
Splunk ITSI for AIOps
Discover our industry-leading approach to AIOps & monitoring.
Splunk is committed to using inclusive and unbiased language. This blog post might contain terminology that we no longer use. For more information on our updated terminology and our stance on biased language, please visit our blog post. We appreciate your understanding as we work towards making our community more inclusive for everyone.
Okay, so you’ve decided it’s time to use adaptive thresholding for one or more of your service KPIs. Awesome!
 Building on foundational guidance from Ensuring Success with Splunk ITSI Part 1 and Part 2, let's get deep into the best practices around adaptive thresholding. Once again, getting the right configurations in place to generate meaningful thresholds and alerts with adaptive thresholding requires both guidance and experience.
Building on foundational guidance from Ensuring Success with Splunk ITSI Part 1 and Part 2, let's get deep into the best practices around adaptive thresholding. Once again, getting the right configurations in place to generate meaningful thresholds and alerts with adaptive thresholding requires both guidance and experience.
Here's some of that guidance.
Before we get into configurations, we need to ammend our definition and understanding of KPI severity. In Splunk IT Service Intelligence (ITSI), as I’m sure you recall, we have 6 severities: critical, high, medium, normal, low, and info.
With static thresholds, we tend to associate these states with some degree of "working" or "broken," and we attempt to threshold them accurately so that a KPI is only critical when we’re pretty sure something is really broken. However, adaptive thresholds aren’t necessarily about "working" and "broken"—they are about "normal" and "abnormal." Therefore, it will help if you mentally redefine these states to something more like extremely high, abnormally high, normal, abnormally low, and extremely low.
This distinction—while subtle—is very important; it will shape your mindset on threshold values and alert configurations when using adaptive thresholds.
For clarification, this section does not focus on which pre-configured thresholding template to use; we’ll talk about that in a moment. Here, we simply want to discuss each of the three algorithms and which might be best for your situation. We won't go deep into the mathematics of each equation because it is pretty straightforward and plenty of general information can be found online.
What I want to do is call out the general behavior and practical pros and cons for each algorithm, so that you can choose the one that best suites your needs. Keep in mind that each algorithm will re-compute future threshold values each and every night based on historical data spanning the configured training window for that KPI.
Quantile
The quantile algorithm allows you to put threshold bounds at various percentiles based on historic data. As a simple example, we might choose to set critical severity for data points falling below the 1st percentile (0.01) and above the 99th percentile (0.99). Because you must choose percentile threshold values between 0 and 1, this is the only algorithm of the three that will never produce thresholds above or below your historical data min and max values. Because of this, you are likely to see your threshold bounds crossed repeatedly when using quantile presuming future data behaves like historic data. This could influence your alarming strategy, but on the plus side, this algorithm is simple to understand and is fairly resistant to very large outliers in historical data.
Standard Deviation
The standard deviation algorithm allows you to specify thresholds based on multiples of the standard deviation from the mean—negative values producing thresholds below the mean and positive values producing thresholds above the mean. This algorithm is sensitive to outliers in historic data which may cause much larger threshold values than you desire or expect. Additionally, if your data is skewed (larger values and outliers present, but smaller values and outliers not present, such as what you might see with a response time KPI) you might struggle to generate meaningful lower bound thresholds. If your data is well distributed about a mean, this could be a good choice for you. Moreover, even if your data is skewed, this could be a good choice for you if you only care about meaningful thresholds in the direction of the skew.
Range
Range may feel a little bit like quantile, but they are quite different. Range is interested in the min and max data points from your historic data and the span between those values (max – min). Your thresholds then become a multiplier of the span added to the min. So, a value of 0 will set a threshold to the historic data min, a value of 1 will set a threshold to the historic data max, a value of -1 will set the threshold to the min – span, and a value of 2 will set the threshold to the max + span.
As you can see, outliers in historical data will directly affect the span value which will then affect the thresholds. If you need or want the ability to specify thresholds beyond historic data mins and maxes and standard deviation doesn’t work for you, this could be a good choice.
