
Digital Resilience Pays Off
Download this e-book to learn about the role of Digital Resilience across enterprises.
With a turbulent year and 2020 coming to its end, I’d like to thank you for your continued interest in my blog posts. In my last .conf talks I received a lot of positive feedback combined with the ask to have more posts with such content, so thanks for motivating me and here we go! Recently, my colleague Dimitris wrote about how you can set up DLTK on a AWS GPU Instance. Luckily in this article, I want to provide you with three interesting new algorithmic approaches available with the latest version 3.4 of the Deep Learning Toolkit (DLTK) App for Splunk:
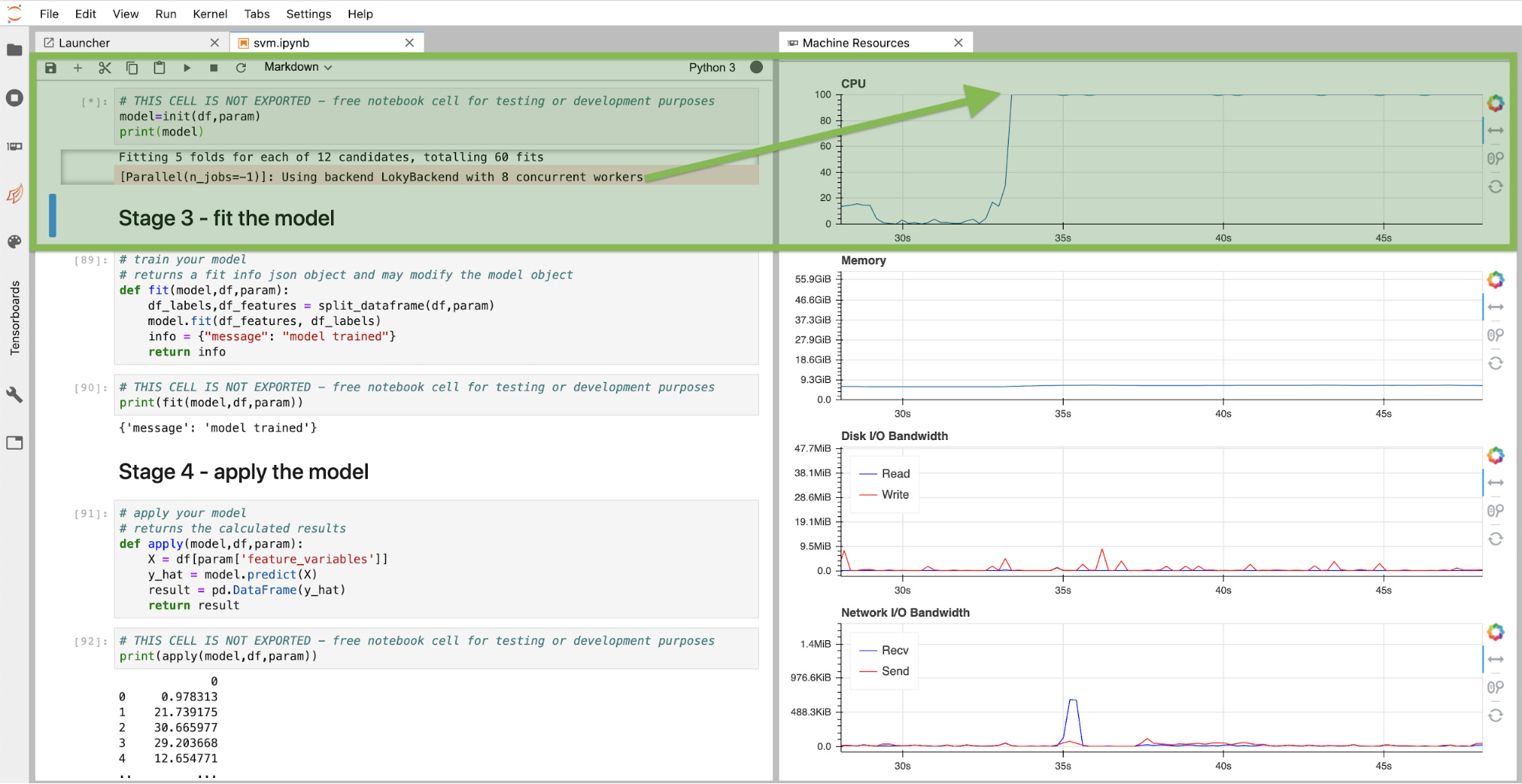
A frequently asked question by many customers working on machine learning models is how to find the best possible model and its parameters within given constraints. Hyperparameter optimization is the technical term for this process and can be achieved in different ways. One simple way is defining ranges on hyperparameters and train models for all combinations. Validating each model on the test data finally returns the model with the highest score and its hyperparameters. Voila, you found the best possible model. Needless to say, this can be a very compute intensive process which luckily can be parallelized on many CPU (or GPU) cores in most cases. Recently my colleague Phil Salm worked on such an example and we are happy to provide it with DLTK so you can use it straight away for your use cases or improving your models. You can run the grid search directly in DLTK’s Jupyter Lab Notebook as shown below. Note that on this instance we had 8 CPU cores available to run the grid search concurrently. As you can read from the machine resources monitor panels, the CPU is fully utilized.
