
Digital Resilience Pays Off
Download this e-book to learn about the role of Digital Resilience across enterprises.

There are several reasons why organizations in every industry are adopting microservices architectures. Working alongside hundreds of customers who are well ahead on the path to microservices, we have observed the top three benefits of these architectures:
According to IDC, microservices when combined with DevOps and agile methodologies will enable enterprises to dramatically accelerate their ability to push out digital innovation – at 50-100 times (or more) the frequency of traditional approaches and by 2022, 90% of all apps will feature microservices architecture.
While it is universally accepted that a microservice architecture provides increased agility and resiliency, it also brings increased operational complexity due to the distributed nature of microservices. Unlike monoliths with unitary application logic, microservices spread the application logic across multiple services where every service adds a network dependency. The successful execution of the application logic is now embedded in the network data flow between these services.
The distributed nature of microservices makes monitoring and debugging workflows challenging:
These questions are easy to answer in a monolithic world, but microservices architectures can bring an SRE team to a halt without a new monitoring approach.
Fundamentally, a service mesh is a policy-driven proxy layer that channels all communication between microservices. Service meshes such as AWS App Mesh, incorporate a sidecar proxy with each instance of a microservice application. Each application communicates only with its local sidecar proxy, and in turn, the proxies communicate among themselves to form a mesh of services.