I've gotta tell you... I'm not a statistics guy. In fact, if I recall correctly, I skipped more than one of my college stats classes in favor of more enjoyable things; so when I heard "uniform distribution of data about the mean", "data skew" and "outliers" being used in an ITSI context, I understood these things in principle but didn't really know how to vizualize them to see if they were affecting my thresholds. If you're struggling like I was, let me try to help. It takes a relatively simple Splunk search to visualize the distribution of your data and see outliers. To do so, we'll need to ensure the KPI of interest has already been built and backfilled. Once backfilled (or running for several weeks) we'll have enough data in the itsi_summary index to run our search. Of course you can always run a similar search against the raw data feeding your KPI, but ITSI uses the itsi_summary index data during it's nightly computation; so too, shall we. Run the following Splunk search from within ITSI and be sure to insert your KPI name as needed at the beginning. You might have to fish around the ITSI summary index a little to get the right KPI name and ensure correct filtering.
index=itsi_summary is_service_aggregate=1 kpi="<YOUR KPI NAME HERE>"
| bin alert_value as bin_field
| stats max(alert_value) as sort_field count by bin_field
| sort sort_field
| fields - sort_field
| makecontinuous bin_field
The above SPL will produce the following visualization of your data
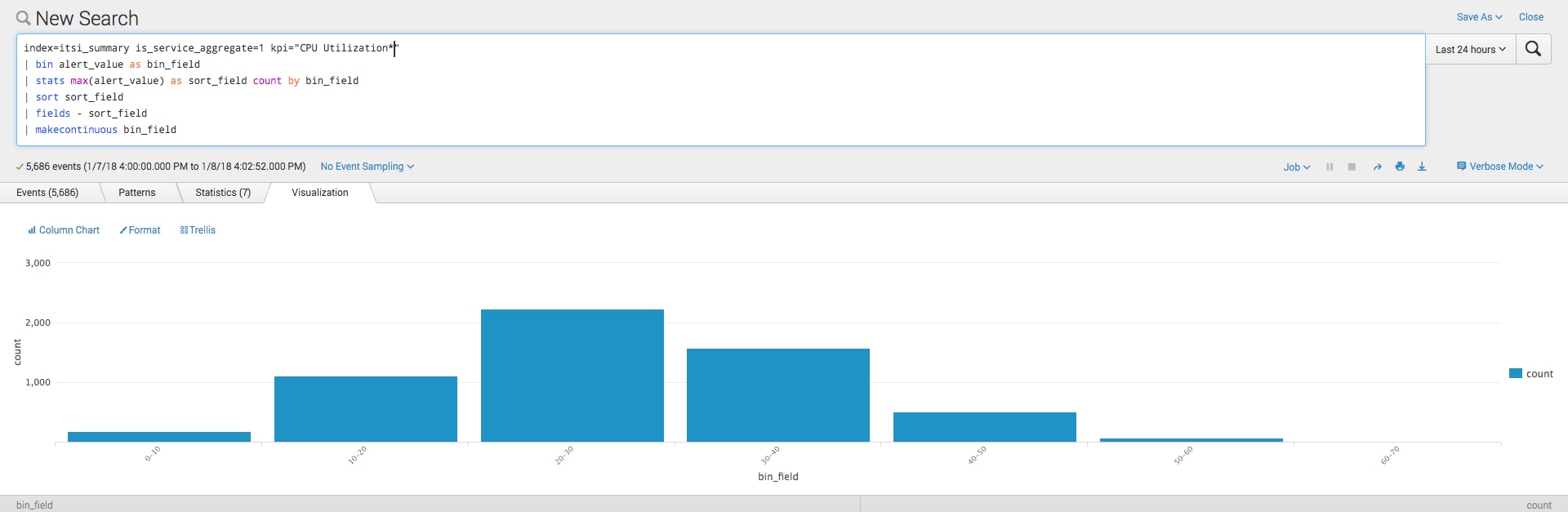
The search consolidates the many alert_value results down to a smaller set of buckets using the bin command. We also leverage the makecontinuous command to ensure that any outliers are visually apparent. The results above show a fairly uniform data distribution with no outliers. If necessary, you can add the span option to your bin command to provide some more granularity to your graph as shown below.
