
Digital Resilience Pays Off
Download this e-book to learn about the role of Digital Resilience across enterprises.

Microservices have delivered on the promise of freeing up individual teams to work on services independent of one another. This flexibility has allowed for quicker and more agile application development. However, the explosion of services has added complexity to debugging efforts. The task of managing complex interactions between tens or hundreds of microservices turns on-call incident resolution into an absolute nightmare, not to mention the risk of a bad customer experience.
As our environments and SLA (service-level agreement) expectations evolve, our processes and observability tools must evolve with them. Rote tasks such as code rollbacks and auto-scaling of compute resources can now be automated away for increased responsiveness, customer satisfaction and SLA compliance. As a result, developers and operators can focus on more critical tasks while also increasing their productivity. As an industry we need to eliminate situations where on-call staff have to be interrupted from their current tasks or woken up at 3am to fix an easily automatable task.
"Toil is manual, repetitive, automatable, tactical work that scales linearly and is the main source of concern for SREs (Site Reliability Engineers). 59% believe there is too much toil in their organization and not enough has been automated to reduce that toil."
— 2019 State of SRE Report, Catchpoint
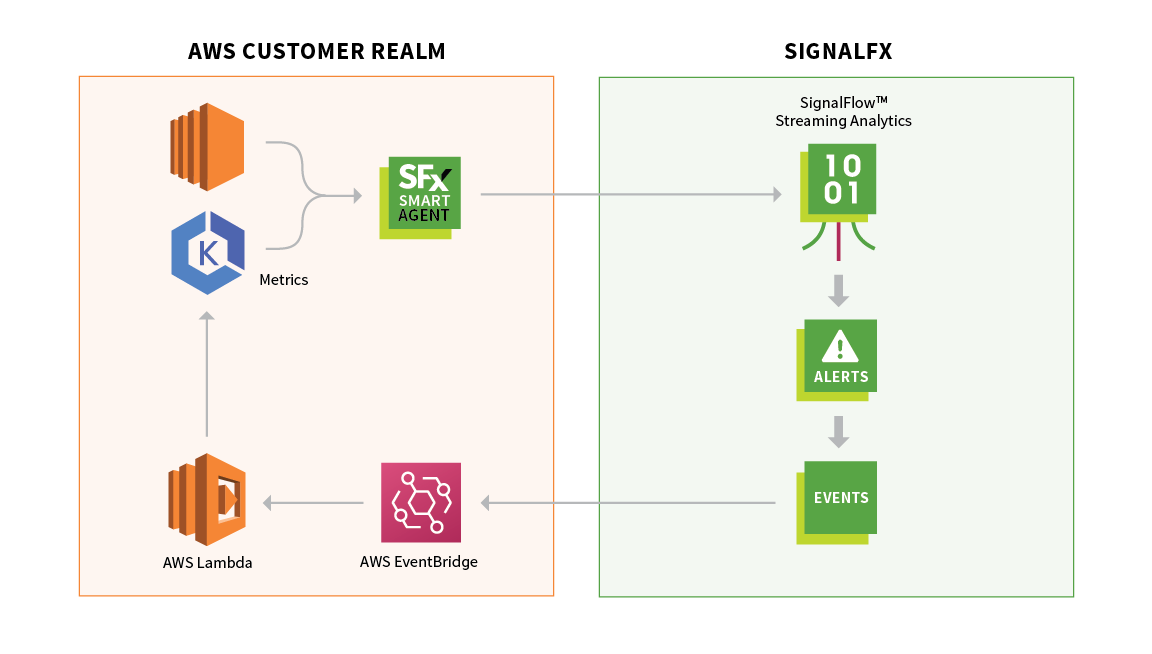
We are excited to be an official launch partner of Amazon EventBridge. This new integration makes it simple to leverage the real-time problem detection capabilities of Splunk Infrastructure Monitoring to automate remediation actions. DevOps and SRE teams can now fully realize the promise of programmable infrastructure through closed-loop automation.
Amazon EventBridge is a serverless event bus that connects applications together, delivering a stream of real-time data from AWS resources, SaaS applications, and data from your own applications. With this new integration, joint customers of Splunk Infrastructure Monitoring and AWS will be able to operate their infrastructure and applications with continuous closed-loop automation to improve responsiveness, SLA compliance, customer experience, and the overall productivity of DevOps and SRE organizations.
