraded performance.
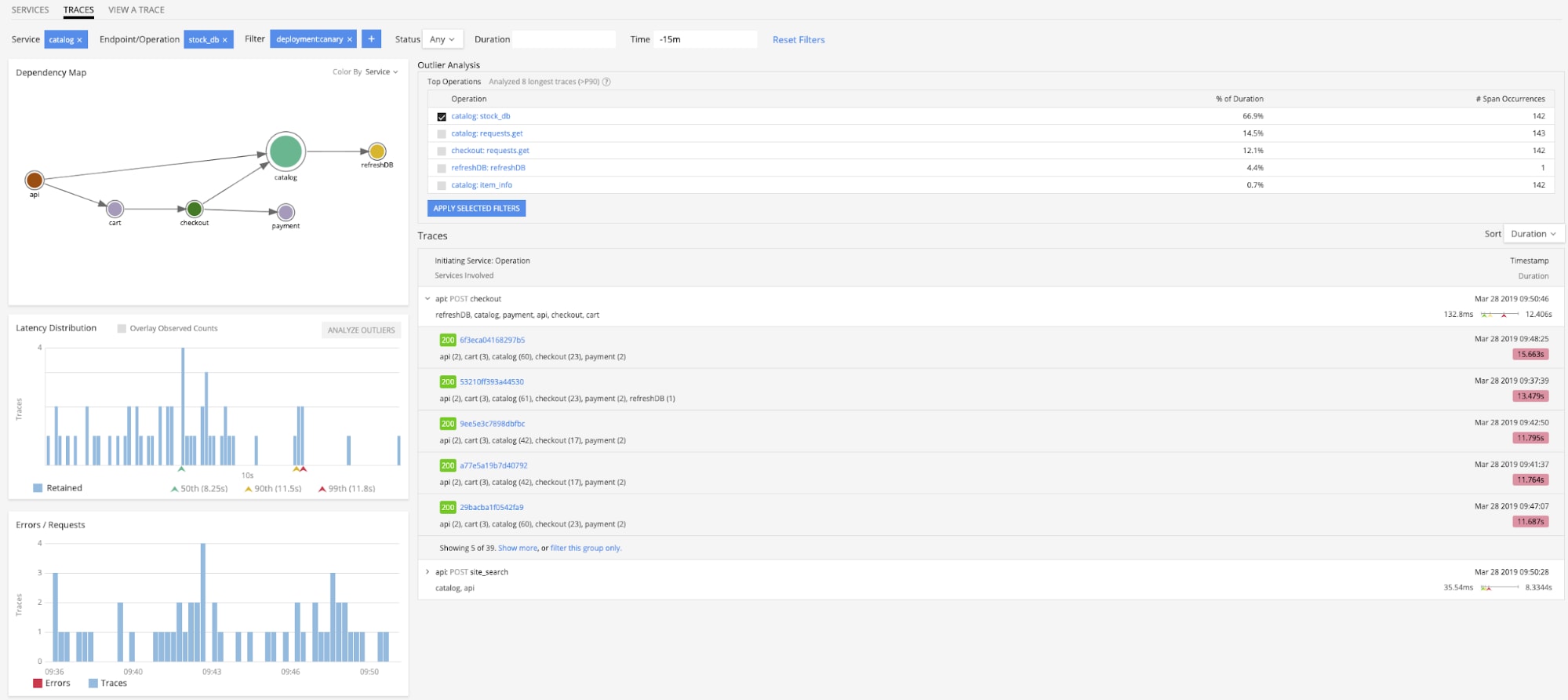
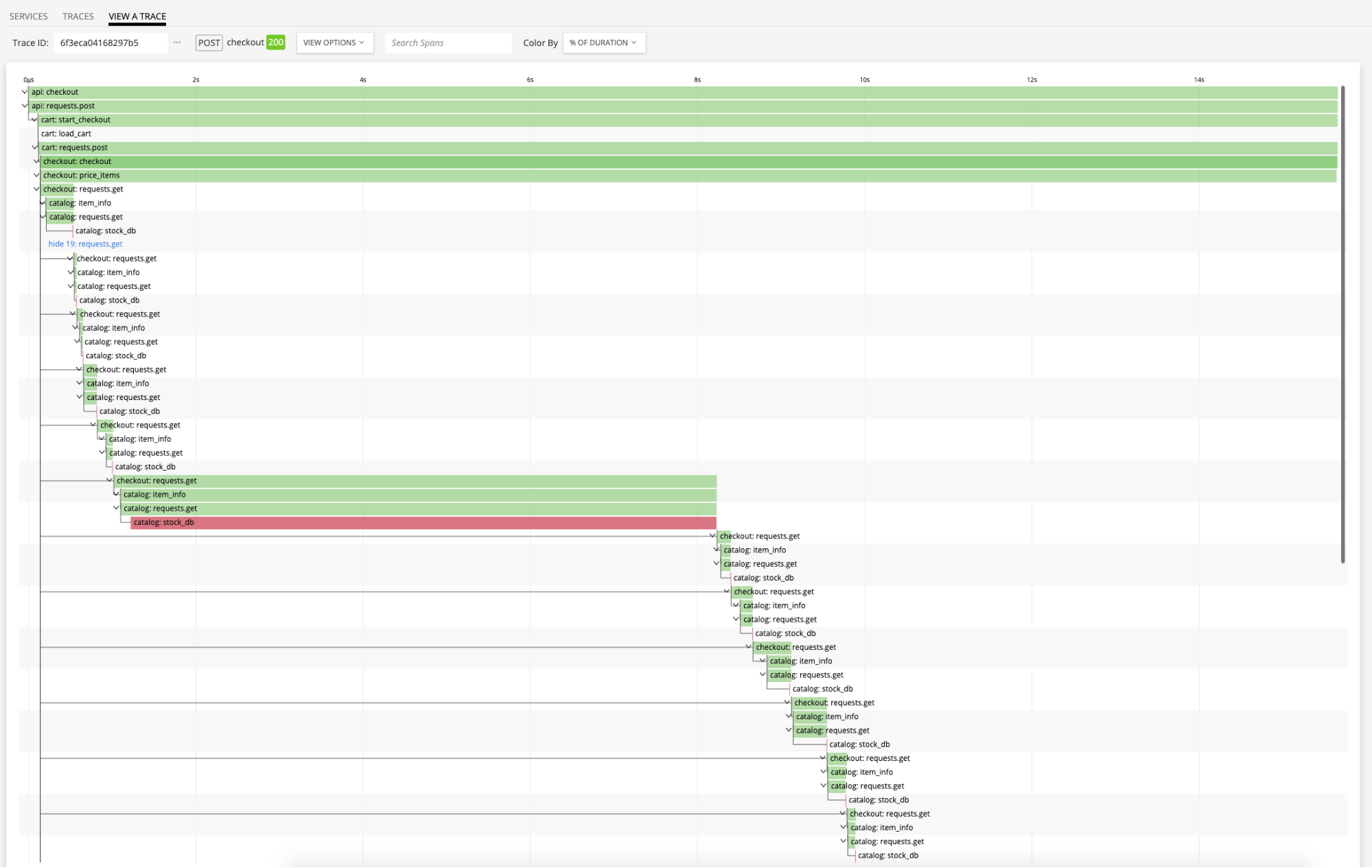
From there you can go into Trace Navigator to further understand a particular trace, and immediately highlight which spans are contributing most to request latency or errors. You can also view metrics generated from spans by the Smart Gateway for historical analysis of how a particular trace is performing.
As serverless computing continues to grow in popularity, it’s essential to have a monitoring platform that can provide truly real-time visibility into services like AWS Lambda. We’re incredibly excited by how our customers are applying this technology and committed to supporting them in this area.
If you’re not already using Splunk Infrastructure Monitoring, get started with a 14-day trial.
Thanks,
Aaron Sun

The Splunk platform removes the barriers between data and action, empowering observability, IT and security teams to ensure their organizations are secure, resilient and innovative.
Founded in 2003, Splunk is a global company — with over 7,500 employees, Splunkers have received over 1,020 patents to date and availability in 21 regions around the world — and offers an open, extensible data platform that supports shared data across any environment so that all teams in an organization can get end-to-end visibility, with context, for every interaction and business process. Build a strong data foundation with Splunk.

Get the latest articles from Splunk straight to your inbox.
© 2005 - 2024 Splunk Inc. All rights reserved.