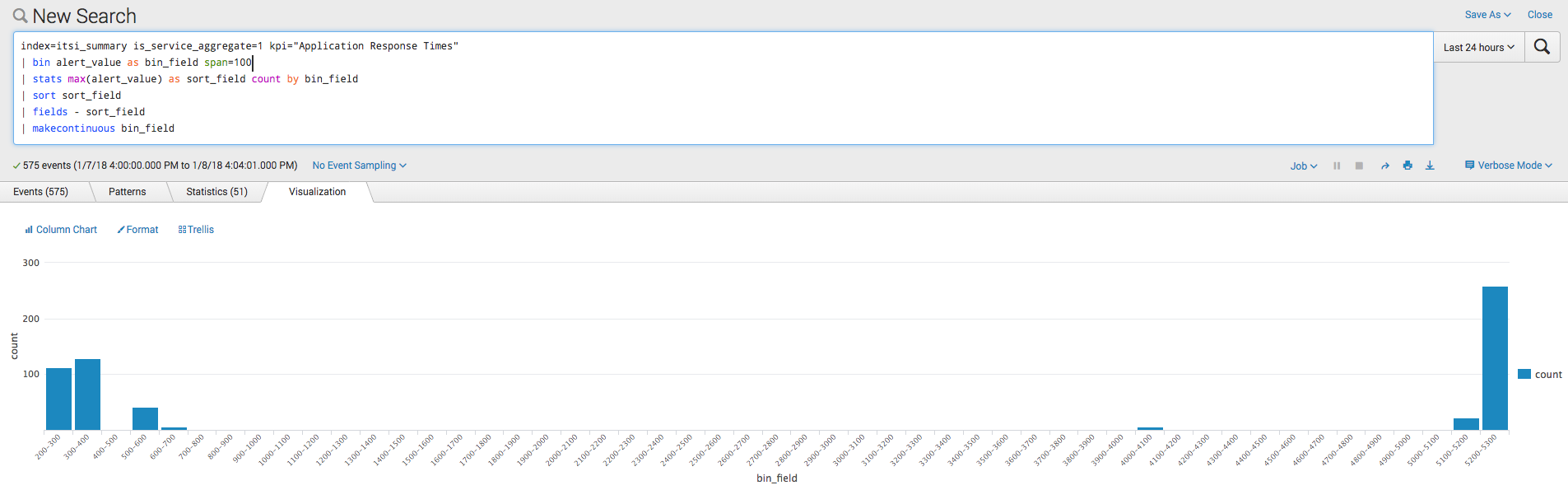
The visualization above shows data which is not uniformly distributed and has quite a few large value outliers which might affect computed threshold values.
Believe it or not, I’m going to highly recommend you don’t use a pre-configured thresholding template just yet; the templates are just suggestions and they might not meet your needs. If you blindly select one, you’ll likely not understand the process and be frustrated with unexpected results.
Instead, I want you to walk through the process of adaptive thresholding a KPI “from scratch” at least once so you understand how to ensure success every time. Once you do so, you’ll know if a particular pre-configured thresholding template is the right choice for you moving forward.
Okay, it’s time to get started thresholding your KPI. Before we get going, I’m going to assume that you’ve already decided which algorithm you need or want based on the descriptions above. Of course, you don’t need to be locked in and it’s okay to try each one out, but if you’re totally lost on how each algorithm works and which might be best for your KPI data set, you’re not ready to threshold your KPI. We’re also going to keep the training window at 7 days to start, but as we identify smaller and smaller time policies, we might need to open that up to 14, 30, or 60 days to ensure we have adequate data points in our short time windows to generate meaningful threshold values.
During this portion of the blog, we’ll walk through a sample dataset and show screenshots as we go. The KPI represents logins to a web server which exhibits different behaviors each day of the week and each hour of the day.
To begin our default policy configuration, we need to land on the severity parameters for the chosen adaptive thresholding algorithm that align with our severity definitions. If we’ve determined that quantile is the right algorithm for this KPI, maybe we’ve also determined that >95% is our high threshold and <5% is our medium threshold (or to use or adjusted severity terminology, abnormally high and abnormally low). Click apply thresholds and see how things suss out. Don’t worry if it doesn’t look right yet—that’s okay!
