
Digital Resilience Pays Off
Download this e-book to learn about the role of Digital Resilience across enterprises.
Splunk is committed to using inclusive and unbiased language. This blog post might contain terminology that we no longer use. For more information on our updated terminology and our stance on biased language, please visit our blog post. We appreciate your understanding as we work towards making our community more inclusive for everyone.
When recently looking for a replacement for our internal build system, I wrote out a wish list of what I wanted in a build system. This post will describe the thought process around that wish list and why eventually we decided CircleCi was the best solution that fit all these points.
Our starting code was a single Java repository with dozens of submodules, but now includes Go code repositories as well as CollectD and other open source libraries. Designed for the Java build case, our existing build system was a Jenkins build from a Dockerfile that installed a java JDK and Go runtime. On startup it ran a python script to setup and start the internal jenkins server, which was configured by copying XML config generated by another Jenkins instance. This was then turned into a runtime configurable pystache template onto the git repository that hosted the Jenkins Docker image, which then ran builds inside the Jenkins docker image when commits happened. Whew! Putting our Jenkins config inside a git repository allowed us to version and rebuild our Jenkins environment. Using docker for our Jenkins instance allowed us to spin up new instances quickly. Using pystache made it less complicated to add submodules to the main git repository.
Unfortunately, all of this had the disadvantage of making it very difficult to iterate on the build system that itself was very complex. We also ran into issues around caching code dependencies and parallelizing builds. The existing build system would cache snapshots of submodules to reuse for later builds, but had no complex logic around knowing if a snapshot was fresh or not, which means we could only build one branch of code at a time.
My build system wish list includes the following points:
Reproducible builds exist on a spectrum. At the farthest end, one expects the exact same bytecode if the same build happens twice. That’s a bit extreme for our case. What we needed here was the same code in, built the same way, should be enough. This means the build parameters, third party libraries, the code, and the process of the build should be as similar as possible between builds of the same code.
Note here that reproducible builds include the build parameters. If a build changes linker parameters, then the build has changed. This is important for systems that put build configuration separate from code. When Jenkins decided which parameters to pass to a build command, we could run into situations where it was now impossible to reproduce an old build if Jenkins changed.
For example, our old Jenkins setup would preinstall the JDK used to compile the code. This meant that reverting code would result in a build that wasn’t the same as it was before, since the old build was using JDK 7 but we were now trying JDK 8.
Isolated builds mean that one build shouldn’t change because of another build. This can be violated in many subtle ways. The most common way is that a build may have a setup step that, once setup, is no longer repeatable but ignored on the next build.
For example, code that depends on go get could continue to work even if the remote repository was deleted. Code that depends upon Maven could fail in the future if Maven cached a library that has changed (often true when depending upon snapshot versions). A test could depend upon an explicit port number that prevents two tests running at the same time. Docker images can fail to build if a cached build step is no longer reproducible.
The best way to isolate builds is to run each in its own machine, VM, or docker container. Our previous build system ran builds on the same host, which allowed one build to pollute the state of another in subtle ways.
Fast builds are important for iterative development. Fast builds usually require some sense of parallelism and caching in the build system.
This is a consequence of wanting fast builds. State that is generally immutable but takes a long time to setup should be cacheable. In order to ensure isolation from builds, this cache is ideally a whitelist rather than a blacklist. Good examples here are exact versions of a JDK or library.
Our old system was a blacklist of things not to cache and we found that chasing down the blacklist was a never ending battle. We had times where docker would cache steps that were no longer repeatable and caused builds to break long after the offending code was removed.
Besides being able to cache state between builds, it’s also important to be able to easily clear caches if needed. Being able to clear the cache quickly and easily helps debugging reproducibility and verify a fully clean build still works.
This is a requirement for repeatable builds. If code in one repository depends upon code in another repository, then a SHA or specific commit should tie the two repositories together.
Without a specific commit to tie the two repositories, changes to another repository can cause builds to change or just stop working. Obvious examples: depending upon snapshot java libraries or using “go get” to get code from a master branch.
This can also be violated in subtle ways. One subtle way is depending upon a linter or another configuration application in your build system. For example, your build generates thrift objects, but if you don’t lock down the version of thrift you use to generate code then the generated thrift code can change. Or, if you don’t lock down the version of maven used to build your code, a maven bug fix or feature could modify the resulting binary behind your back. Or your build system uses a linting step like http://cppcheck.sourceforge.net/ or https://github.com/golang/lint and you don’t lock down the version of linter you use to your build, then your build could fail in the future due to a changing lint check. It’s not enough to use the latest of any dependency: builds should reference specific versions.
Build system iteration speed is often ignored mostly because it’s not touched by every developer in a company, but for the same reason fast iteration speed is important for engineers, fast iteration speed for build systems is also important. This means debugging a bad build should be painless. Things often don’t build the same on your development machine as they do in production, and when they don’t you’ll need to investigate why, which usually involves poking at the build system. In a shared build system environment, this can be dangerous. Ideally this poking would exist separate from the production build, but in an environment as close as possible to it.
Building as often as possible surfaces errors as quickly as possible. Ideally this means builds/tests should be triggerable off git commits.
