
Digital Resilience Pays Off
Download this e-book to learn about the role of Digital Resilience across enterprises.

We're excited to announce that the Splunk Machine Learning Toolkit (MLTK) version 5.2 is available for download today on Splunkbase! Earlier this month, I discussed how the release of version 5.2 will make machine learning more accessible to more users. Splunk’s MLTK lets our customers apply machine learning to the data they're already capturing in Splunk, develop models, and operationalize these algorithms to glean new insights and make more informed decisions. MLTK can be deployed on top of Splunk Enterprise or Splunk Cloud.
This version of the MLTK was purpose-built to hone in on common use cases such as forecasting, anomaly detection, and clustering. With step-by-step guided workflows provided by a new family of Smart Assistants, MLTK is bringing machine learning to more users and empowering a broader base of users. For instance, new Smart Assistants such as Smart Clustering and Smart Prediction were built to help “citizen data scientists” –that is, you don’t need to be a formally trained data scientist to run sophisticated analytics using your data. However, if you have a deeper background in ML, we have also incorporated some new, advanced capabilities for you in this release as well! Based on feedback from our customers and their use cases, MLTK 5.2 includes new and enhanced algorithms for you to utilize.
Regardless of your background or familiarity with machine learning, MLTK is here to help you. We’ve updated the user interface to provide guided workflows and our Smart Assistants will help you build a model and move through the stages of Define, Learn, Review, and Operationalize as you load your data, refine your model, and put that model into production. Plus, each stage of this journey has more support for metrics, allowing you to preview and visualize your data as you construct your dashboards in real-time.
