
Digital Resilience Pays Off
Download this e-book to learn about the role of Digital Resilience across enterprises.
Have you ever asked yourself why machine learning models come up with one prediction or another? Or do you want to know which features impact your model and its results more than others? Well, we’ve got exciting news for you: the latest version of the Deep Learning Toolkit App for Splunk (DLTK) 3.3 contains new examples you will certainly find useful in answering the above questions. But first, let’s start with a recent addition to the family of algorithms in DLTK: XGBoost.
XGBoost is an optimized distributed gradient boosting library designed to be highly efficient, flexible and portable. As it uses Gradient Boosting and can be parallelized, this algorithm is very popular in data science and is frequently used for regression and classification tasks. The following example shows a simple regression model and is hopefully a good entry point for anyone wanting to create and use XGBoost based models.
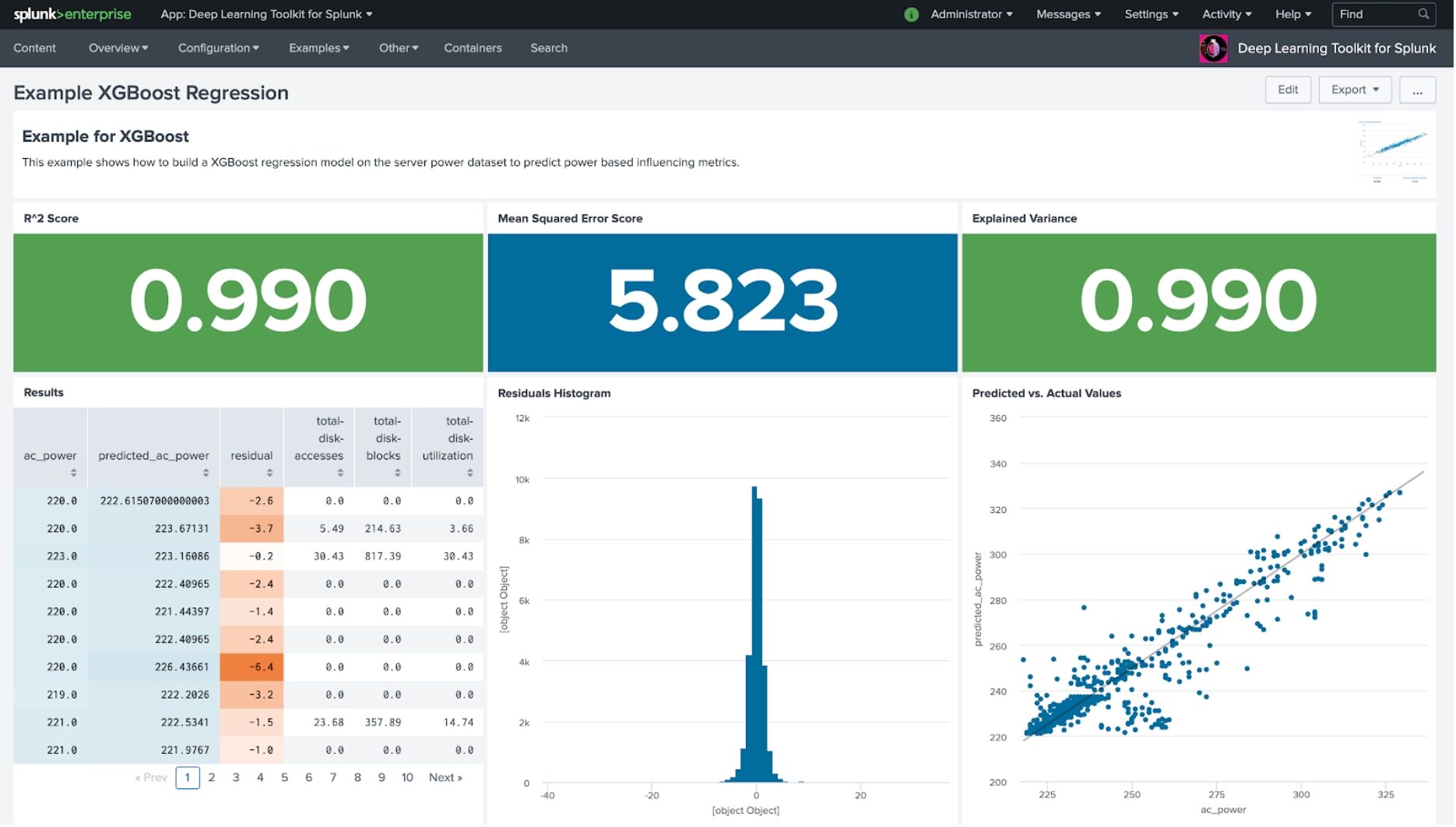
For distributed training, there are a few variants for XGBoost. One of which makes use of DASK to distribute the computation workload. As DASK was introduced with DLTK 3.1 this makes it a good candidate for connecting easily with XGBoost. If you have GPUs available, then running XGBoost with Rapids - introduced with DLTK 3.2 - is another great way to distribute workload and speed up training times.