App Mesh uses Envoy, an open-source project that is governed by Cloud Native Computing Foundation (CNCF), as the data plane sidecar. Envoy intercepts all inbound and outbound network traffic and automatically implements cross-cutting concerns such as service discovery, capturing performance data, encrypting packets, traffic routing, authentication etc. The applications themselves never have to implement these common requirements, or even be aware that something interesting is being applied to the data. As shown in the following figure, application developers can focus on business logic and offload undifferentiated heavy-lifting to the service mesh.
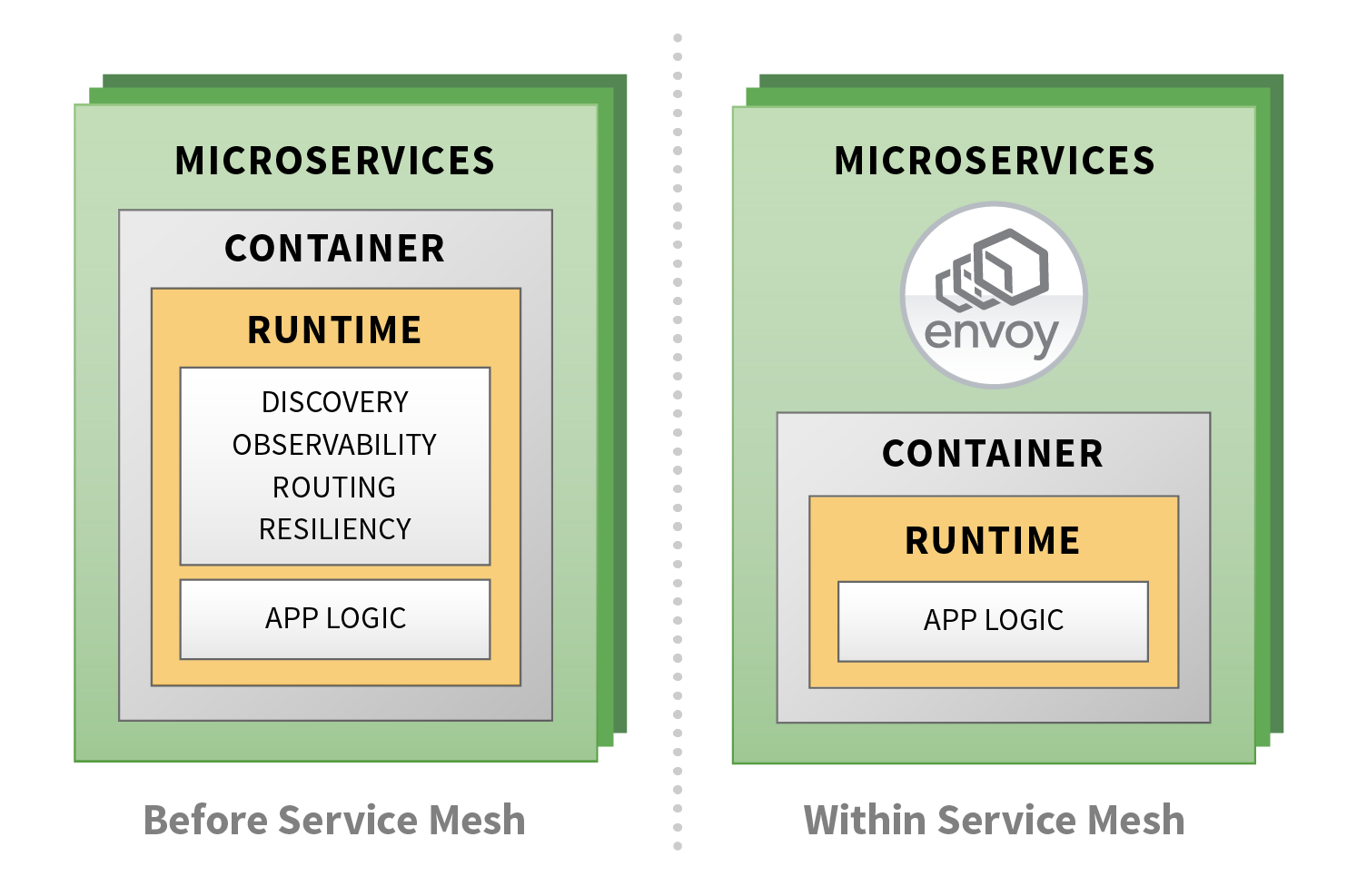
AWS App Mesh provides the logical control plane to configure and enforce policies for all of the running data planes in the mesh.
As AWS App Mesh reaches general availability today, we are excited to introduce the Splunk Infrastructure Monitoring integration for AWS App Mesh. This integration allows joint customers to easily plug the Splunk Infrastructure Monitoring platform in App Mesh deployments. Our partnership with AWS already allows customers to monitor a wide range of AWS services such as EC2, ECS, EKS, S3, EBS, AWS Lambda, DynamoDB, RDS and many more. We are excited to add support for App mesh right from the start.
Splunk Infrastructure Monitoring can seamlessly ingest microservices performance metrics and distributed traces from App Mesh to give you a complete view of the system performance from a single platform:
Customers get visibility and accurate alerting on the performance of their microservices without having to make any change to their application code.
Splunk Infrastructure Monitoring's integration with App Mesh automatically captures metrics and traces and provides pre-built service dashboards with accurate performance characteristics such as request rate, error, and duration (RED metrics). Service owners can quickly visualize how their services are performing and create precise alerts to quickly respond to system-wide performance issues.