Historically, there have been three significant barriers to proactive closed-loop event response in IT Automation:
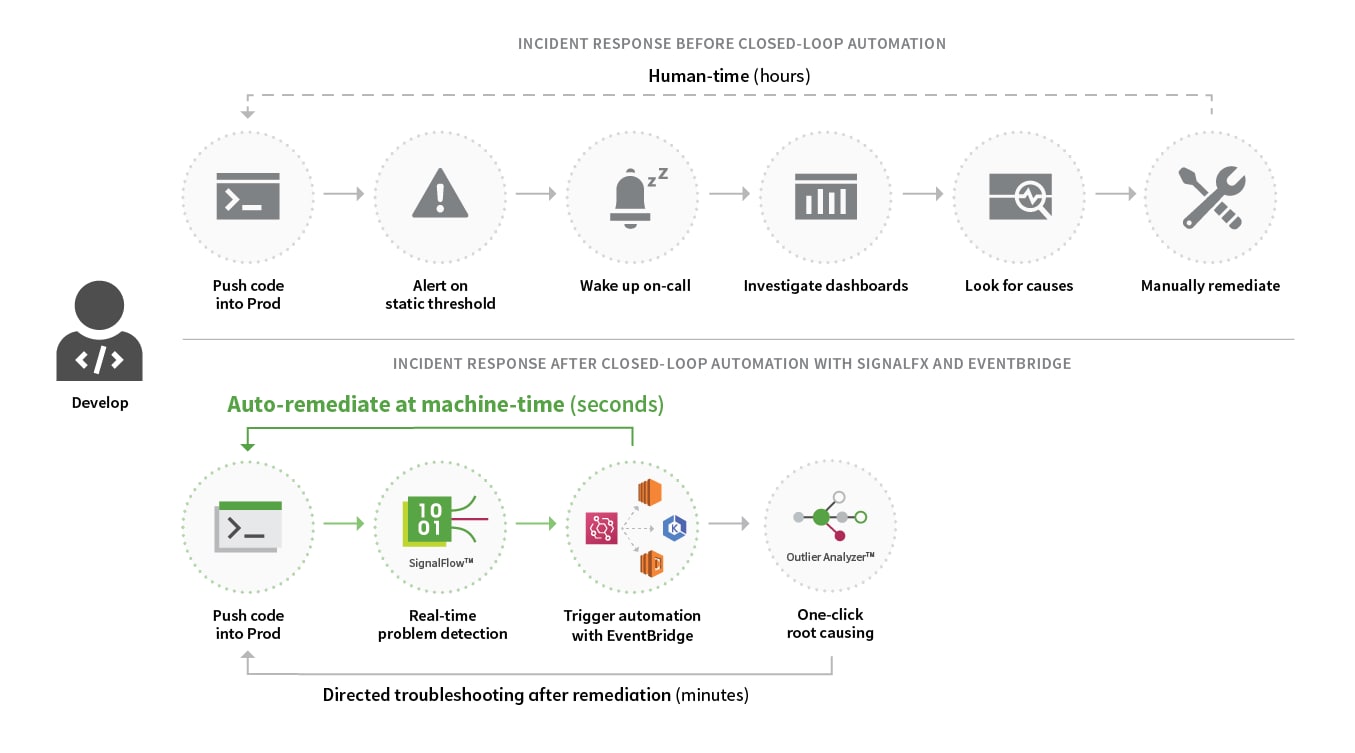
Traditional incident response has been reactive rather than proactive. The common solution has been a one-off script or a large, general purpose tool that nobody wants to maintain. You either page someone or try to uncover the bug yourself.
With Splunk Infrastructure Monitoring and Amazon EventBridge, the benefits are indeed a breakthrough. What took minutes, if not hours, to get actionable responses from traditional observability tools, the Splunk Infrastructure Monitoring real-time streaming analytics architecture processes even the most sophisticated alert detectors within seconds. The SignalFlowTM analytics engine, at the core of the Splunk Infrastructure Monitoring observability platform, is uniquely equipped to address the complexity and volume of data that modern environments impose. Thanks to patented data science SignalFlowTM creates a dynamic view of the environment and identifies true outlier conditions in seconds.
Amazon’s EventBridge interface completes the picture, providing an advanced, scalable dispatch system capable of routing and handling events at any scale. Now, your systems can react in seconds so that the incident response is underway before a human could even realize something needs attention. After the incident is already remediated, you can then start to troubleshoot. Splunk Infrastructure Monitoring's Outlier AnalyzerTM enables rapid root-causing. By analyzing every single transaction across your microservices and correlating across your application code and infrastructure it isolates your problem with one click.
