
Digital Resilience Pays Off
Download this e-book to learn about the role of Digital Resilience across enterprises.

This is Part 2 of a two-part series on new features and add-ons included in the Splunk Machine Learning Toolkit 4.0.
You can view Part 1 here.
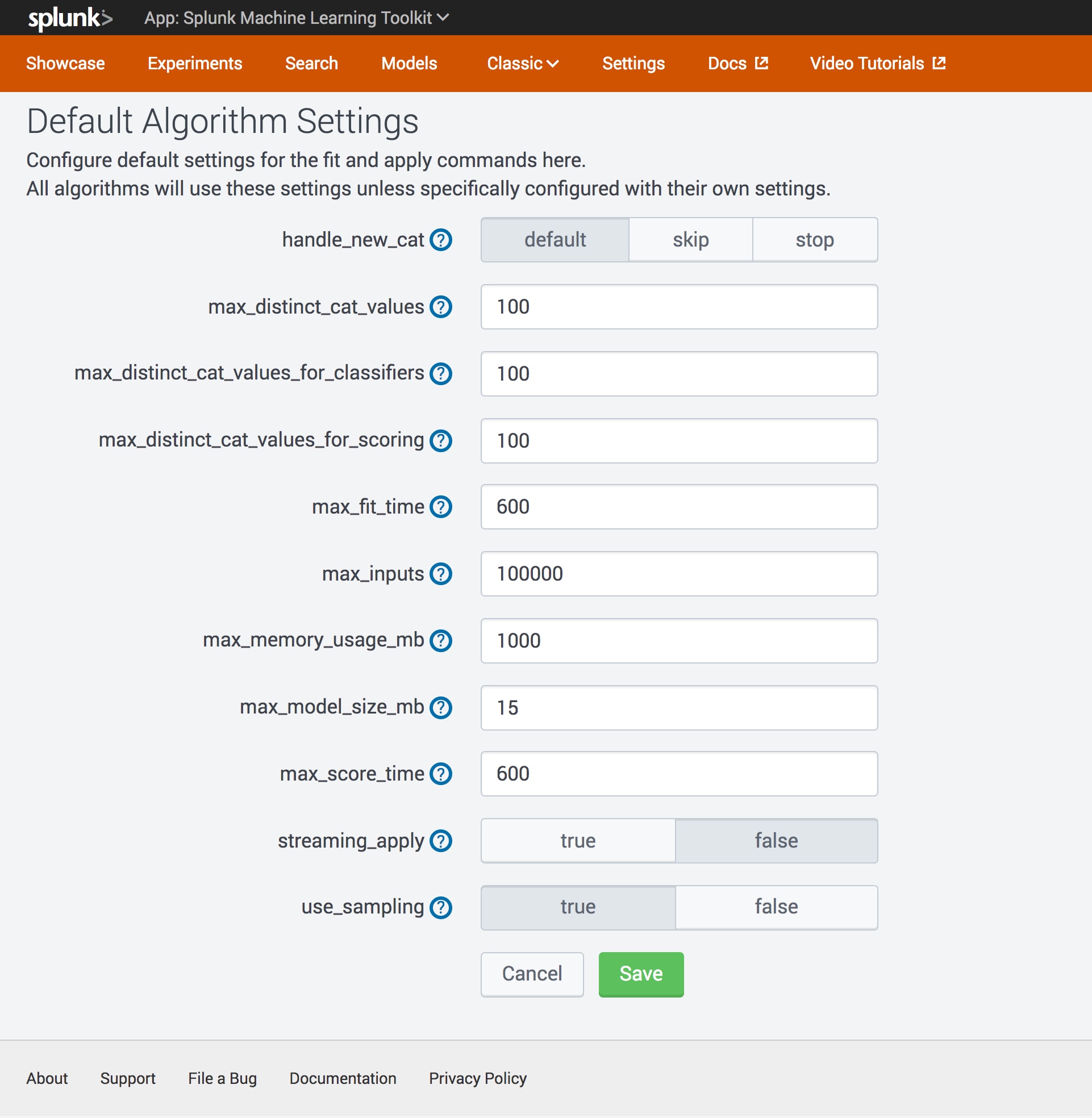
The Machine Learning Toolkit provides guard rails in the default download to prevent curious customers from taking down their production systems while exploring machine learning. The default configuration files in MLTK contain conservative settings, in order to restrain potential large ML workflows being used in production instances without administration intent . Better safe than sorry, eh? A Splunk administrator can change the default settings for production use of machine learning by directly editing the mlspl.conf file.