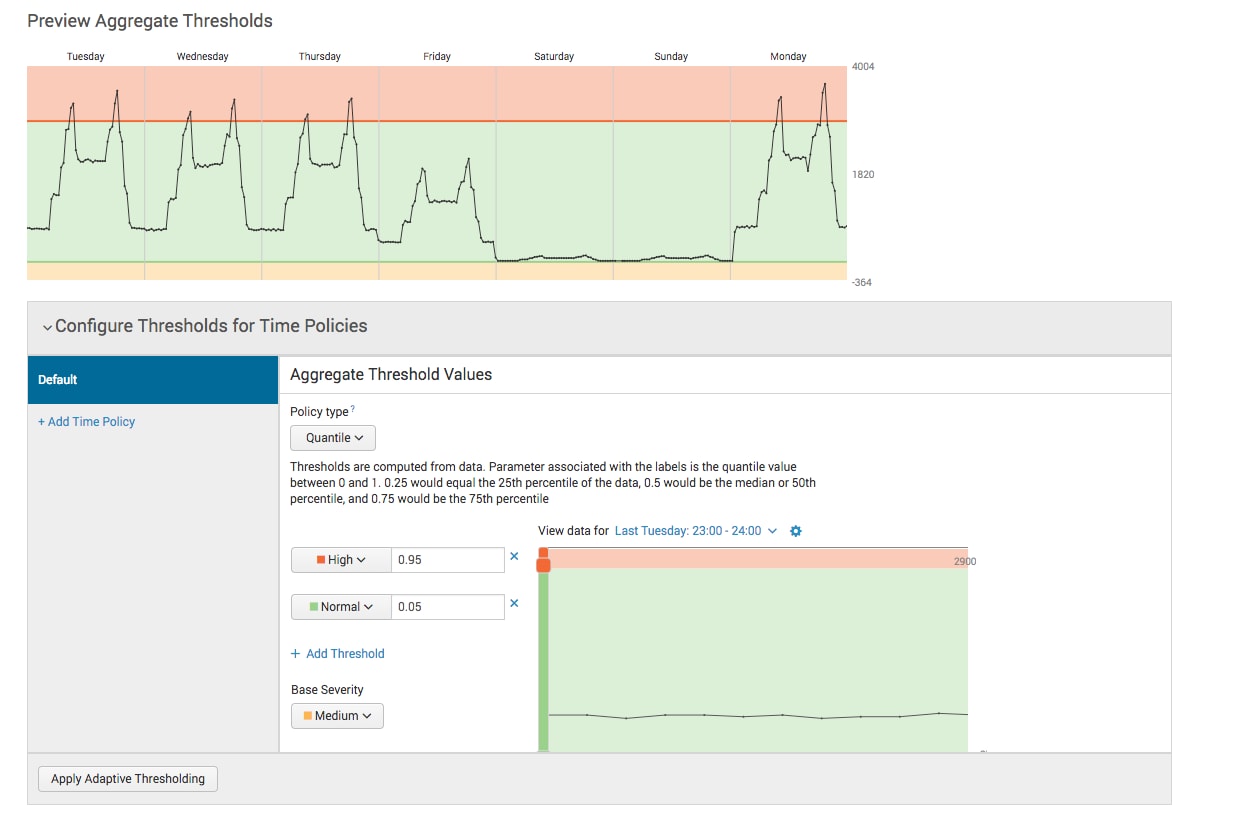
I’ll tell you that it’s at about this point in time where people start freaking out a little bit. It’s a combination of seeing too much red, or too much green, or not understanding how to interpret the graphs in the UI. This is particularly true when people use the pre-configured templates, so in a panic, they click through them all until they find the one that looks the most-sane. Well, that’s not a very strategic approach now is it? Let’s talk about what to do next.
The first thing you’re likely to notice when looking at the week-long KPI graph is that certain times of the day or days of the week are predictably different than other times (this is clearly the case in the screenshot above). Perhaps AM differs from PM, or weekends differ from weekdays, etc.—these variations are almost always explainable and expected, but you should work with the service owners to confirm.
