
Digital Resilience Pays Off
Download this e-book to learn about the role of Digital Resilience across enterprises.
Hi, everyone — this is my first Splunk Blogs post. Pretty cool! This may be a bit “out there” from a Splunk use case perspective, but I like to post about unique items I feel may be useful to others...so here it goes.
 Over the past 24 months or so, I have been studying investing/trading while also working to become more proficient with Splunk. I like to combine activities and gain momentum, so I decided stock market and economic data would be the perfect way to dig deeper into Splunk and hopefully improve my investing/trading. In the beginning, I only looked at it as a way to learn more about Splunk while using data that was interesting to me. However, as I dug in, I found that the Splunk ecosystem and world of quantitative finance have a lot of similarities. The primary ones being lots of data, Python and machine learning.
Over the past 24 months or so, I have been studying investing/trading while also working to become more proficient with Splunk. I like to combine activities and gain momentum, so I decided stock market and economic data would be the perfect way to dig deeper into Splunk and hopefully improve my investing/trading. In the beginning, I only looked at it as a way to learn more about Splunk while using data that was interesting to me. However, as I dug in, I found that the Splunk ecosystem and world of quantitative finance have a lot of similarities. The primary ones being lots of data, Python and machine learning.
In the world of quantitative finance, Python is very widely used. In fact, Pandas, a commonly used Python library was created in a hedge fund. The Python libraries used in quantitative finance are substantially the same libraries provided in the Python for Scientific Computing Splunk App. Additionally, much of the financial and market data provided by free and pay sources is easily accessible via REST API. Splunk also provides the HTTP Event Collector (HEC), which is a very easy to use REST endpoint for sending data to Splunk. This makes it relatively easy to collect data from web API’s and send it to Splunk.
When starting to do trading research, I found there were various places to get market and economic data. Places like the Federal Reserve (FRED), the exchanges, the census, the bureau of economic analysis, etc. In the end I found I could get most of the core data I wanted from three places:
The sources are endless and only limited by your imagination, and your wallet, as some data is very expensive. The main data most people will start with is end of day stock quote data and fundamental financial data. This is exactly what I get from quandl and gurufocus, as well as the macroeconomic data from FRED. There are lots of ways to get data into Splunk, but my preference in this case was to use Python code and interact with the internet REST API’s, Splunk REST API’s and HEC. This allows me to have Python scripts control all of my data loads and configuration in Splunk. Splunk also provides an extensible app development platform, which can be used to build add-ons for data input. I will likely move my data load processes to this model in the future.
![]() The other aspect that Splunk brings is the ability to integrate custom Python code via the Machine Learning Toolkit (MLTK) as custom algorithms. This provides the ability to implement analysis, such as concepts from modern portfolio theory for risk optimization and return projection. Additionally, this gives us a path to do more advanced things using the MLTK. I have only scratched the surface on this subject and I have lots of ideas to explore and learn in the future. Splunk simplifies operationalizing these processes and in my opinion makes the task of getting from raw data to usable information much easier.
The other aspect that Splunk brings is the ability to integrate custom Python code via the Machine Learning Toolkit (MLTK) as custom algorithms. This provides the ability to implement analysis, such as concepts from modern portfolio theory for risk optimization and return projection. Additionally, this gives us a path to do more advanced things using the MLTK. I have only scratched the surface on this subject and I have lots of ideas to explore and learn in the future. Splunk simplifies operationalizing these processes and in my opinion makes the task of getting from raw data to usable information much easier.
Ok, hopefully that provides enough background and context. Now I would like to show an example of the following process.
The following code sample shows a simplified version of code used to retrieve data from the Quandl Quotemedia end-of-day data source. The returned data is formatted and sent to a Splunk metrics index. Splunk metrics were created to provide a high performance storage mechanism for metrics data. Learn more about Splunk metrics here and here.
