
Digital Resilience Pays Off
Download this e-book to learn about the role of Digital Resilience across enterprises.

In May we released the Splunk Machine Learning Toolkit (MLTK) version 5.2. We’ve loved telling you about some of the great new features, including the most recent blog on DensityFunction. However, we know that before you can start experimenting with model-building algorithms such as DensityFunction, your data needs to be prepared for machine learning. Machine learning operates best when you provide clean data as the foundation for building your models. This is a common pain point for customers, which is why the Machine Learning Toolkit enables both self-guided and assisted data preprocessing options. In this blog, we’ll highlight the data preprocessing options available within the guided workflows of the MLTK Smart Assistants (and a selection of Experiment Assistants).
Preprocessing can transform your data into fields that give you better data experimentation results, higher quality models, and more usable visualizations. The Smart Assistants in the MLTK offer different preprocessing options within the Learn stage of their step-by-step workflows. Preprocessing steps include algorithms that reduce the number of fields, produce numeric fields from unstructured text, join or extract fields, or re-scale numeric fields. As with other aspects of MLTK guided modeling Assistants, any preprocessing steps taken also generate Splunk Search Processing Language (SPL) for you that can be viewed using the SPL button within each Assistant.
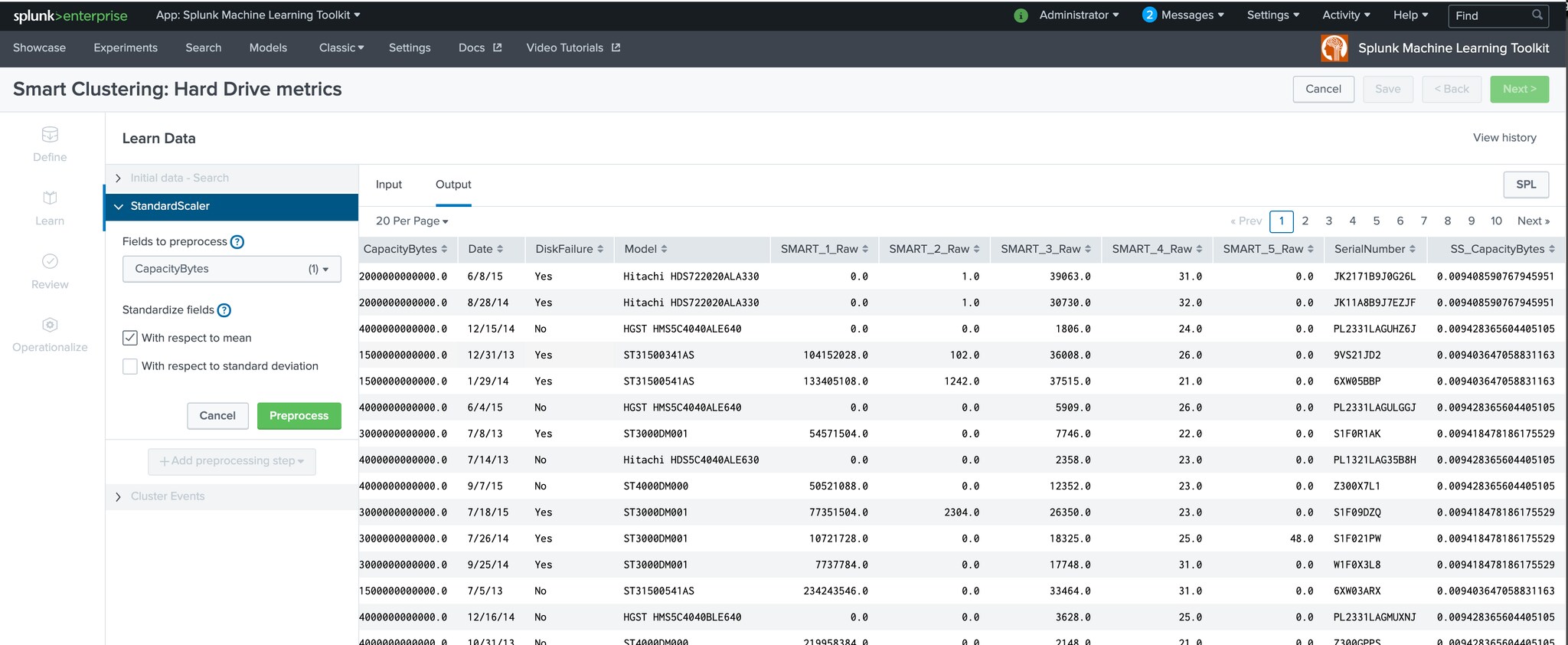
The Smart Clustering Assistant offers the option to use the StandardScaler algorithm to standardize the data fields by scaling their mean and standard deviation to 0 and 1, respectively. This standardization helps to avoid dominance of one or more fields over others in subsequent machine learning algorithms and is useful when the fields have very different scales.