You can further automate and directly call the grid search based algorithm implicitly from your Splunk search, have the best possible model trained, selected and applied to your data. In the screenshot below you see how prediction results are returned and scored on the example dashboard in DLTK:
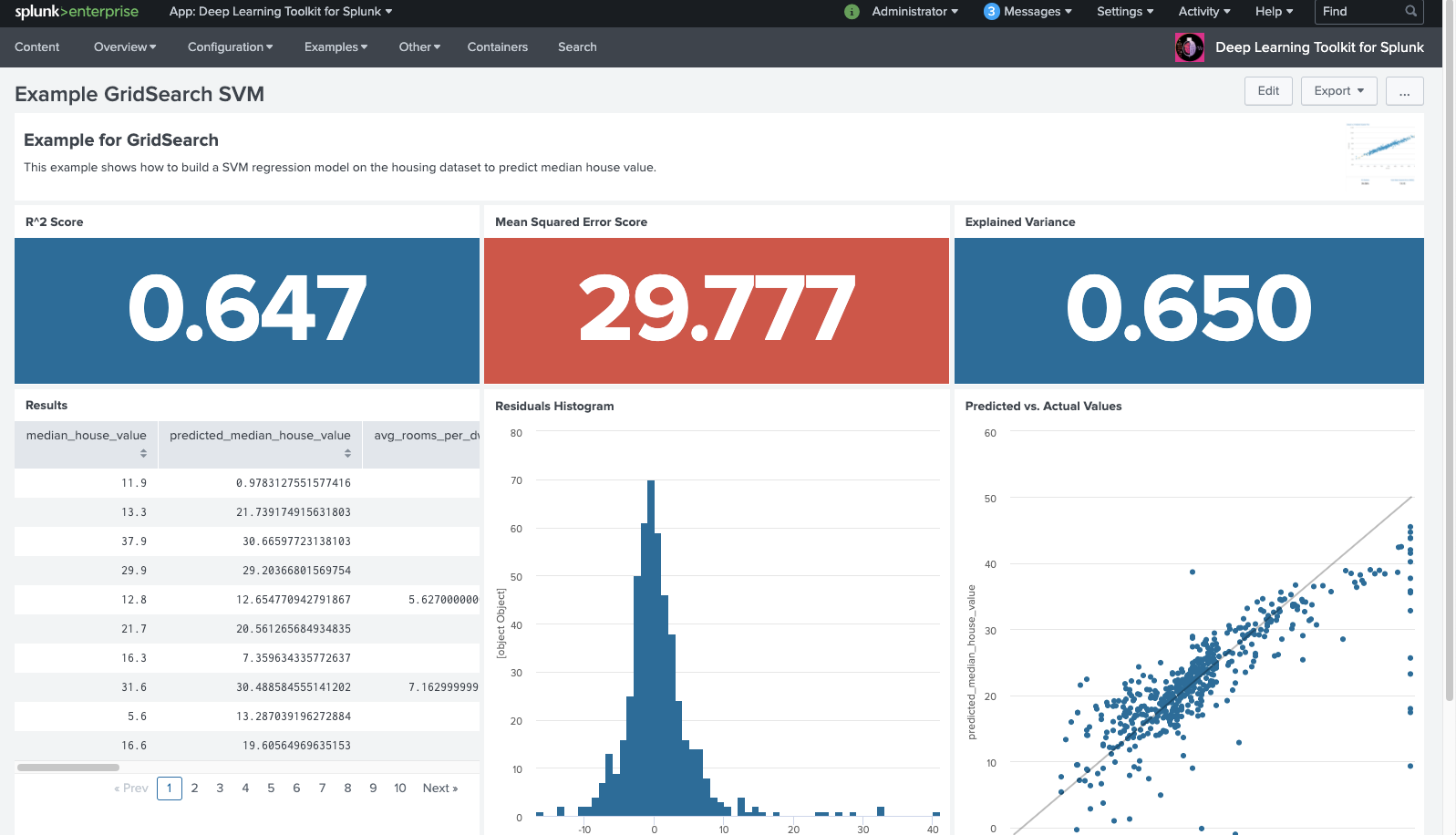
Of course, the concept of grid search does not only apply to a support vector machine, but can be easily extended to other algorithms from scikit learn or other machine learning frameworks. With this example notebook you should be able to adapt the concept to your modelling needs easily.