### Get Quandl Data
start_date = "2000-01-01"
end_date = "2019-10-01"
quandl_api_key = "XXXXXXXXX"
quandl_source = "EOD"
quandl_code = "AAPL"
source_host = "QUANDL"
splunk_host = "splunk.lab.local"
url = "https://www.quandl.com/api/v3/datasets/%s/%s.json?start_date=%s&end_date=%s&api_key=%s" % (
quandl_source, quandl_code, start_date, end_date, quandl_api_key)
response = requests.get(url)
quandl_data = response.json()
### Prep Quandl Data for Splunk Metrics Index and Send to Splunk
# loop through result data fields and build python dictionary
for rc in result['dataset']['data']:
quandl_metric_data = {}
colcount = len(result['dataset']['column_names'])
for x in range(0,colcount):
quandl_metric_data[quandl_data['dataset']['column_names'][x]] = rc[x]
event_date = rc['Date']
# Create metric dimensions
quandl_metric_data['QuandlSource'] = quandl_source
quandl_metric_data['QuandlCode'] = quandl_code
# Build porperly formatted event with JSON data payload
event_time = int(time.mktime(time.strptime(str(event_date), "%Y-%m-%d")))
event_data = {
"QuandlSource": quandl_source,
"QuandlCode": quandl_code,
"metric_name": metric_name.decode(),
"_value": metric_value
}
post_data = {
"time": event_time,
"host": source_host,
"source": "quandl",
"event": "metric",
"fields": event_data
}
### Send Quandl Data to Splunk HTTP Event Collector
request_url = "http://%s:8088/services/collector" % splunk_host
data = json.dumps(post_data).encode('utf8')
splunk_auth_header = "Splunk %s" % splunk_auth_token
headers = {'Authorization': splunk_auth_header}
response = requests.post(request_url, data=data, headers=headers, verify=False)
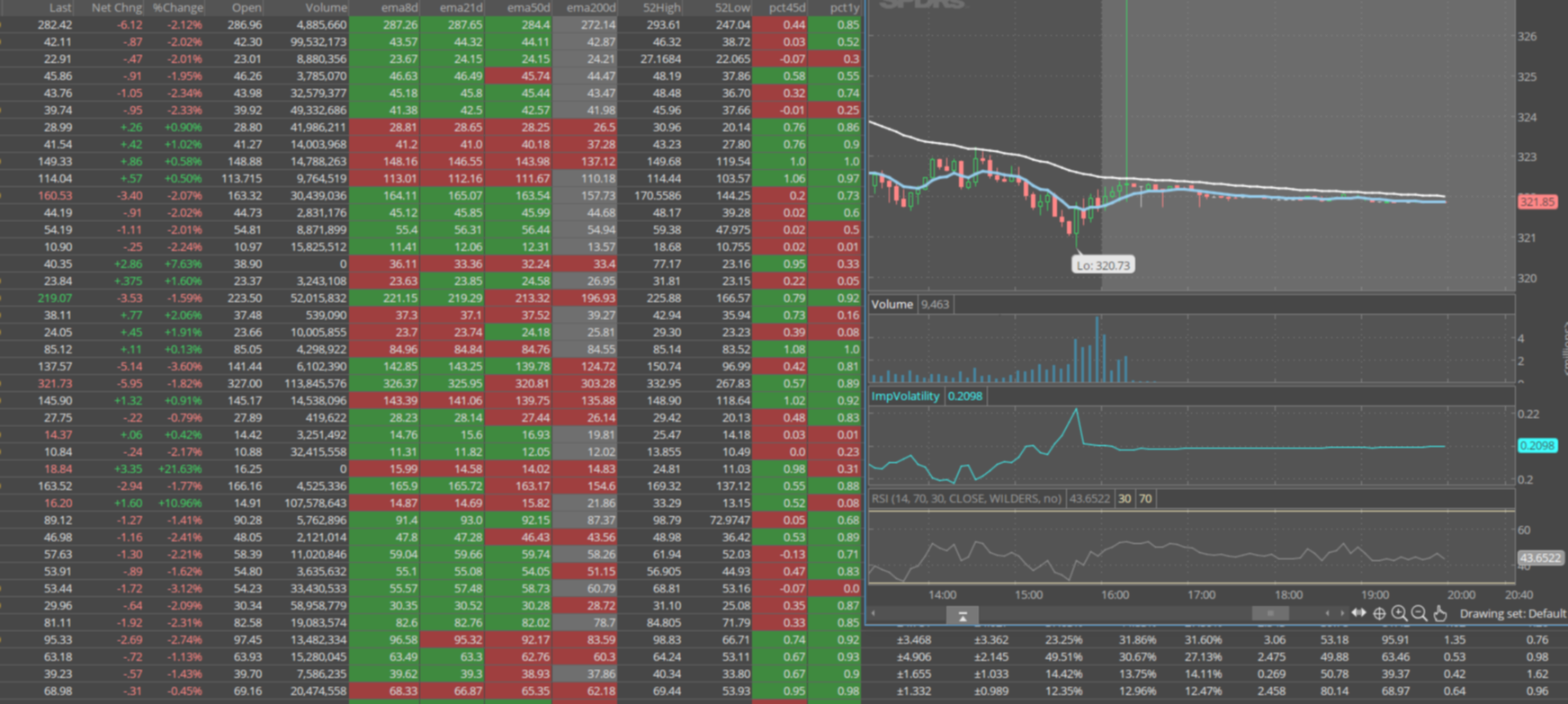
Once the quote data is loaded then we can see all of the metrics loaded by the process. The following screenshot shows our resulting indexed data.