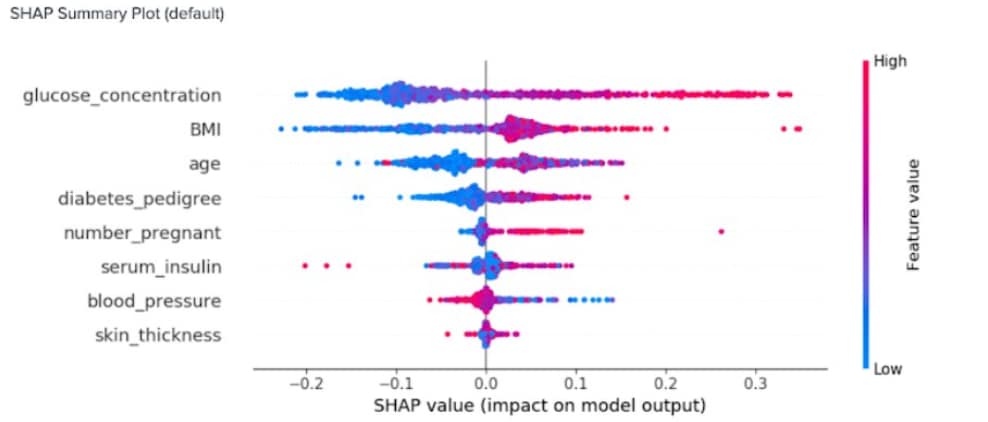
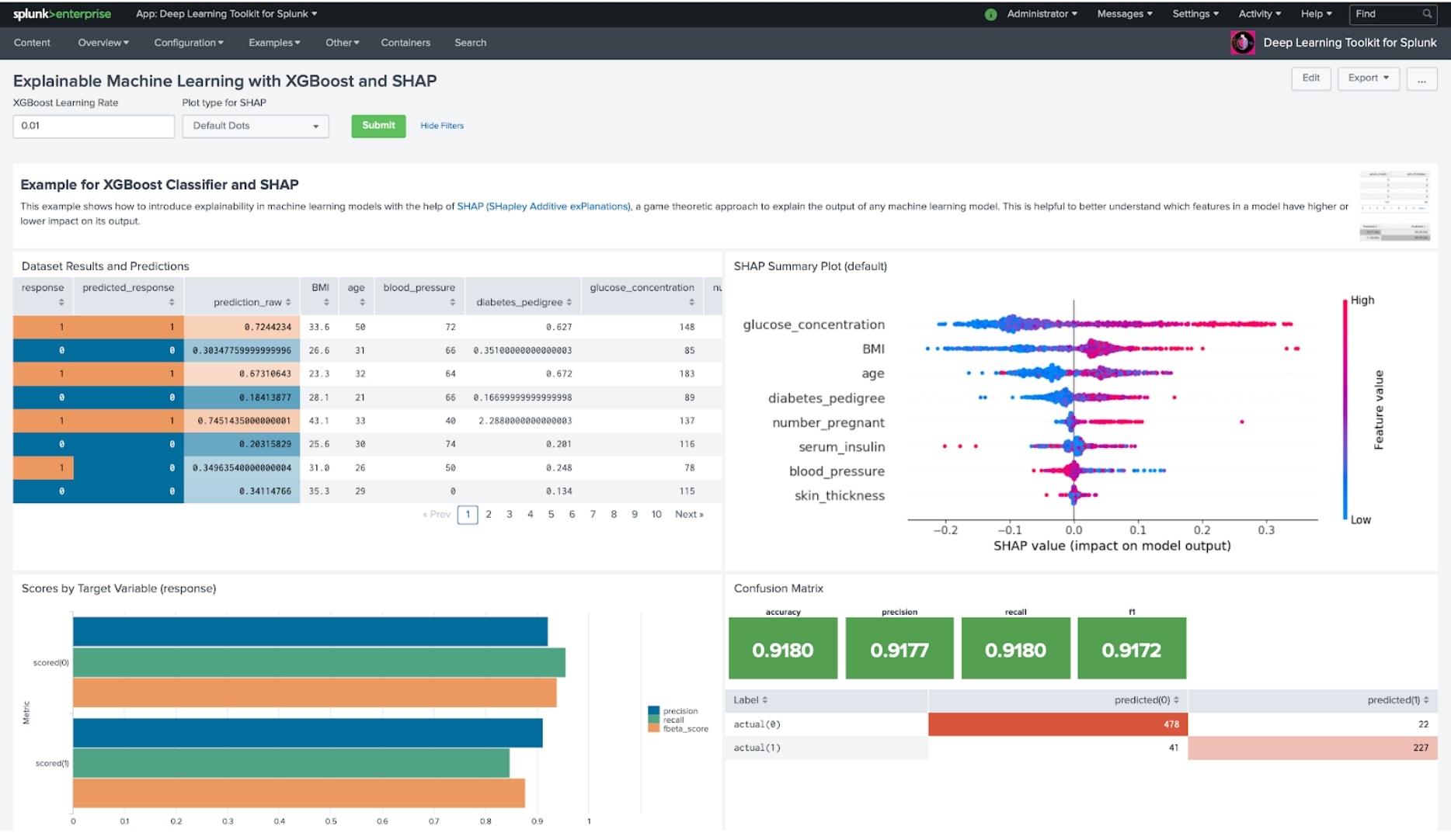
In an era of AI and ethics, explainability is one of the important recent topics in machine learning and data science. Let’s say you have built a machine learning model that performs well on your training and test data: how do you find out which samples and features offer the highest impact on your model’s output? This is where a library like SHAP can provide you with very valuable insights. SHAP (SHapley Additive exPlanations) is a game-theoretic approach to explaining the output of any machine learning model. The following example shows how an XGBoost-based classifier model can be analyzed with SHAP to help better understand the impact of features on the model output. The chart on the top-right provides a view on the distribution of feature values and their impact on the model.
We hope you find these new DLTK features useful and we hope they will help you improve and better understand your models. If you are interested in learning more about DLTK and how customers use it within real-world business use cases, join us for the following two upcoming .conf20 sessions:
The event is free to attend, so register today!
Looking forward to seeing you there,
Philipp

The Splunk platform removes the barriers between data and action, empowering observability, IT and security teams to ensure their organizations are secure, resilient and innovative.
Founded in 2003, Splunk is a global company — with over 7,500 employees, Splunkers have received over 1,020 patents to date and availability in 21 regions around the world — and offers an open, extensible data platform that supports shared data across any environment so that all teams in an organization can get end-to-end visibility, with context, for every interaction and business process. Build a strong data foundation with Splunk.

Get the latest articles from Splunk straight to your inbox.
© 2005 - 2024 Splunk Inc. All rights reserved.