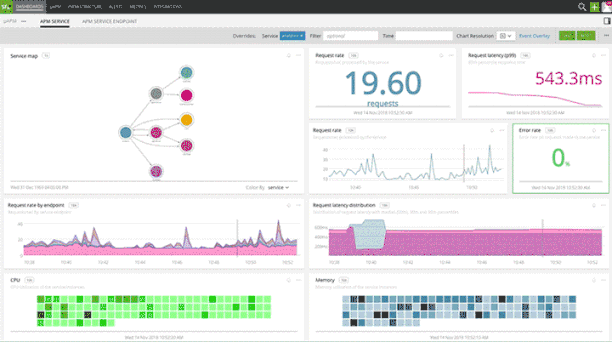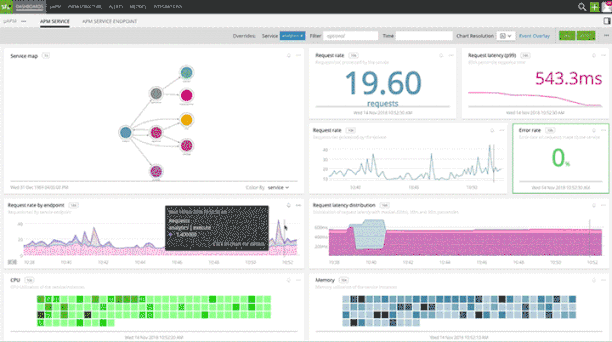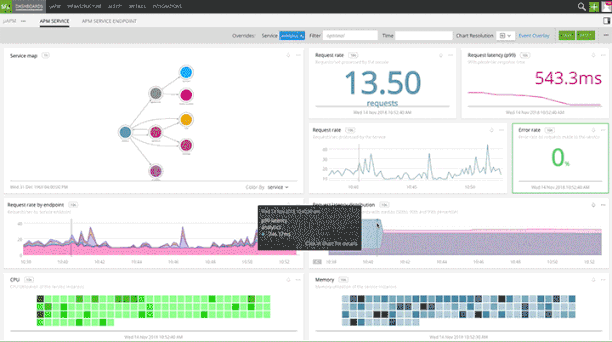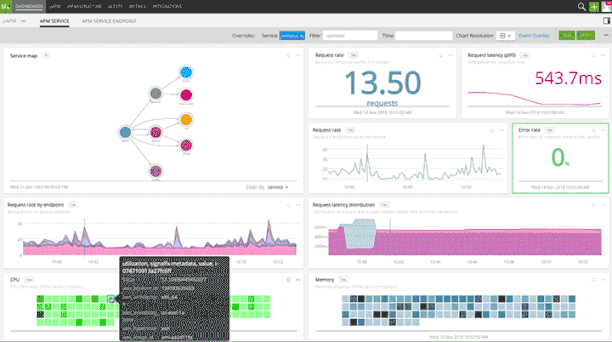
When services are instrumented with distributed tracing context propagation, for SREs and platform observability teams, Splunk Infrastructure Monitoring provides pre-built, dynamically-generated service maps for instant visibility into service interactions and dependencies. Splunk Infrastructure Monitoring service maps enable quick isolation of slow services for expediting root cause analysis.
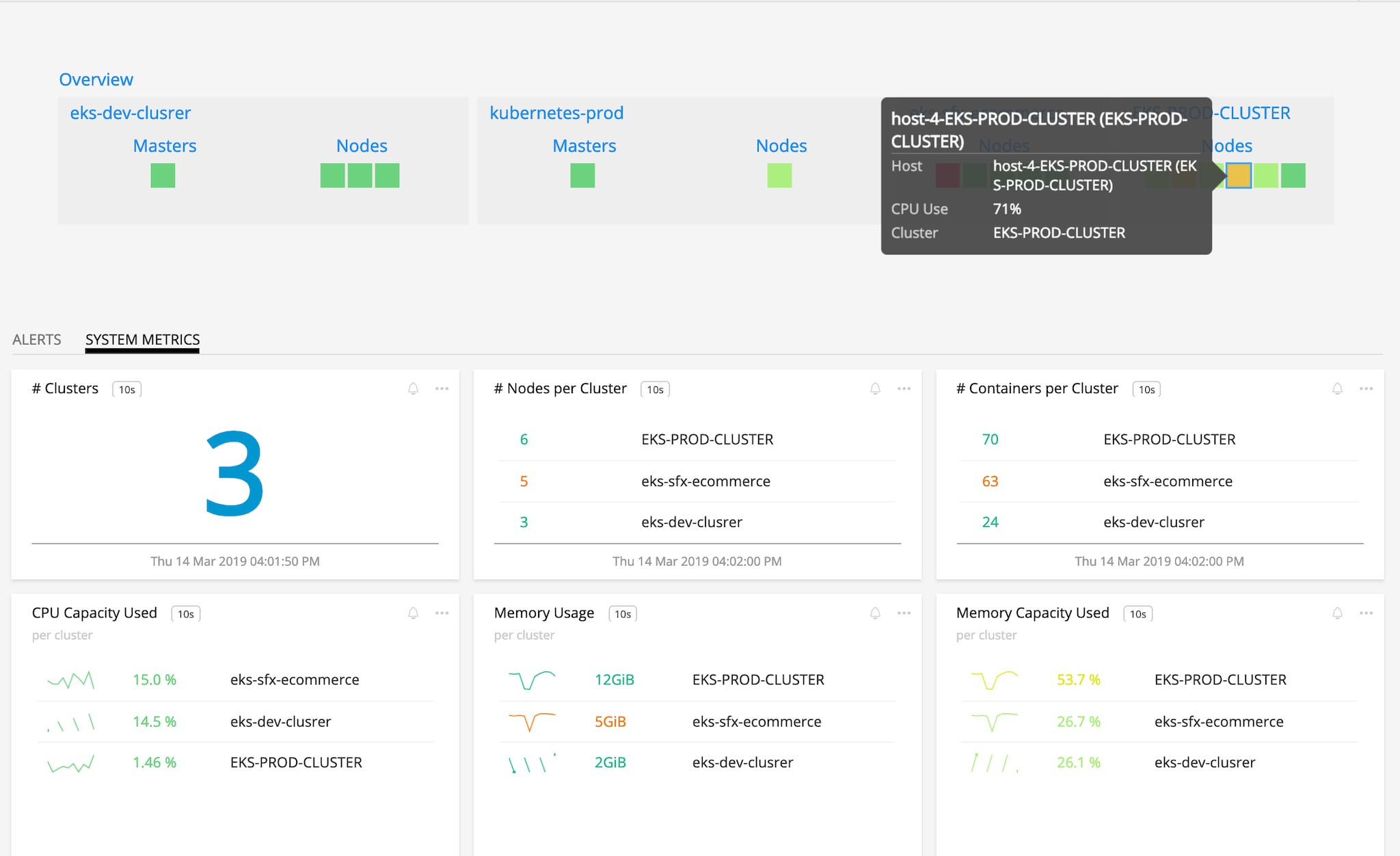
Splunk Infrastructure Monitoring reduces MTTR and enables DevOps practices by having a single source of truth across infrastructure, Kubernetes platform, and deployed microservices.
Splunk Infrastructure Monitoring provides unified monitoring for AWS infrastructure, Kubernetes platform, App Mesh data plane – Envoy, Docker containers and microservices from a single-pane-of-glass. Whether you deploying App Mesh in Amazon EKS, ECS or Kubernetes on EC2, Splunk Infrastructure Monitoring provides comprehensive full-stack monitoring.
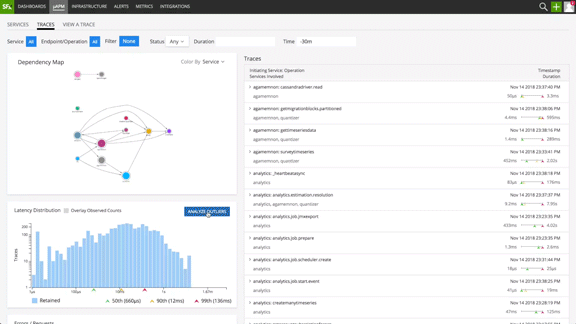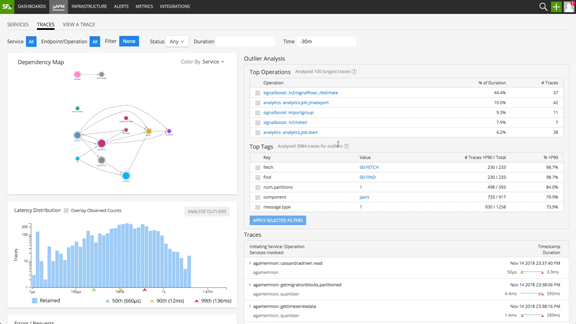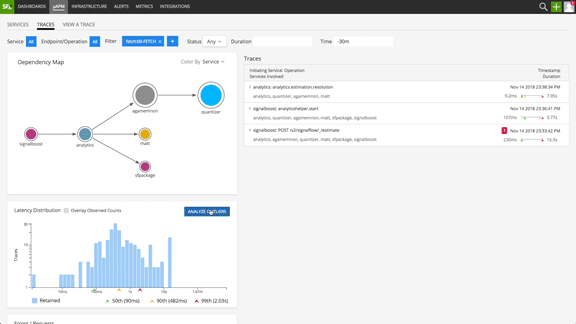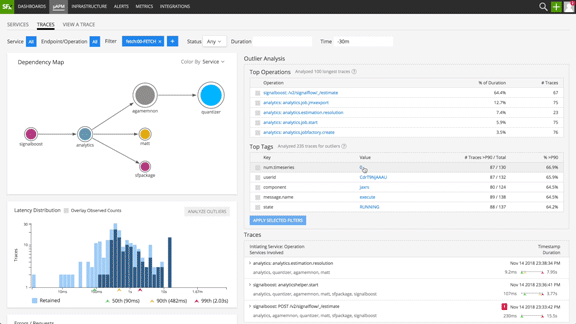