| mstats avg(_value) prestats=true WHERE metric_name="*" AND index="quandl_metrics" AND QuandlCode IN (AAPL) span=1d BY QuandlCode
| chart avg(_value) BY _time metric_name limit=0
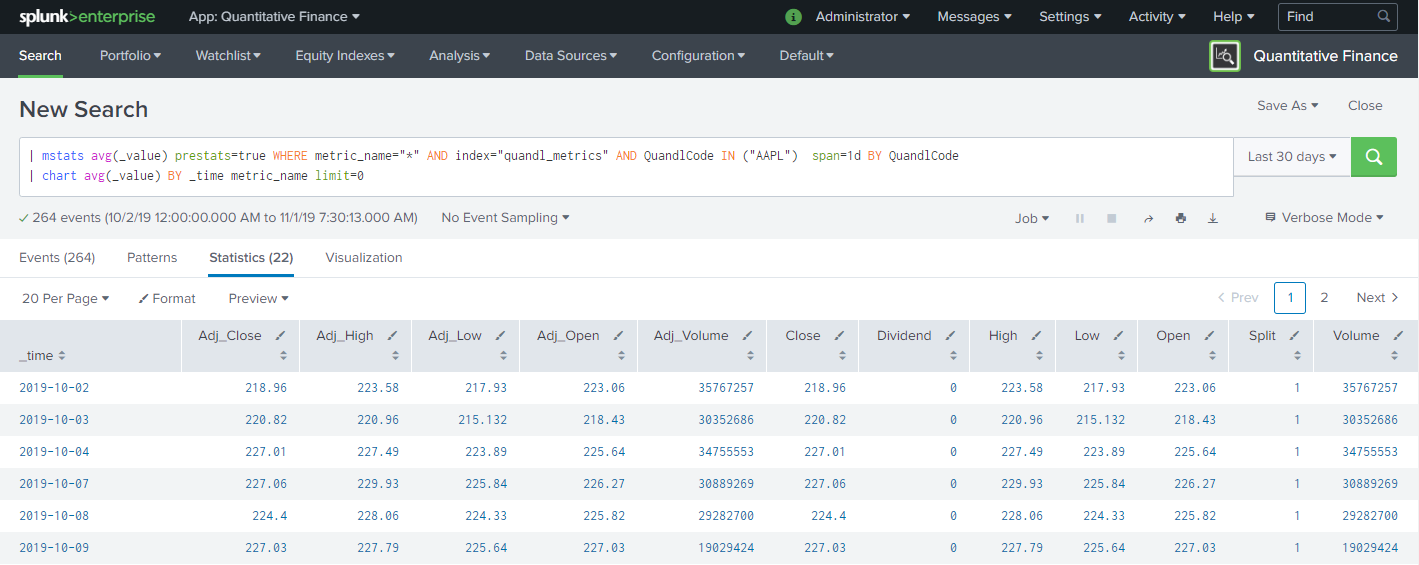
Now that we have our data loaded we can do some more advanced processing. A common fundamental calculation done in quantitative finance using modern portfolio theory is to calculate daily returns. The following example shows how to use the metrics data loaded into Splunk for this calculation. For this example I have loaded data for various S&P 500 sector ETF’s as well as a gold miners ETF. Here is the calculation and results.