Recently, my colleague Greg Ainslie-Malik wrote the blog, "Causal Inference: Determining Influence in Messy Data," and gave a nice walkthrough on how you can setup and use the causalnex library published by QuantumBlack Labs in DLTK. As this algorithm can be fairly useful for many applications, it was a no-brainer to make Greg’s work available in DLTK with a combined Splunk dashboard and Jupyter Notebook example for easy reuse:
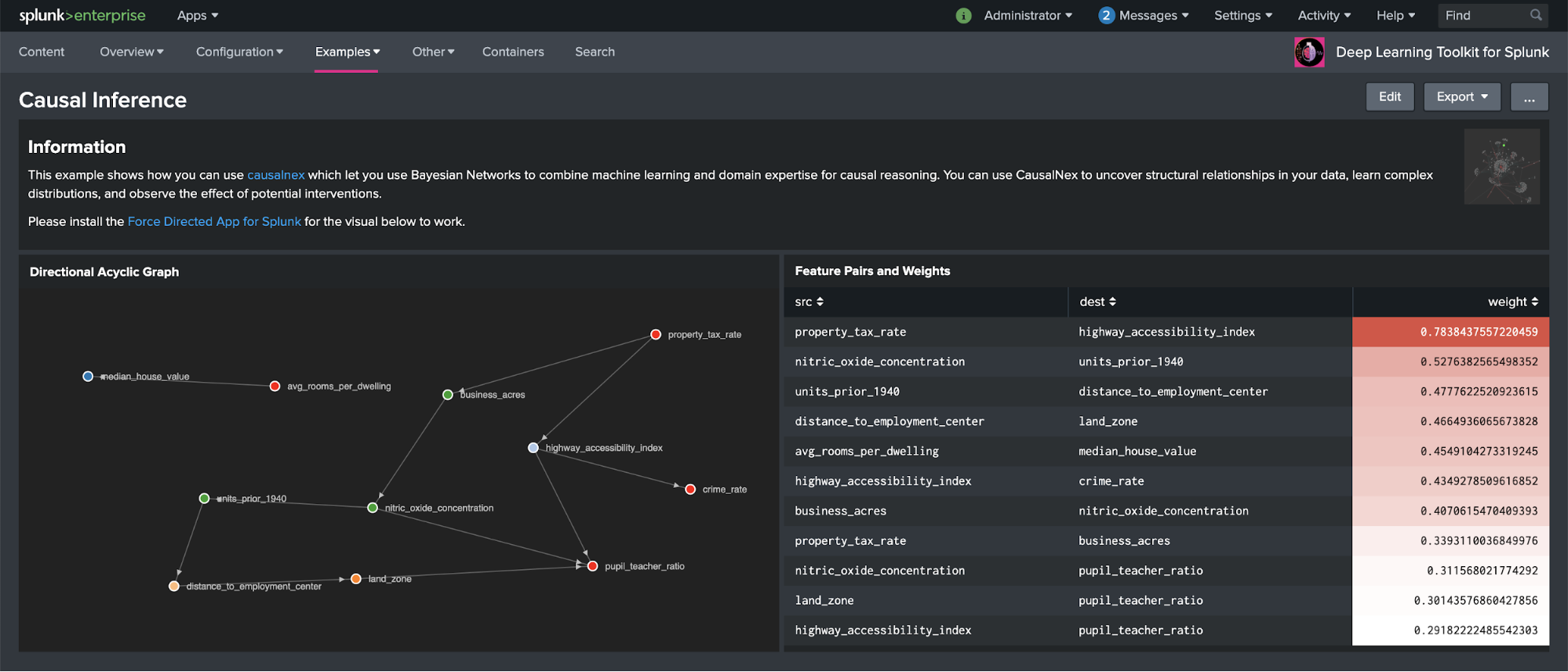
The example dashboard above shows how features in the housing dataset contained in the Splunk Machine Learning Toolkit are related with each other. The relationships are shown in a graph on the left panel and the weights of each feature pair on the right panel on the dashboard. With this example you should be able to easily apply this approach to any of your data by simply using the appropriate SPL query before running causalnex to discover interesting relationships. This can also come in handy when explainability of machine learning models matters and can add to other techniques like SHAP as recently discussed in my last blog post, "Deep Learning Toolkit 3.3 - Examples for Explainable AI and XGBoost."