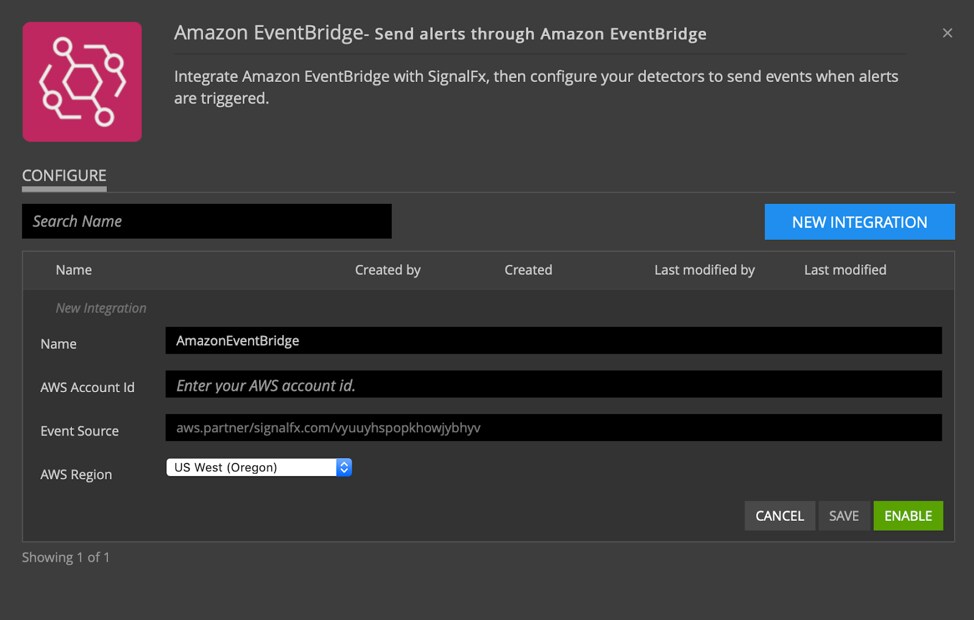
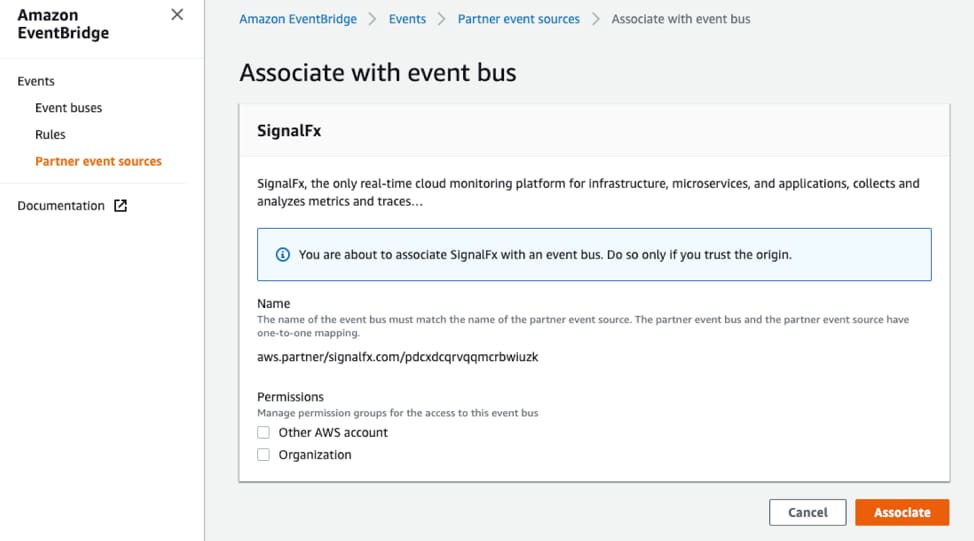
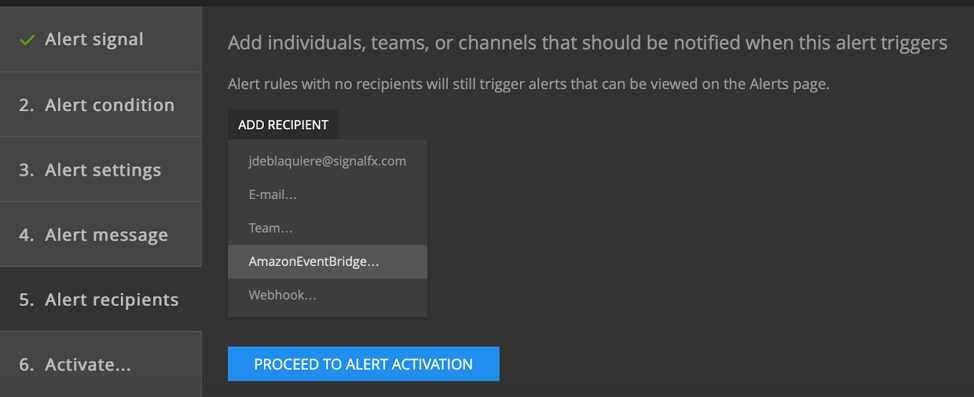
That’s all you need to do to get events flowing into AWS!
Learn more about Splunk Infrastructure Monitoring and get a 14-day free trial.
Happy Splunking,
Ryan Powers

The Splunk platform removes the barriers between data and action, empowering observability, IT and security teams to ensure their organizations are secure, resilient and innovative.
Founded in 2003, Splunk is a global company — with over 7,500 employees, Splunkers have received over 1,020 patents to date and availability in 21 regions around the world — and offers an open, extensible data platform that supports shared data across any environment so that all teams in an organization can get end-to-end visibility, with context, for every interaction and business process. Build a strong data foundation with Splunk.

Get the latest articles from Splunk straight to your inbox.
© 2005 - 2024 Splunk Inc. All rights reserved.