| mstats avg(_value) prestats=true WHERE metric_name="Close" AND index="quandl_metrics" AND QuandlCode IN (GDX,XLC,XLE,XLF,XLI,XLK,XLP,XLV,XLY) span=1d BY QuandlCode
| chart avg(_value) BY _time QuandlCode limit=0
| streamstats current=f global=f window=1 last(*) as last_*
| foreach *
[ | eval <>_day_rt=log(exp(<> - last_<>))]
| fields *_day_rt
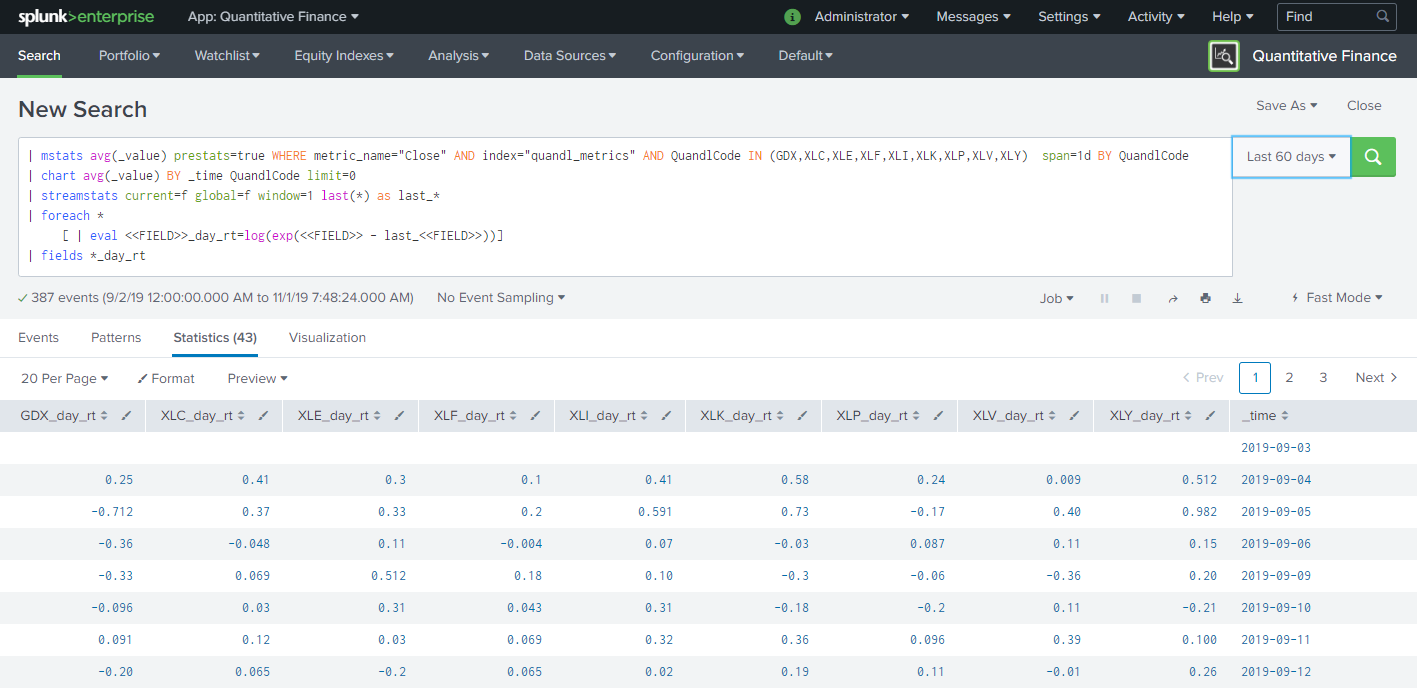
The next step in our process is to use the Splunk Machine Learning Toolkit to calculate correlation of our equities. The Python Pandas library has a function that makes this process very easy. We can access that functionality and easily operationalize that process in Splunk. It just so happens there is a Correlation Matrix algorithm in the GitHub Splunk MLTK algorithm contribution site available here. The documentation to add a custom algorithm can be found here and you will notice this Correlation Matrix example is highlighted. Here is the example of using this algorithm and the corresponding output.