Editing config files? That’s so yesterday. In version 4.0, there is a UI for the user to inspect their MLTK settings. A user with admin access can also change the settings via the UI, followed by a Splunk reboot which is optional.
Note: For making changes to the MLTK’s mlspl.conf on Splunk Cloud, submit a case to Splunk Cloud Support.
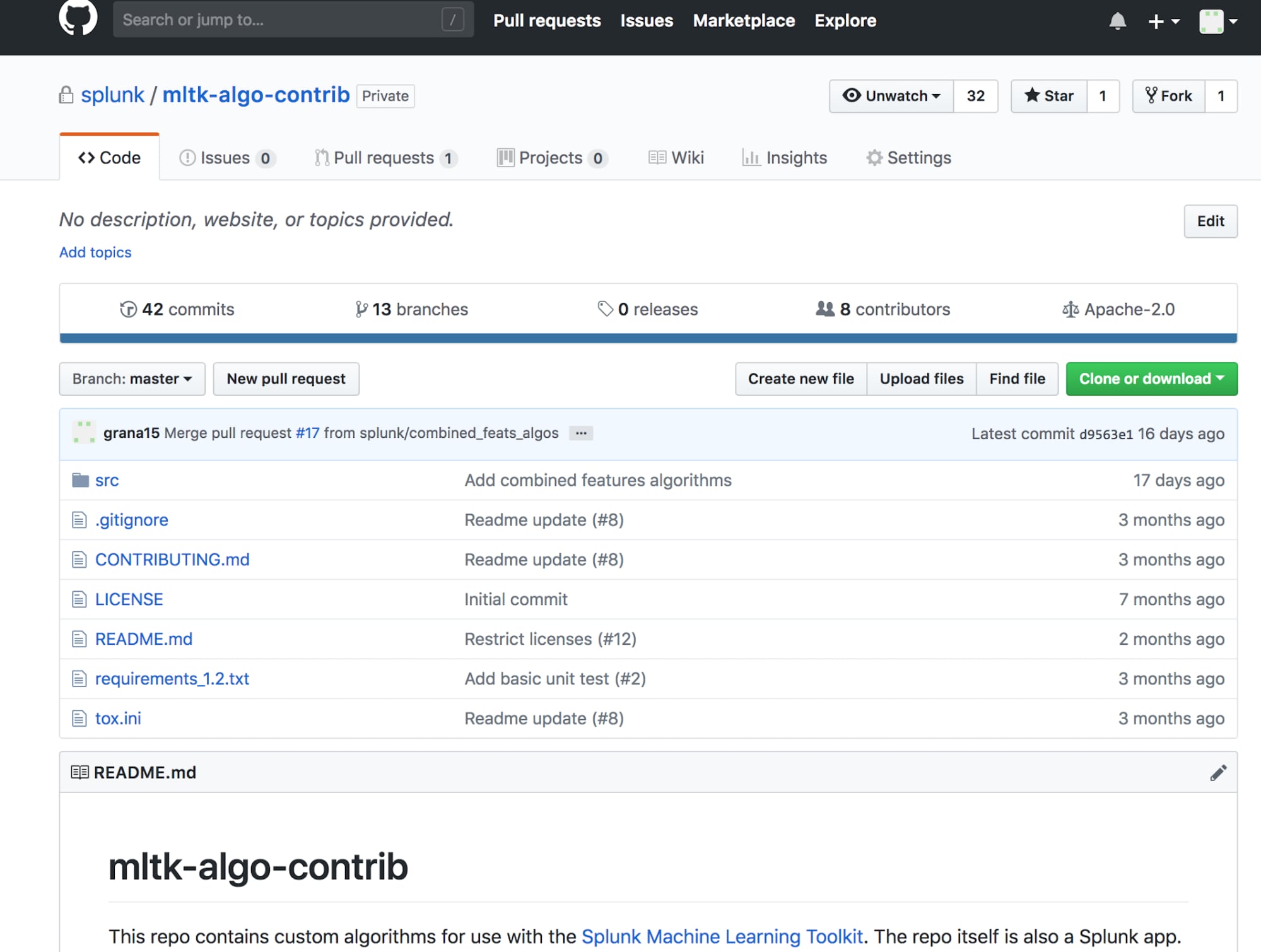
Have you been importing all those sweet algorithms into MLTK, but didn’t know how to share them with the rest of the community? Are you short on time for adding that extra algorithm you need for your use case? Are you interested to know what other Splunkers are doing with MLTK? Check out our Open Source community on Github that lets you share your algorithms with the community of Splunk MLTK users or import one of the algorithms that have been shared by the community: mltk-algo-contrib.