Our old system would only run builds when we were out of code freeze. This was an artifact of builds caching results a bit too aggressively. This means when we unfroze code, build errors would pop up from code long ago. A well designed build system should understand that builds will happen across time.
Build systems that require engineers to remember they are in a build system or take multiple steps when modifying code get in the way of engineer development speed. Build systems should exist in the background and leave developers in a normal development workflow.
Parallel builds are an important part of making builds faster. The biggest part here is to parallelize on a dimension that grows with the size of the codebase. For example, running builds across OSs or JDK versions run in parallel, but because they don’t scale with the size of the codebase, as more engineers start writing code the builds get slower.
On the other hand, if you can parallelize on a dimension such as pom.xml files, directories, or filenames (larger codebases tend to make more of those) your build times can stay in check as the system grows.
This isn’t particularly required, but is a great way to summarize an ideal situation around reproducible builds. Commits are already natural references to code and if builds can happen on a commit then your system has a natural delineator for when builds should happen.
Versioning code is already a pretty obvious best practice for engineers. An ignored aspect of this is versioning important configuration. Without being able to version build configuration, it’s difficult to track when and who made a change to the build Because changes to the build system can drastically change the resulting build, this information is important for reproducible builds.
Our previous build system, while complicated, versioned Jenkin’s build XML configuration in an external git repository allowing us to track changes over time.
This is less of a consideration if your company uses one large repository vs many smaller repositories, but in general if a user wants to setup a build for a new system that setup should be as simple and automated as possible.
Our old build system made it difficult to extend for repositories outside of our primary Java repository. The result was when other git repositories were created, such as code around infrastructure or open source, engineers simply didn’t automate any unit testing or linting at all.
This is more of a maintenance optimization, but less build systems is less to remember. Since we release code for both open and closed source, this means we would ideally have a build system that can work for both.
After investigating a few build systems, including Travis, shippable, and drone.io, I eventually settled on CircleCI. Let’s quickly go over where CircleCI sits on this wishlist, for some of the build system specific points.
It’s important to note that Jenkins can do anything, no literally, anything. It’s also obvious that our existing use of Jenkins had lots of fundamental issues that are not Jenkins specific. Since Jenkins can do anything, it’s possible to change our current usage of Jenkins to match my wishlist. For this wishlist to achieve parity in Jenkins with what I get out of the box with CircleCI, however, would require a sizable investment in both build system configuration and continuous maintenance. If the argument that a system can do anything is a reason to use it, we would all be writing web servers in bash script and C. CircleCI (and most SaaS build systems) gives us a baseline setup that starts us in the right place.
After trying a few configurations, we settled upon the following best practices using CircleCI
By minimizing the content of our CircleCI configuration setup file, we’ve made it easier to rerun our build in a different environment if CircleCI is unavailable or if we want to try other build systems. An example exists in our metric proxy https://github.com/signalfx/metricproxy/blob/master/circle.yml
We standardized on each repository containing a root circle.sh file that runs with a different parameter during the cache/test/deploy phases and env variables for passwords. One common part is the cache step for all of our circle.sh files clones a repository, circleutil, that contains common bash functions for all our repositories. Once we have circleutil set up, we can easily install various versions of Go or JDKs while minimizing repeated code across repositories. You can see an example in our metricproxy at https://github.com/signalfx/metricproxy/blob/master/circle.sh.
This also makes it easy for us to separate out certain elements of the build – for example, dev can focus on test, the component build itself, etc, and build can focus on housekeeping things like making it easier to track code changes, putting in hooks for code analysis, etc. Also, the circle.sh file is another thing that makes it easier for a new dev to spin up a build that meets the requirements we’ve established.
Many of our builds contained common bash functions for setting up the build environment. The repository circleutil at https://github.com/signalfx/circleutil holds these common build functions. We tag commits of this repository and then reference git tags in our circle.sh files to version our inter repository build dependencies.
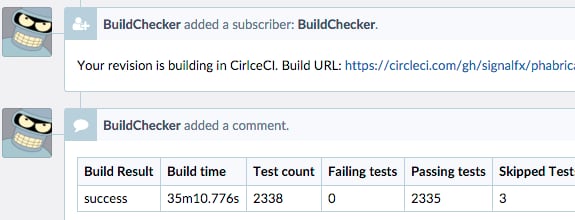
Our phabricator integration is open source at https://github.com/signalfx/phabricator-CircleCI. Using it, we’ve been able to schedule CircleCI builds for all our phabricator diffs. Some of the difficulty with this integration was communicating between CircleCI and our deployment environment, which was behind a firewall. We use Amazon’s SQS as a simple message passing framework to communicate from behind a firewall. Some information about this process is at https://discuss.CircleCI.com/t/compatibility-with-phabricator/183/8.

We’re very happy with CircleCI as a build environment. Versioning build configuration with the code, which is usually standard with SaaS build environments such as CircleCI and Travis, makes so much sense. I can’t see ever reverting back to the old system of separating build configuration and source code. Power features such as SSH into a container, rebuild without cache buttons, and parallelizing builds with a simple slider give me what I need to grow the build environment and signal to me that the developers at CircleCI understand the needs of development environments like ours at SignalFx.
Interested in working on these kinds of problems? We’re hiring engineers for every part of SignalFx!
----------------------------------------------------
Thanks!
Jack Lindamood

The Splunk platform removes the barriers between data and action, empowering observability, IT and security teams to ensure their organizations are secure, resilient and innovative.
Founded in 2003, Splunk is a global company — with over 7,500 employees, Splunkers have received over 1,020 patents to date and availability in 21 regions around the world — and offers an open, extensible data platform that supports shared data across any environment so that all teams in an organization can get end-to-end visibility, with context, for every interaction and business process. Build a strong data foundation with Splunk.

Get the latest articles from Splunk straight to your inbox.
© 2005 - 2024 Splunk Inc. All rights reserved.