Many Splunk customers have extensive collections of log data. This data can contain very valuable information about technical or business processes which produce these logs. Process mining helps to uncover and model those processes and makes them accessible for further analysis and investigations. The example below covers a complete workflow how you can use Splunk’s Search Processing Language (SPL) to retrieve relevant fields from raw data, combine it with process mining algorithms for process discovery and visualize the results on a dashboard:
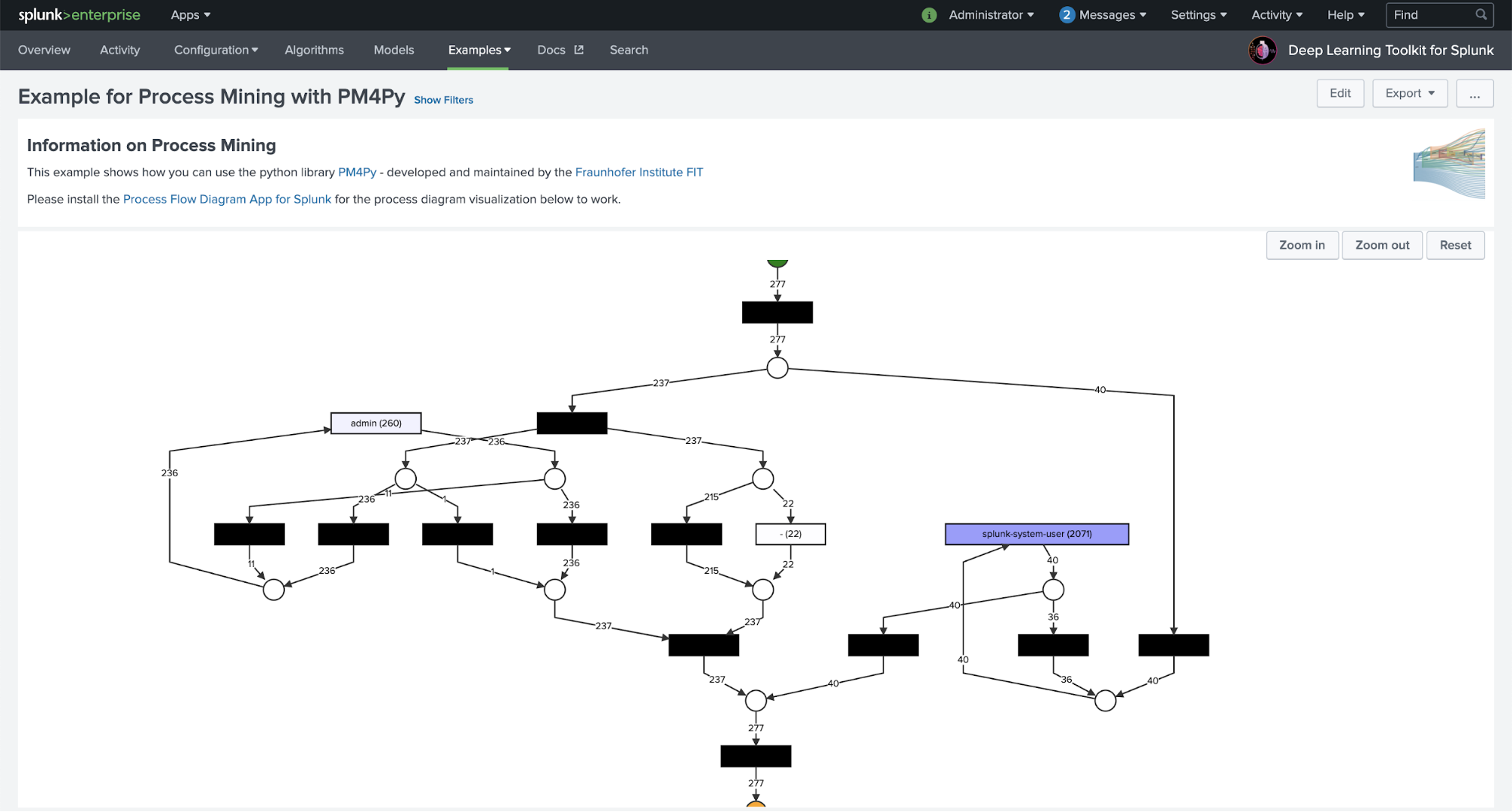
With DLTK you can easily use any python based libraries, like a state-of-the-art process mining library called PM4Py. It is developed and maintained by the Fraunhofer Institute for Applied Information Technology and I want to personally thank the process mining group for their very helpful support and feedback. This example is just scratching the surface of this powerful library and you can discover much more functionality in the PM4Py documentation and adapt to your needs and process mining use cases easily.
If you are curious about the cool visualization shown here, a big shout out to our amazing forward deployed software engineering team: my colleague Daniel Federschmidt recently published the Process Flow Visualization App for Splunk on GitHub that allows you to display such process diagrams easily on a Splunk dashboard. It can take input data from a SPL search or directly render the results of a PM4Py based process mining algorithm running in DLTK. This should provide you with good entry points for customized process mining use cases you can run on top of your data in Splunk.
With the end of 2020 I can personally look back on a very productive and vibrant year of work with various customers. One of my highlights certainly was the use case with BMW Group’s Innovation Lab to develop a Predictive Testing Strategy based on a deep learning approach using DLTK. A big “Thank you!” goes to Marc Kamradt, Andreas Schoch and team for the great collaboration on this project. I’m looking forward to continuing our work in 2021.