Traditional APM solutions use random sampling of data exported from App Mesh, thereby missing key insights as they analyze only the subset of data. Splunk Infrastructure Monitoring NoSample™ architecture analyzes every transaction exported by App Mesh and intelligently captures anomalous transactions so that you never miss outliers even the extreme P 99 ones. It also ensures that your real-time service dashboards and alerts are always accurate instead of approximations.
With minimal instrumentation, needed for trace context propagation, Splunk Infrastructure Monitoring Outlier Analyzer™ simplifies the troubleshooting process by automatically capturing trace data, and uncovering patterns in anomalous traces, thereby enabling SRE teams with prescriptive troubleshooting to reduce MTTR.
The concept of canary deployments in software release methodologies is inspired by ‘canary in the coal mine’. British miners would take canaries to the coal mine as the birds are more susceptible to dangerous gases than humans. If canary faints, humans would get out of the mine quickly.
Canary deployment has parallels. When a new version of an application is released, only a small portion of users are directed to that version. Perhaps only beta customers who were briefed about the new feature, or users from a particular geography, or just internal employees are directed to the canary version. Everyone else sees the stable version. Service Level Indicators (SLIs) are monitored, and if SLIs of canary indicate better performance than stable version then traffic is gradually increased to the canary version until the whole user population is switched.
The question then arises how can we route traffic dynamically? Implementing canary logic in the application code is an anti-pattern as it would take un-necessary cycles from developers to implement traffic routing.
Traffic routing can be implemented at the load balancer but LBs lack the application context to intelligently determine how to shape traffic. In addition, if agile DevOps practices and CI/CD capabilities are used then organizations would be shipping code multiple times every week or even every day. Manually updating load balancer policies is not sustainable.
Service meshes such as AWS App Mesh, by the virtue of intercepting ingress and egress traffic, can be leveraged to implement dynamic traffic routing.