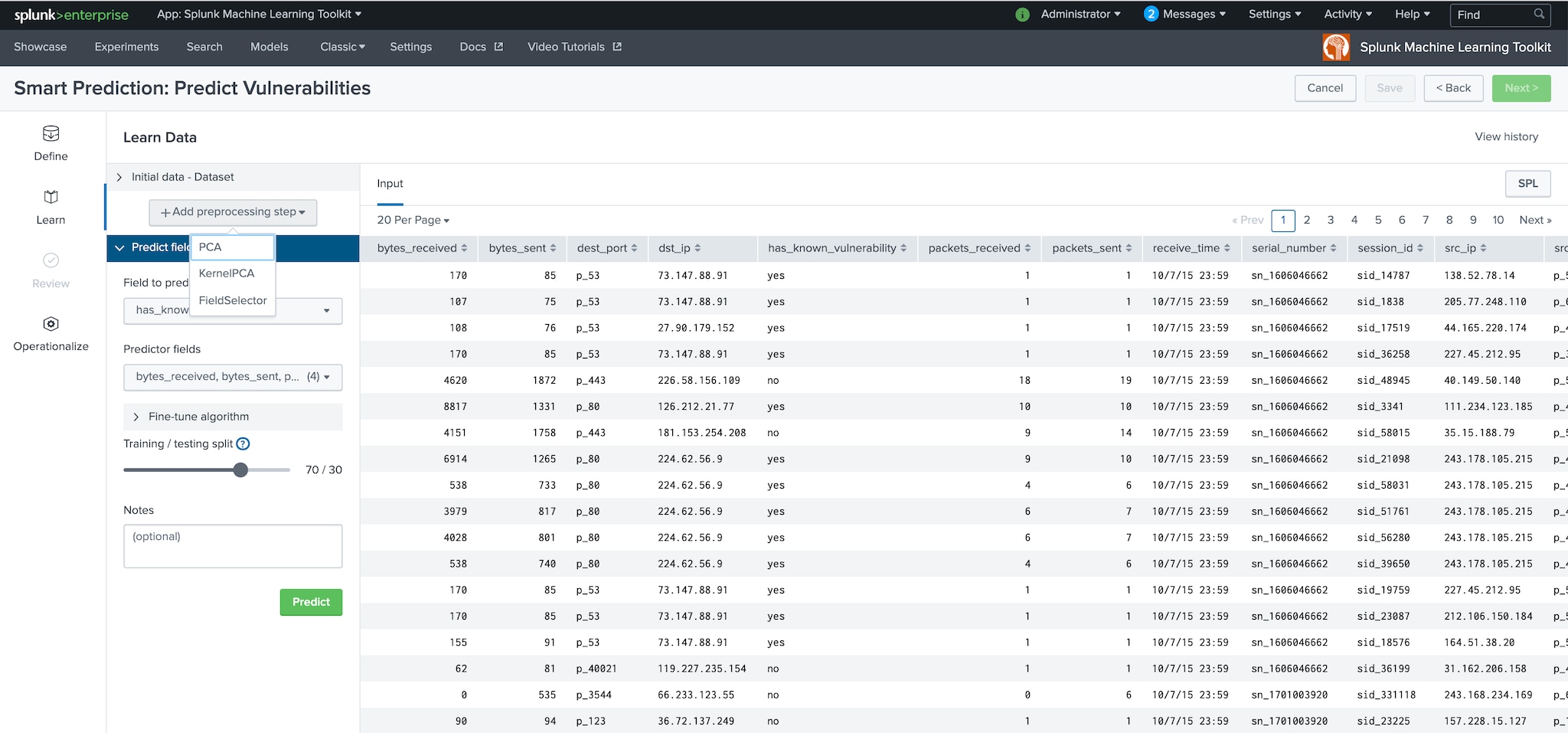
The Smart Prediction Assistant offers the option to use FieldSelector to select the best predictor fields based on univariate statistical tests. Users can select modes including Percentile, K-best, False positivity rate, False discovery rate, and Family-wise error rate.
Both the Smart Clustering Assistant and Smart Prediction Assistant offer PCA and Kernel PCA preprocessing algorithms options. Use these preprocessing algorithms to reduce the number of fields by extracting new, uncorrelated features out of the data. PCA and KernelPCA can also be used to reduce the number of dimensions for visualization purposes, for example, to display a scatterplot chart.
To learn more about these algorithms and other preprocessing options with the MLTK Assistants, check out our User Guide.
Ready to get started? Download the free Machine Learning Toolkit app today and see how you can leverage machine learning with your Splunk data!
This blog was co-authored by Kristal Curtis, Senior Software Engineer
----------------------------------------------------
Thanks!
Mohan Rajagopalan

The Splunk platform removes the barriers between data and action, empowering observability, IT and security teams to ensure their organizations are secure, resilient and innovative.
Founded in 2003, Splunk is a global company — with over 7,500 employees, Splunkers have received over 1,020 patents to date and availability in 21 regions around the world — and offers an open, extensible data platform that supports shared data across any environment so that all teams in an organization can get end-to-end visibility, with context, for every interaction and business process. Build a strong data foundation with Splunk.

Get the latest articles from Splunk straight to your inbox.
© 2005 - 2024 Splunk Inc. All rights reserved.