Over the run of this year we were able to publish 4 versions of DLTK on splunkbase to make a wide variety of advanced machine learning and deep learning algorithms, tools, frameworks and use cases directly and easily accessible to Splunk users. You can read about all innovations in my other blogs in case you missed them.
Finally, I want to take this opportunity to thank all active contributors, colleagues and the wider Splunk community for supporting this initiative! At .conf20 we published DLTK version 4.0 as an open source app on GitHub which hopefully makes it even easier for anyone who wants to actively collaborate with DLTK. Feel free to post your ideas, open issues or simply reach out and engage with us.
Nobody knows what’s really happening next year, but you can read the Splunk 2021 Predictions for different areas of the business. My New Year’s resolution is very much the same as John’s: let’s make it the year of the customer!
Stay healthy, safe and have a happy, good new year 2021!
- Philipp
Special thanks to the process mining group at Fraunhofer Institute of Technology for their advice and help with PM4Py and my colleague Daniel Federschmidt from Splunk’s forward deployed software engineering for his great new process flow visualization. Last but not least, many thanks to my machine learning architect colleagues Greg Ainslie-Malik and Phil Salm for their valuable contributions to pioneer new useful machine learning and analytical techniques for Splunk customers to turn data into doing.

The Splunk platform removes the barriers between data and action, empowering observability, IT and security teams to ensure their organizations are secure, resilient and innovative.
Founded in 2003, Splunk is a global company — with over 7,500 employees, Splunkers have received over 1,020 patents to date and availability in 21 regions around the world — and offers an open, extensible data platform that supports shared data across any environment so that all teams in an organization can get end-to-end visibility, with context, for every interaction and business process. Build a strong data foundation with Splunk.

Get the latest articles from Splunk straight to your inbox.
© 2005 - 2024 Splunk Inc. All rights reserved.