Our family of “Smart” Assistants are bespoke workflows that map out the most common machine learning and data science tasks such as clustering, outlier detection, and prediction. For example, the Smart Prediction Assistant uses a new AutoPrediction algorithm to predict the value of categorical or numeric fields and automatically checks the target value type for these fields. The Smart Clustering Assistant, on the other hand, leverages a version of the K-means algorithm, which is computationally faster than most other clustering algorithms.
MLTK 5.2 also includes additional algorithms to use with Splunk Search Processing Language (SPL), which tells Splunk how to act on retrieved data. These new algorithms include the enhanced densityFunction algorithm that now supports partial fit for quick outlier detection, G-means for clustering, and a new custom visualization heatmap capability for showcasing machine learning (ML) model results. SPL is auto-generated for you as you work through the Smart Assistants.
To show you how easy it is to build a model with your Splunk data, I want to give you a glimpse into the Smart Clustering Assistant – that lets us find similarities across events in data sets. Traditionally, this task would have taken hours, but now, using the Smart Assistants and intuitive interface, we have reduced it to just a few clicks of a button.
Use the Define stage to select and preview the data you want to cluster. You can pull in data from anywhere in the Splunk platform – either data you have ingested into Splunk or any datasets that ship with Splunk Enterprise and the Machine Learning Toolkit.
Once data is selected, the Data Preview and Visualization tabs populate.
Once data is selected, use the Learn stage to build your clustering model. At this stage, you apply algorithms to the data to train a model. The Learn stage includes sections from which you can see the ingested data, add one or more data pre-processing steps, and pick the fields to cluster and number of clusters to generate.
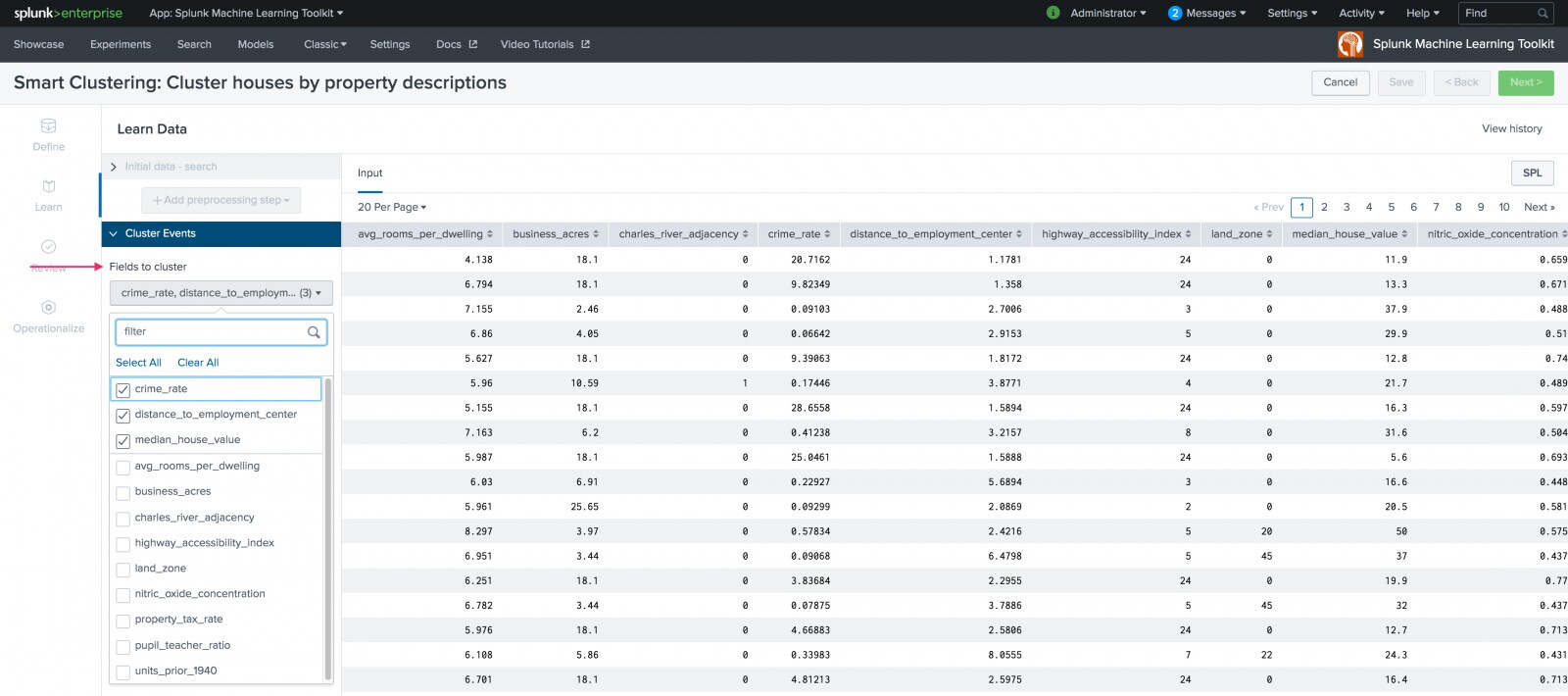
Input the number of clusters to generate and optionally use the Notes field to track parameter adjustments you make to your Smart Clustering Experiment or use View History.
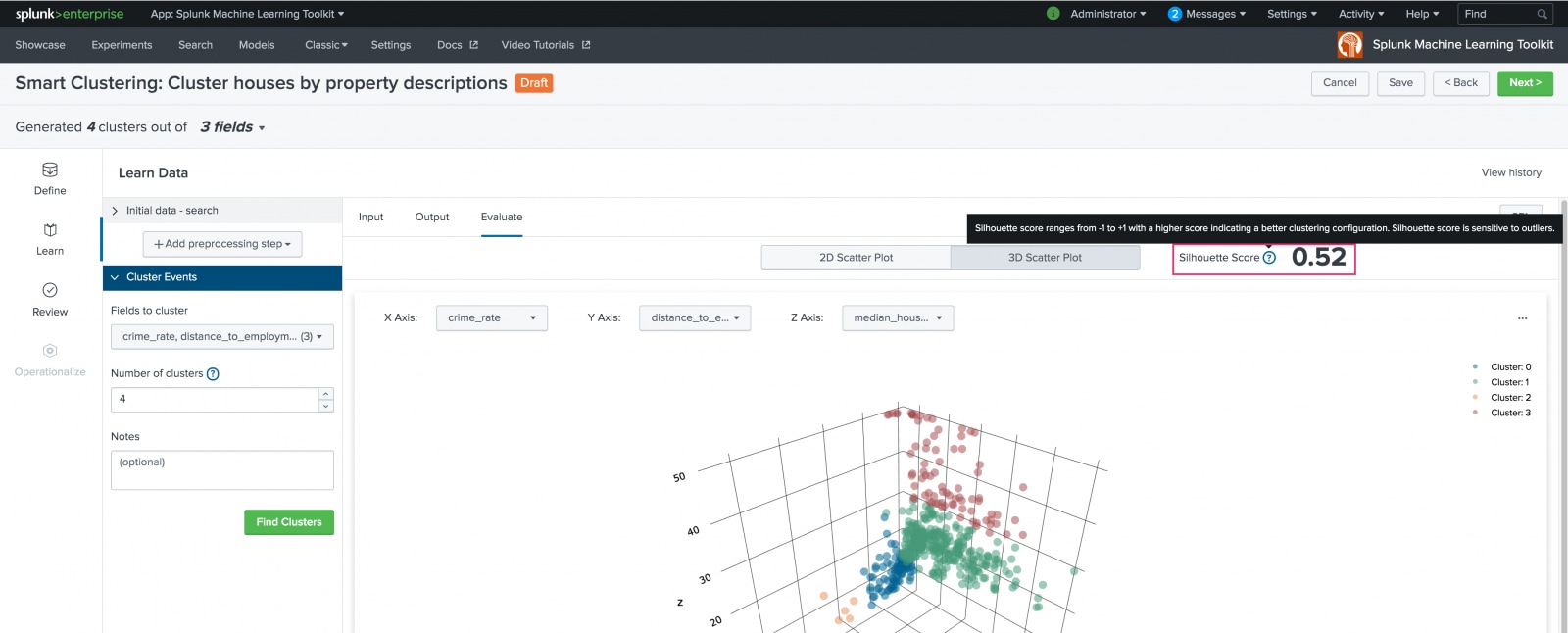
On the resulting Evaluate tab, view your settings in a 2D or 3D scatter plot. Use the X, Y, and Z axis drop-down list to populate the scatter plots.