Presuming the variation is expected, the next step is to create a time policy to encapsulate that difference. In our case, we expect weekend traffic to our site to be very, very light. So, let’s start by separating weekend traffic from the workweek with a new time policy. Apply the same adaptive threshold algorithm and severity values to your new time policy, and apply adaptive thresholds again.
ITSI will only use the historical data points within that time policy to determine the threshold values, thus, the difference should now be better accounted for. Looking better yet?!
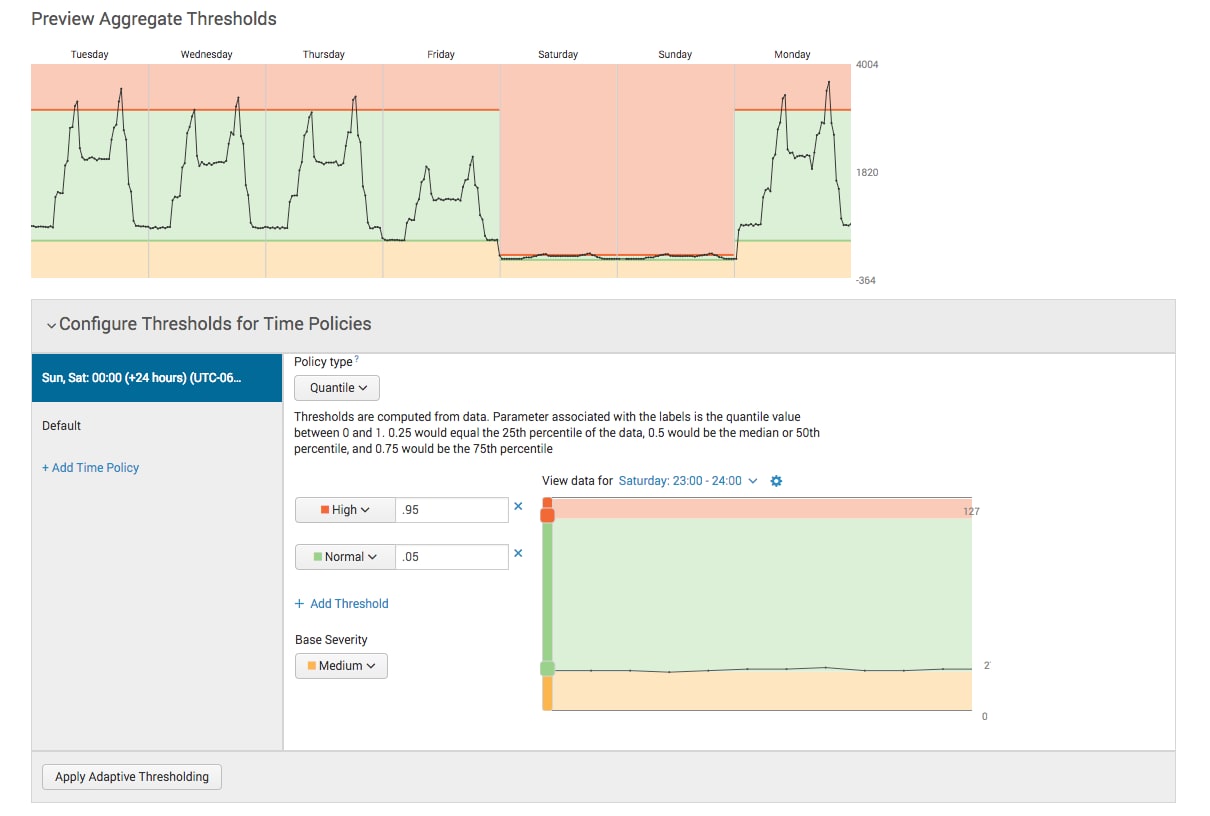
It’s clear that we’ve made improvements, but we still see problems. It looks like we have some spikes going into the red on Monday. After working with the service team, they tell us that logins predictably spike around 8am and 5pm most every day of the workweek; we can create time policies to isolate those spikes. We can also create time policies to isolate the workweek evenings where things look pretty quiet.