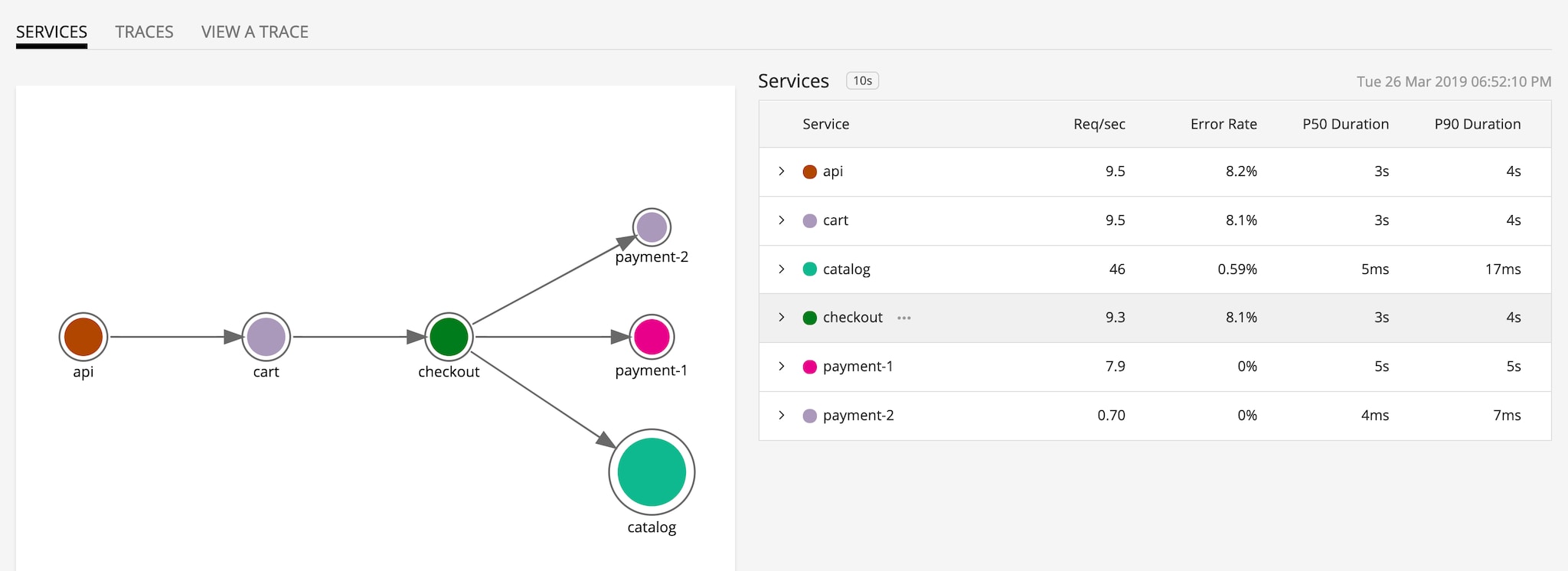
The figure above shows a microservices-based application deployed on AWS App Mesh. Payment service has two versions – payment 1 is stable, and payment 2 is canary.
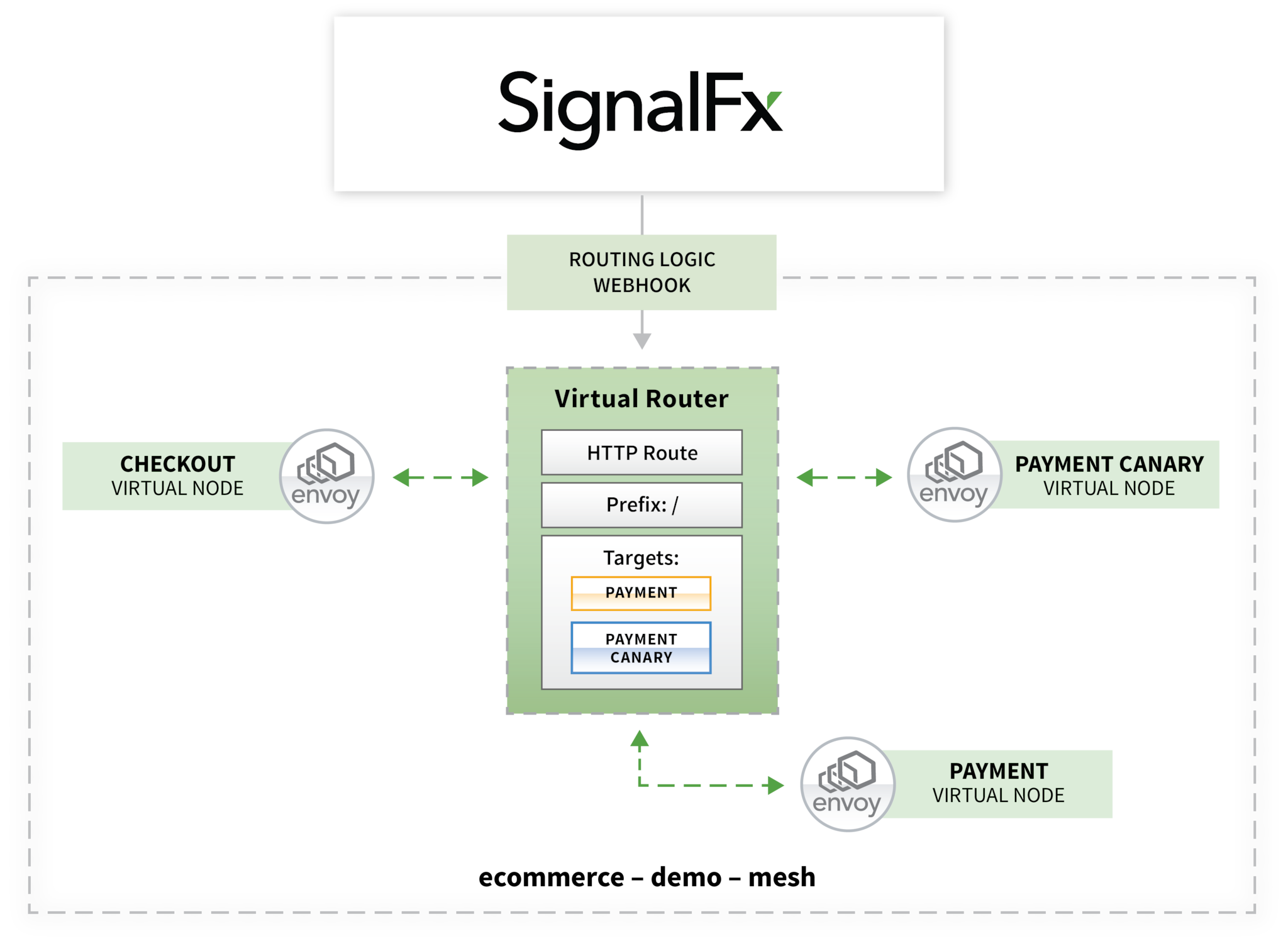
Splunk Infrastructure Monitoring's integration with AWS App Mesh can provide closed-loop automation to intelligently route traffic to canary or stable versions. Customers can define the logic for traffic shaping based on performance metrics. Within App Mesh every service has a Virtual Router to handle traffic between different version of the services deployed. Splunk Infrastructure Monitoring evaluates accurate performance characteristics and dynamically updates Route weights by calling AWS App Mesh APIs via a webhook.
Service meshes can be a critical part of your observability strategy as they provide a consistent way to capture performance data. Splunk Infrastructure Monitoring is the only solution which analyzes every transaction from AWS App Mesh, provides out-of-the-box visibility, real-time monitoring and precise alerting on microservices performance. Once outlier transactions are identified, Splunk Infrastructure Monitoring provides directed troubleshooting to quickly determine the root cause and significantly reduce MTTR.
Get started by signing up for a free trial of Splunk Infrastructure Monitoring or join our obeservability demo to see the platform in action
----------------------------------------------------
Thanks!
Amit Sharma

The Splunk platform removes the barriers between data and action, empowering observability, IT and security teams to ensure their organizations are secure, resilient and innovative.
Founded in 2003, Splunk is a global company — with over 7,500 employees, Splunkers have received over 1,020 patents to date and availability in 21 regions around the world — and offers an open, extensible data platform that supports shared data across any environment so that all teams in an organization can get end-to-end visibility, with context, for every interaction and business process. Build a strong data foundation with Splunk.

Get the latest articles from Splunk straight to your inbox.
© 2005 - 2024 Splunk Inc. All rights reserved.