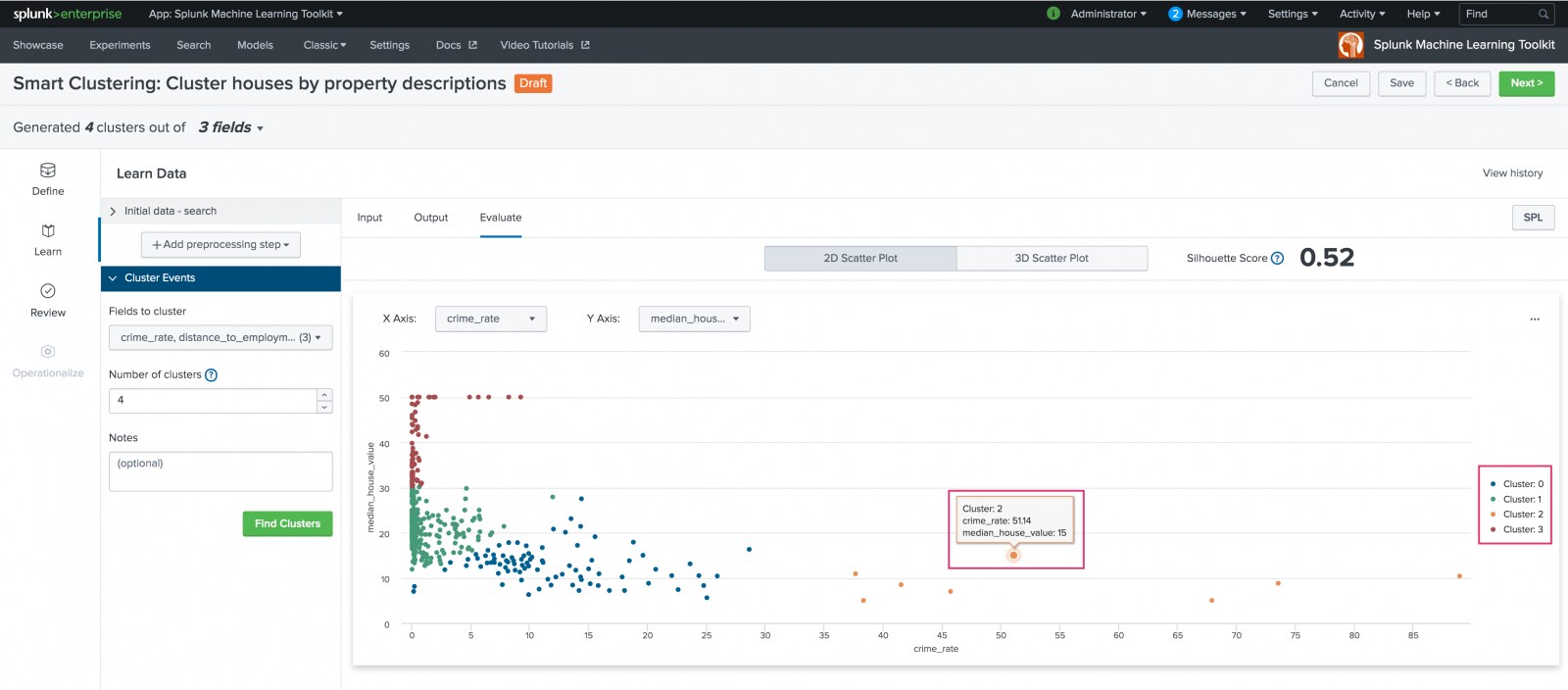
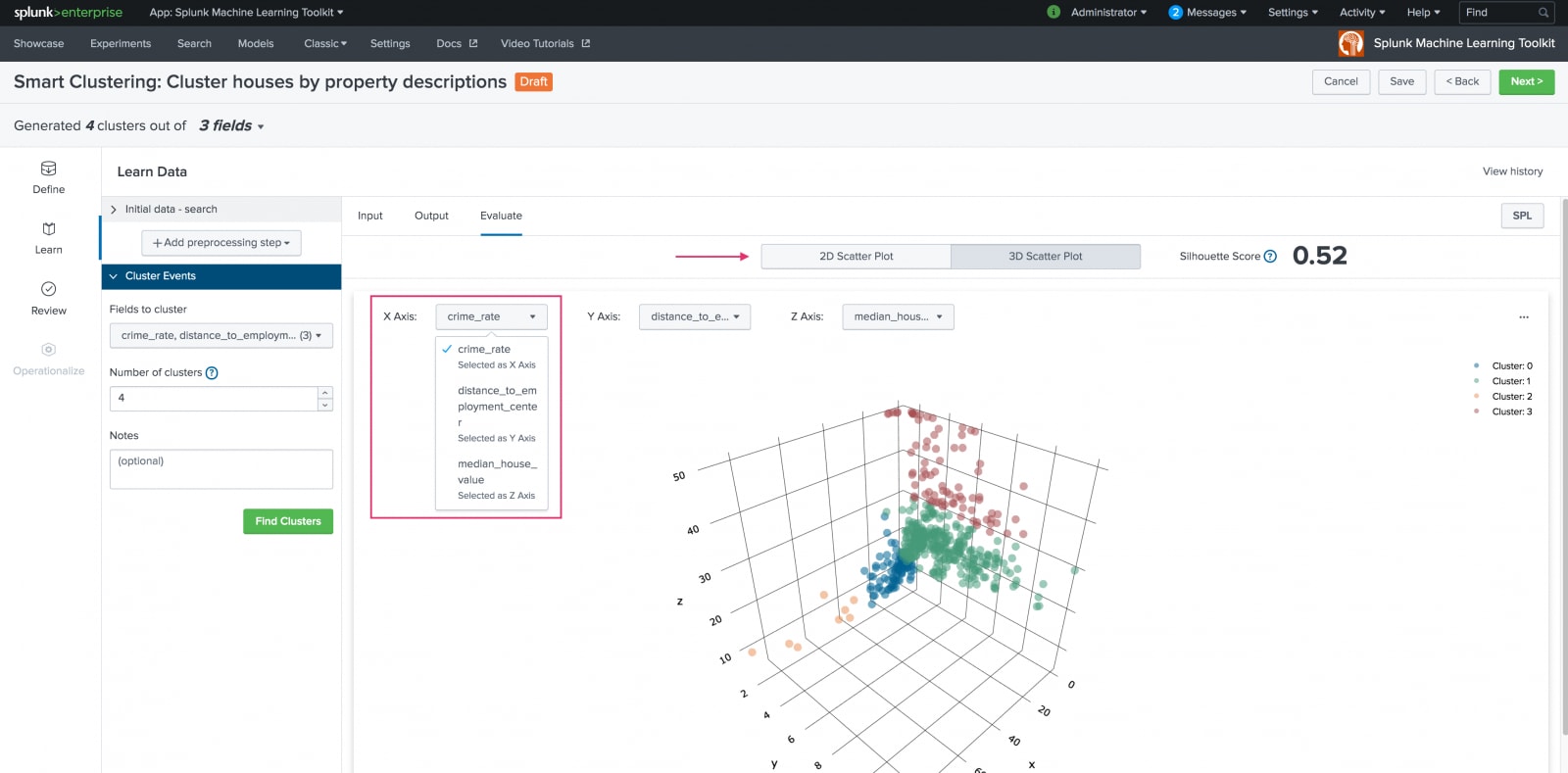
Clicking a specific data point opens a New Search screen for further data examination.
The Evaluate tab generates and displays the Silhouette score for the model. Silhouette scores measure both the distance from the cluster centroid and the distance between centroids. The Silhouette score ranges from -1 to +1 with a score closer to 1 indicating a better clustering configuration. A negative score could indicate you have selected the wrong fields to cluster.
