
Digital Resilience Pays Off
Download this e-book to learn about the role of Digital Resilience across enterprises.

Today, users and customers are driven by response rates to their online requests. It’s no longer good enough to just have a request run to completion, it also has to fit within the perceived limits of “fast enough”. Yet, as we continue to build cloud-native applications with microservice architectures, driven by container orchestration like Kubernetes in public clouds, we need to understand the behavior of our system across all aspects, not just one.
 Honestly, we’re monitoring to keep our users happy. We need a way to measure the occurring “happiness” as the system moves in real-time. This isn’t about tracking a single journey through the application; it’s about tracking the continued customer journey through your application and understanding the impact of changes.
Honestly, we’re monitoring to keep our users happy. We need a way to measure the occurring “happiness” as the system moves in real-time. This isn’t about tracking a single journey through the application; it’s about tracking the continued customer journey through your application and understanding the impact of changes.
Philosophically, we can say that the customer’s view on success and happiness is singular. They care about the request, its success or failure and its duration. Again, it’s a singular point of view, this request at this time. We live in an instant gratification society. An oft-maligned study from Microsoft says the human attention span is 8 seconds. A Google study on mobile page time and its impact on bounce rates that as simple page load times approach 5 seconds, bounce rates approach 90%. People dislike being bored, and waiting, especially in our digital age, is boring. Boring never wins.
However, the typical DevOps engineer’s view is over a workload. They care about the requests, with the also plural latencies, rates and the amount of concurrency. They also need the underlying system resources and associated components behavior. Aggregation is the go-to model here, and often RED (Rate, Errors, Duration) is the chosen monitoring approach.
These are related but not the same. And the ability to disaggregate from our metrics to our traces is crucial. Our customers are interested in their experience, where our DevOps engineer is interested in the overall performance. Neatly enough, observability gives us the capacity to do both, with the appropriate data retention in place.
Observability is what gets our data in place; it's the attribute of a system that gives us the state information that allows us to track and infer the behavior with the system. That data is generally defined into three pillars of data and signals, metrics, traces and logs. That data allows us to look at the infrastructure components as well as the application components. And in a system where the data is complete, often called full-fidelity data, we can see all the into the individual behavior of a request.
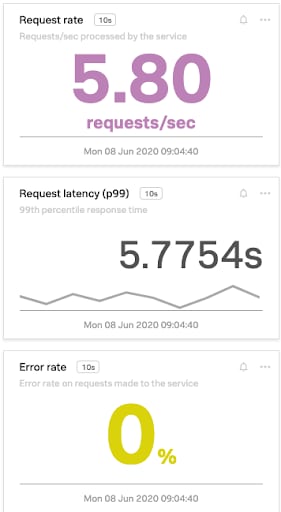 Here’s a RED example. It shows requests averaging 5.8 requests per second over the last ten seconds. It also shows that all of the requests have completed successfully. So the system is handling requests and completing successfully. And from an operations view, it looks like the system is behaving pretty well.
Here’s a RED example. It shows requests averaging 5.8 requests per second over the last ten seconds. It also shows that all of the requests have completed successfully. So the system is handling requests and completing successfully. And from an operations view, it looks like the system is behaving pretty well.
But it shows a duration over 5 seconds on average over the last ten seconds. Given a normal distribution curve, this is likely not good for at least one of the customers. So our observability data is telling us that there is likely some level of customer unhappiness creeping into the system.
But with our distributed tracing data, we can take a look at a specific trace. In this case, we dug into one of the long duration traces and can find that we have a timeout problem.
With our deeper cardinality, we can also spot a likely cause. Look closely at the tags and spot the one labeled “userId”. If you look at the value for it, you’ll see it is a space (“ “). Our system, for some reason, has passed an empty field.
And with this information, we can jump into the specific log files for the service of interest and discover what is going on. Maybe it’s a mishandled invalid "userId". Maybe it’s a lookup glitch. The logs will help us uncover the answers, now that our metrics and traces have helped determine what and where things are going wrong.
It’s worth noting that this approach is most successful when you have access to all the data, often called full-fidelity trace (and metric) data. Systems that sample or restrict access to data (such as looking for failures or outliers) would miss the impact and potentially not even allow you to determine the specific event.
So keep in mind that user happiness is driven by the request success or failure and its duration. Make use of observability data to provide a proxy of user happiness through monitoring metrics with dashboards like RED. Drop into distributed tracing to understand the complete user experience, both in a single transaction and over time. And use logs to help determine the best way to resolve underlying issues to keep those users smiling.
----------------------------------------------------
Thanks!
Dave McAllister

The Splunk platform removes the barriers between data and action, empowering observability, IT and security teams to ensure their organizations are secure, resilient and innovative.
Founded in 2003, Splunk is a global company — with over 7,500 employees, Splunkers have received over 1,020 patents to date and availability in 21 regions around the world — and offers an open, extensible data platform that supports shared data across any environment so that all teams in an organization can get end-to-end visibility, with context, for every interaction and business process. Build a strong data foundation with Splunk.

Get the latest articles from Splunk straight to your inbox.
© 2005 - 2024 Splunk Inc. All rights reserved.