| mstats avg(_value) prestats=true WHERE metric_name="Close" AND index="quandl_metrics" AND QuandlCode IN (GDX,XLC,XLE,XLF,XLI,XLK,XLP,XLV,XLY) span=1d BY QuandlCode
| chart avg(_value) BY _time QuandlCode limit=0
| streamstats current=f global=f window=1 last(*) as last_*
| foreach *
[ | eval <>_day_rt=log(exp(<> - last_<>))]
| fields *_day_rt
| fields - _time
| fit CorrelationMatrix *
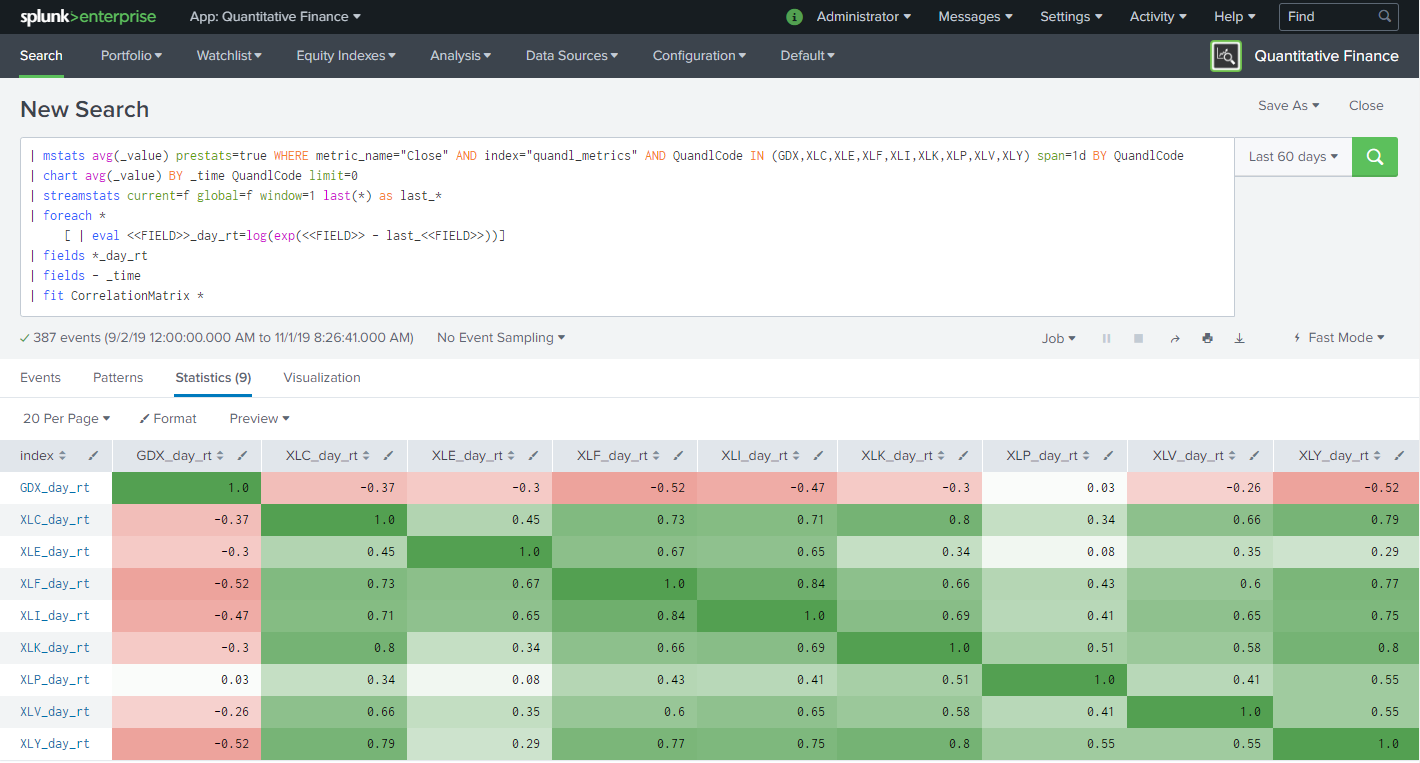
The example above shows the correlation of all of the examined ETF’s over a period of 60 days. The value of 1 is perfectly correlated and the value of -1 is perfectly inversely correlated. As noted previously this calculation is the basis for more advanced operations to determine theoretical portfolio risk and return. I hope to visit these in future posts.
Please let me know if you find this interesting!
Best Regards,
David
----------------------------------------------------
Thanks!
David Muegge

The Splunk platform removes the barriers between data and action, empowering observability, IT and security teams to ensure their organizations are secure, resilient and innovative.
Founded in 2003, Splunk is a global company — with over 7,500 employees, Splunkers have received over 1,020 patents to date and availability in 21 regions around the world — and offers an open, extensible data platform that supports shared data across any environment so that all teams in an organization can get end-to-end visibility, with context, for every interaction and business process. Build a strong data foundation with Splunk.

Get the latest articles from Splunk straight to your inbox.
© 2005 - 2024 Splunk Inc. All rights reserved.