How can I get access to this community?
The readme file contains details on accessing and using the GitHub repo. One cool thing about the algorithms on this community repository is that all custom algorithms are based on the ML-SPL API, so you don’t need to think about the integration part, at all. Read the ML-SPL API documentation to learn more about how to add custom machine learning algorithms.
“The creation of the Splunk Community for MLTK Algorithms on GitHub will help us leverage new algorithms from the vibrant Splunk community thus increasing the value we extract from Splunk. It will also help grow and broaden the MLTK algorithm coverage much faster. Using MLTK models, we’ve automated several investigations and alerting decisions that are saving valuable time for our security analysts in the SOC.” —Nathan Worsham, IS Security Administrator, Pinnacol
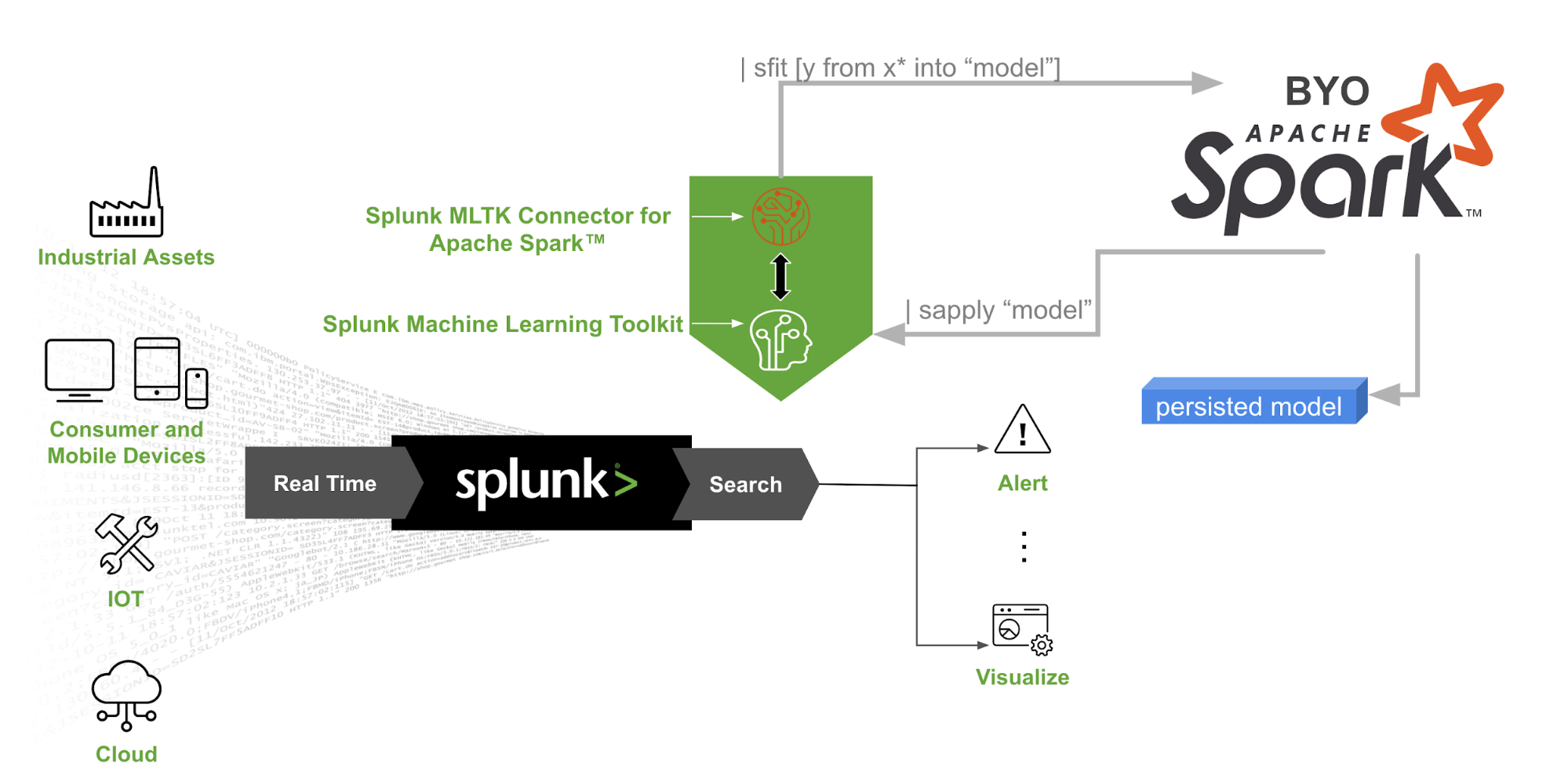
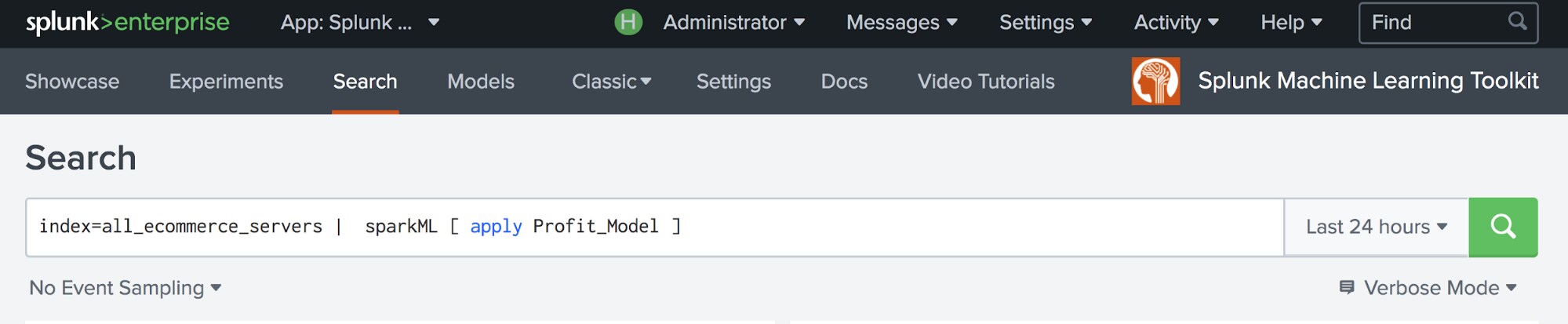