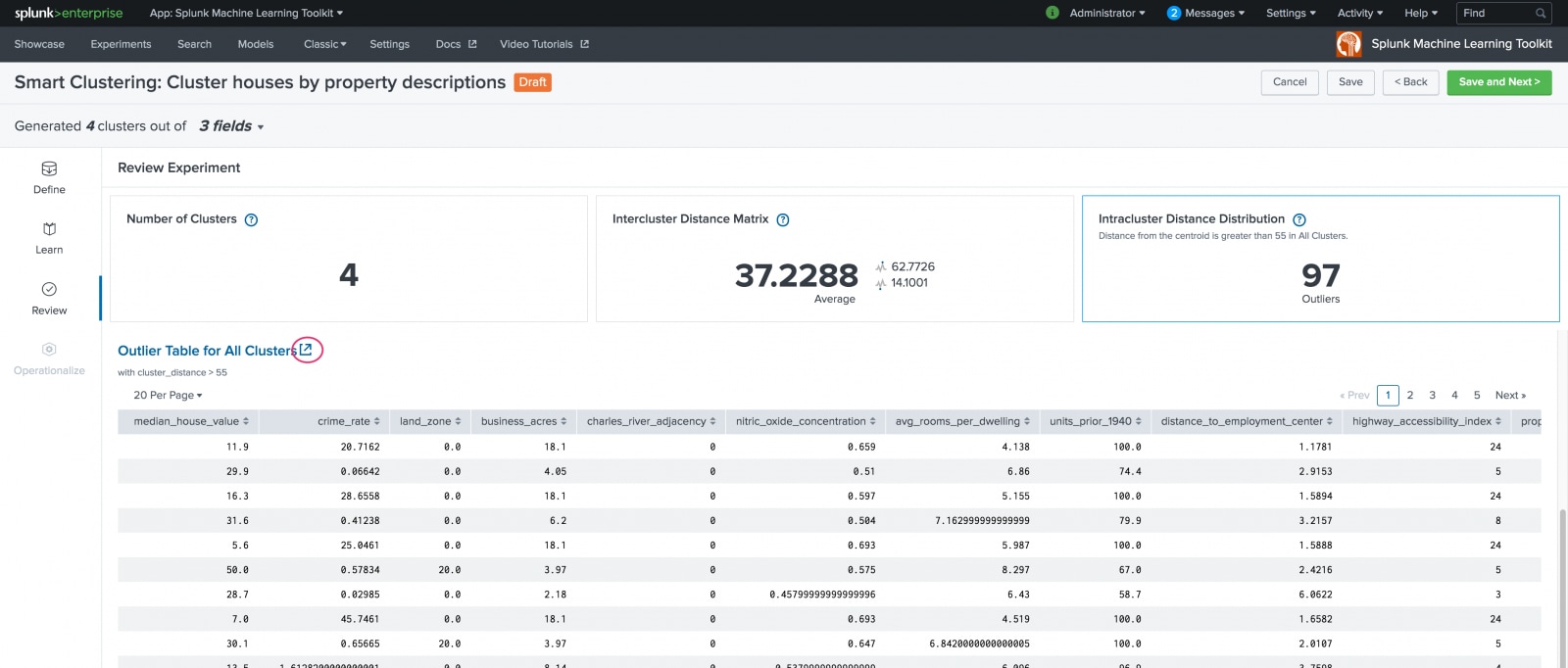
Use the Review stage to explore the resulting model and assess your clustering results prior to putting the model into production. There are three panels in this stage:
From here, scroll down to see the outliers identified in a table below.
In just a few short steps, we’ve shown you how we reduce hours of manual data science effort into an interactive, easy-to-configure workflow. And, without needing to update code, you can iteratively refine and experiment. While MLTK 5.2 was designed for simplicity, we’ve kept it comprehensive enough to address the needs of even the more sophisticated users.
Now that you have seen how easy it is to build a model using machine learning, download the latest release today and give it a try for yourself! MLTK version 5.2 is now available in Splunkbase.
Interested in trying out the Machine Learning Toolkit at your organization? Splunk offers FREE resources to help you get it up and running through the Machine Learning Customer Advisory Program.
If you are interested in learning more, you can access the MLTK User Guide here.
----------------------------------------------------
Thanks!
Mohan Rajagopalan

The Splunk platform removes the barriers between data and action, empowering observability, IT and security teams to ensure their organizations are secure, resilient and innovative.
Founded in 2003, Splunk is a global company — with over 7,500 employees, Splunkers have received over 1,020 patents to date and availability in 21 regions around the world — and offers an open, extensible data platform that supports shared data across any environment so that all teams in an organization can get end-to-end visibility, with context, for every interaction and business process. Build a strong data foundation with Splunk.

Get the latest articles from Splunk straight to your inbox.
© 2005 - 2024 Splunk Inc. All rights reserved.