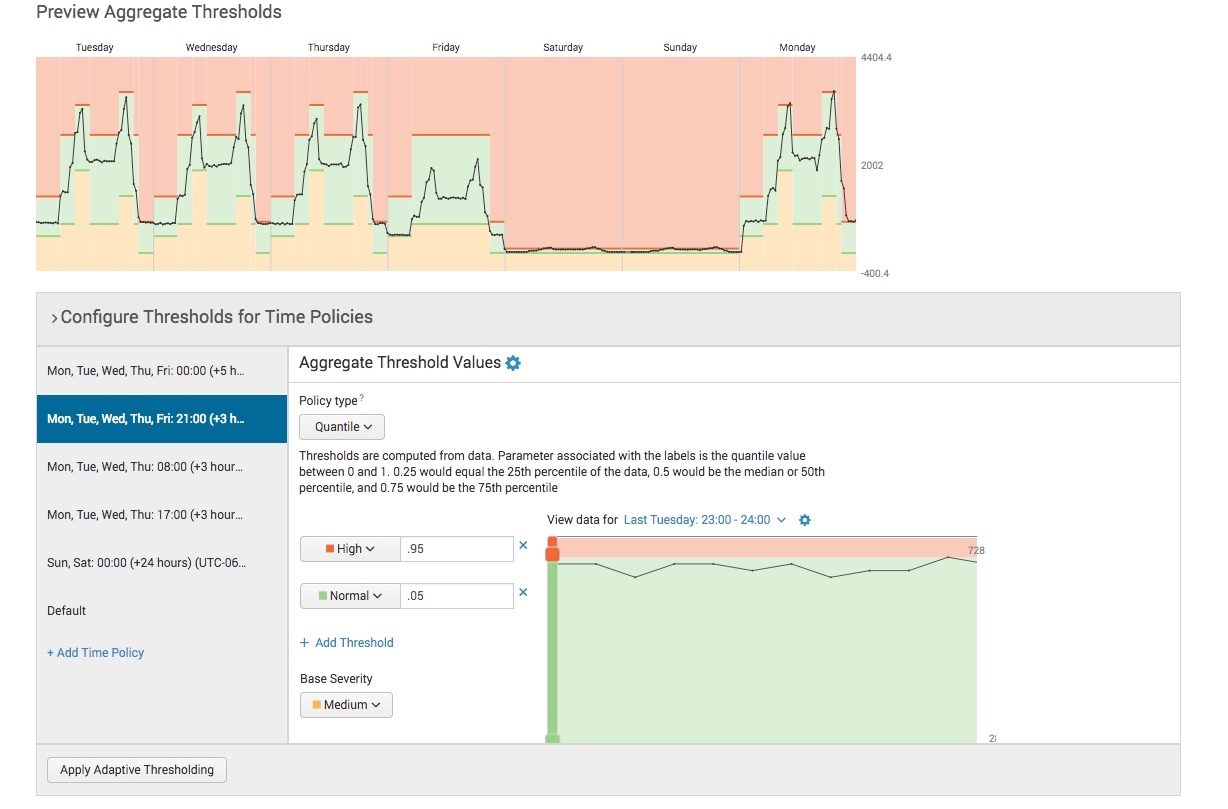
So there you go. This might not be perfect and we'll probably have to continue this process to create the right number of time policies, but we’re a lot closer! We’ve applied a methodical approach and most importantly, we understand and can justify the purpose of each time policy.
To restate the question, why try to lump together the behaviors of multiple hours of each day or multiple days of the week as we have in the example above? Why not just assume that every hour of every day is a little different from every other and create 168 (24x7=168) different time policy windows? Well, you can, but it does have it's drawbacks.
First, you're shrinking the pool of historical data to be used in the threshold computation which will introduce increased opportunity for variance and impact of outliers. Second, you might accidentally miss detection of a legit problem. If there is an undiagnosed issue with the application that causes predictable but not yet detected spikes in a KPI (for example cpu or count of errors) you're missing the valuable opportunity to identify and discuss this with the service team. Lastly, you're creating far more configuration windows for you to manage and ITSI to compute nightly, introducing potentially unnecessary load and effort.