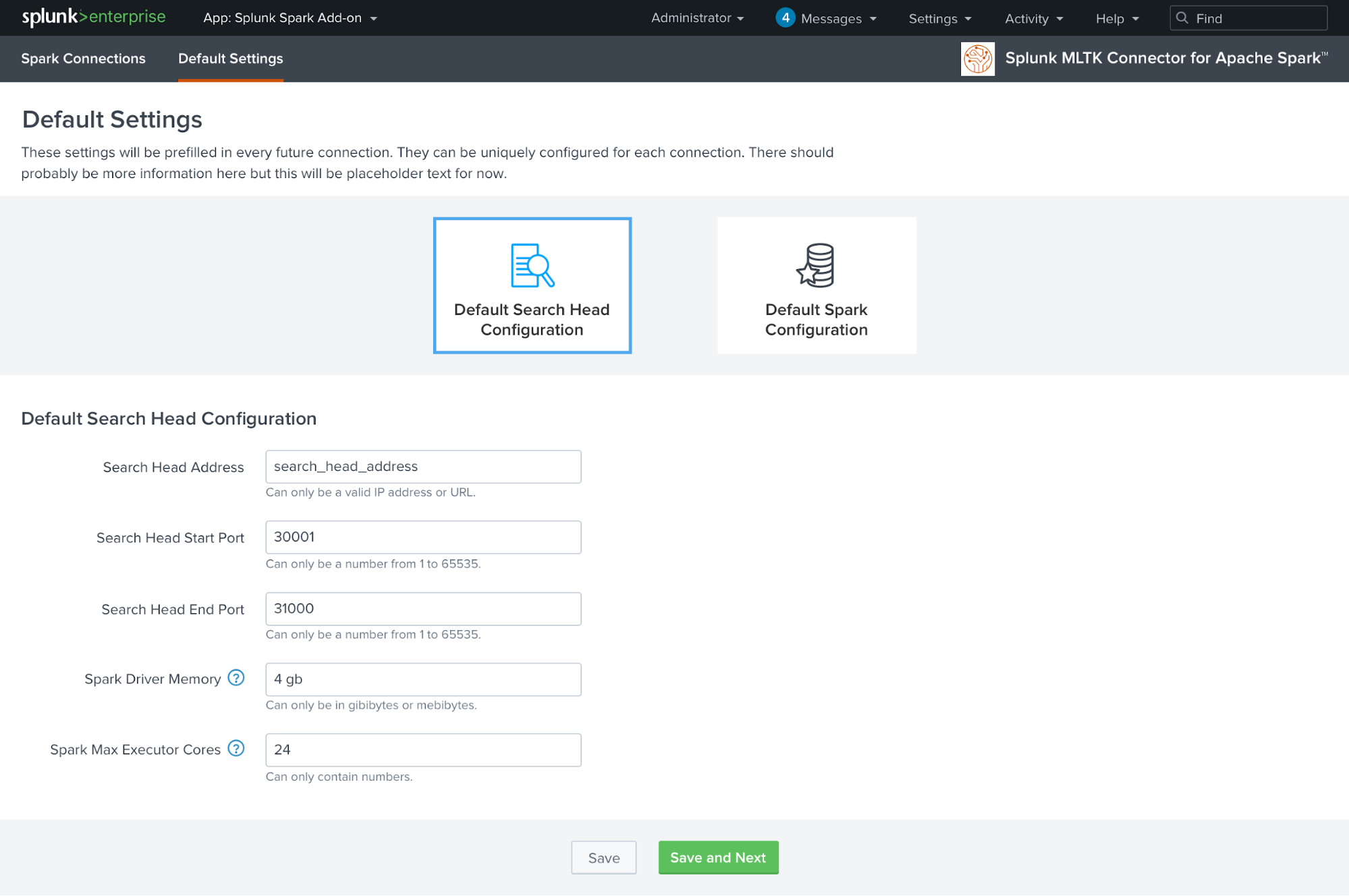
Do you have an Apache Spark™ cluster and dreams of building models using MLlib algorithms from the Splunk search bar? Are you looking to build huge machine learning models beyond the capacity of your Splunk infrastructure? Your dream has come true! The Splunk MLTK Connector for Apache Spark™ makes it possible to leverage your own Spark clusters for large distributed machine learning training jobs. You can now train a model using algorithms from Spark MLlib on your data inside Splunk and operationalize those models seamlessly in your Splunk workflows.
This is a Limited Availability release of this new add-on. To get access to the release, please contact us at sparkml@splunk.com.
Why do I need this?
Splunk MLTK Connector for Apache Spark™ provides you with an additional machine learning library, MLlib. Spark MLlib’s distributed machine learning library makes building large scale models easy and leverages your Spark cluster infrastructure investments. The beauty is that you don’t need to write any actual code other than good old SPL.
This add-on comes with a UI wizard to make configuration and testing of the connection to the standalone Spark cluster easier.
Deep learning algorithms have become hot for obvious reasons. Deep Networks are inherently powerful and have made tremendous progress on many hard machine learning problems.
TensorFlow™ is a popular open source ML framework from Google, focused on Deep Learning workloads. With the new Splunk MLTK Container for TensorFlow™ add-on, you can now |fit and |apply neural network models on your Splunk data using SPL. And the best part is that you can use multiple CPUs or GPUs for accelerating your training jobs. Yes, we said GPUs - you’ll be able to take advantage of all that GPU infrastructure you’ve got in your organization.
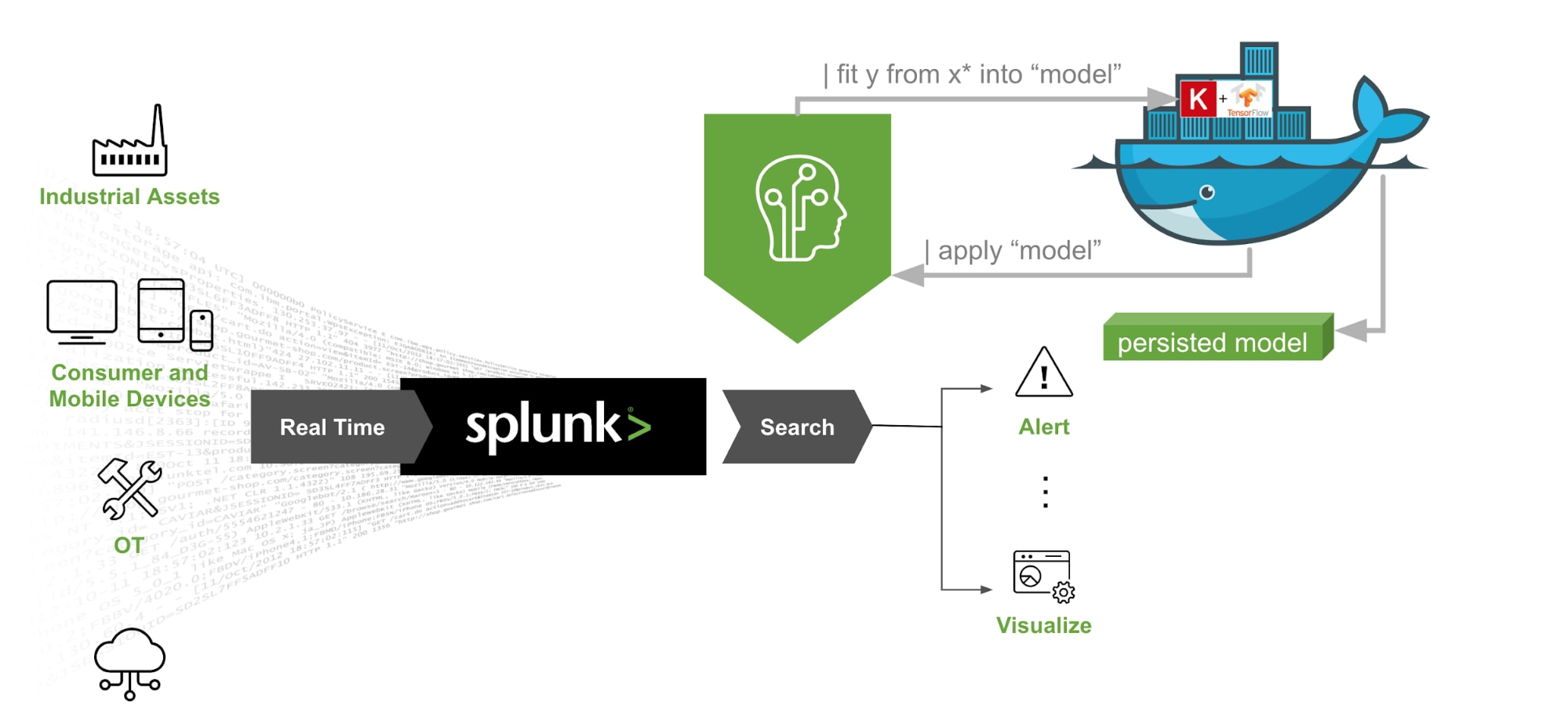
Please note that this add-on is only available through Professional Services. If you want to know more about it, please reach out to your Splunk representative.
“For our specific modelling in Python, our data scientists want to tap into modern machine learning frameworks like TensorFlow. This is extremely valuable as it allows us to explore various deep learning approaches using data in our Splunk environment. Connecting to custom Python code and libraries including Tensorflow makes it a lot easier for us to extract value and insights from our data in Splunk versus taking data out of Splunk for custom analytics. This makes Splunk our go-to platform for new machine data use-cases." Andreas Zientek, Systems Engineer, Zeppelin.
For an in-depth look at how to use the MLTK, check out these webinars:
Getting Started with Machine Learning
Splunk's Machine Learning Toolkit: Technical Deep Dive and Demo Part 1
Splunk's Machine Learning Toolkit: Technical Deep Dive and Demo Part 2
Machine Learning in Action: Stop IT Events Before They Become Outages
Learn how Splunk customers are using the Machine Learning Toolkit to generate benefits for their organizations, including Hyatt, the University of Nevada, Las Vegas (UNLV), and Transunion.
Interested in getting help from Splunk ML Engineering and Data Scientists on getting Machine Learning Toolkit deployed against production models in your organization? Learn more about the popular Machine Learning Customer Advisory Program that was leveraged by some of the customers referenced above.
Follow all the conversations coming out of #splunkconf18!
----------------------------------------------------
Thanks!
Manish Sainani

The Splunk platform removes the barriers between data and action, empowering observability, IT and security teams to ensure their organizations are secure, resilient and innovative.
Founded in 2003, Splunk is a global company — with over 7,500 employees, Splunkers have received over 1,020 patents to date and availability in 21 regions around the world — and offers an open, extensible data platform that supports shared data across any environment so that all teams in an organization can get end-to-end visibility, with context, for every interaction and business process. Build a strong data foundation with Splunk.

Get the latest articles from Splunk straight to your inbox.
© 2005 - 2024 Splunk Inc. All rights reserved.