Keep in mind that some time policies (logins to a website being a great example) might not have much if any data in them. This makes generating meaningful adaptive threshold values difficult. Don’t hesitate to fall back to static thresholds when the data set isn’t sufficient to produce accurate thresholds.
Now that we’ve gotten those KPIs thresholded with adaptive thresholds, we need to think about what type of alert configurations make sense to transform abnormal KPI results into actionable alerts.
To me, two obvious options come right to mind; first, alert when a KPI is exhibiting extremely abnormal behavior, and second, alert when multiple KPIs are simultaneously exhibiting abnormal behavior. Remember, however, that depending on the algorithm and threshold values you choose, you might not be able to determine that a KPI is extremely abnormal (just abnormal). As stated above, this is particularly true if you select quantile. If that's the case, you might consider as an alternative alerting when a KPI spends an excessive amount of time in an abnormal state.
When creating alerts based on the normalcy of multiple KPIs, try to identify two or three KPIs that are highly indicative of service health and create an alert only when most or all of them start to exhibit abnormal behavior. As an example, alerting based on abnormal results from KPIs for count of errors in a log file and number of successful logins might help you identify looming service issues. You may also want to consider looking at multiple KPIs across two or more critical tiers of your service. For instance, if you're seeing abnormal error counts in your web tier and your services tier, you may well have an issue.
If you’re finding KPIs to be going red too often or staying green too often, you most likely:
These problems often will spill over into negative and false positives with your alerts as well.
There are a few things when configuring adaptive thresholds in ITSI that may really trip you up, so let’s clear the air on them if we can.
The week preview graph shows everything is in the green, but I know that can’t be right.
This one is a KILLER! What isn’t obvious here is that each data point on the week preview graph when configuring adaptive thresholds represents a 30-minute block of time. Therefore, if your KPI is set to run every 15 minutes, you technically have two data points that are being averaged together; if your KPI is set to run every 5 minutes, you have six data points being averaged together. Even though the adaptive threshold computation runs against each and every KPI data point to ensure accurate computations, the timechart in the week-long preview might swallow up outliers making it look like nothing will ever be red, but that’s not necessarily the case.
I’m getting negative lower-bound threshold values for KPIs that will never have negative values.
Yes, this will occur when using standard deviation or range algorithms because they both use subtraction and their upper and lower bounds are unrestricted based on your specified threshold values. If both the upper and lower bounds are important to you, and negative threshold values are not acceptable, you can try one of the following:
I’m getting really large threshold values that I don’t think will ever be crossed.
This is most likely occurring because your historical data has significant outliers. The only simple solution would be to increase your training window to try to pull in more data, otherwise this could be a tough problem to solve without switching to quantile or static.
I've selected one of the the "1-hour blocks" pre-configured time policies and I'm confused by the results I see.
Both the "1-hour blocks every day" and the "1-hour blocks workweek" pre-configured templates will lump together one-hour blocks across multiple days. You might be (mistakenly) expecting the pre-configured policy to treat each hour of each day different from the rest as discussed above. No such pre-configured template exists for that desired thresholding strategy; you'd have to create a custom policy should you desire more granularity than what is provided by the 1-hour blocks pre-configured templates.
I truly hope you found this blog series to be insightful, valuable, and most importantly, practically applicable to your world. I'm highly interested in receiving feedback on what you implemented that worked well and what did not. Any opportunity you can provide me to refine and improve this guidance will help other Splunkers in the future. To that end, do not hesitate to contact me or comment directly on the blog to provide your feedback.

The Splunk platform removes the barriers between data and action, empowering observability, IT and security teams to ensure their organizations are secure, resilient and innovative.
Founded in 2003, Splunk is a global company — with over 7,500 employees, Splunkers have received over 1,020 patents to date and availability in 21 regions around the world — and offers an open, extensible data platform that supports shared data across any environment so that all teams in an organization can get end-to-end visibility, with context, for every interaction and business process. Build a strong data foundation with Splunk.

Get the latest articles from Splunk straight to your inbox.
© 2005 - 2024 Splunk Inc. All rights reserved.
