
Digital Resilience Pays Off
Download this e-book to learn about the role of Digital Resilience across enterprises.


This is part 2 of a two-part series on calculating and using anomalies to get answers from your data.
You can view Part 1 here.
I love chocolate. Chocolate's the flavor that overwhelms everything else. When you don’t have a ground truth to target with supervised machine learning—when you're just looking for behaviors without having a preconceived idea of what you are going to find—you can always count on chocolate...I mean, dimensional behaviors from clustering. Okay, and chocolate. Good for any crisis.
This is all about the density of chocolate. Some chocolate ice cream has chips, some has swirls, some has fudge—the density of chocolate is highly correlated to your behavior when eating said chocolate; in my case, that behavior is some density of joy. So what if I want to use chocolate-flavored anomalies (unsupervised machine learning) to find behavior anomalies?
Imagine going into an ice cream store with 101 flavors of chocolate ice cream (trademark!). You are looking for which groups of ice cream are most similar based on a whole bunch of criteria—Cocoa percentage, milk fat density, character length of brand name, whatever—and at first, you want to be very inclusive with your grouping. So you set DBSCAN’s eps parameter to say eps=1, and you find that all chocolate ice creams are very similar and in one or two groups (cluster 1, cluster 2), and there are a few anomalies—i.e., white chocolate (cluster -1) .
I’m a chocolate snob, so when I go into the ice cream store with 101 flavors of chocolate ice cream and look for flavour groups, I use DBSCAN with eps=0.3. I get many clusters with few ice cream flavors in each one because I want strictly similar flavors only to be grouped together (clusters 1,2,3,4…). I end up with more anomalies (cluster -1). Discovered Anomalies (cluster -1) do not fit in any group because I desire strictly specific similarities in my grouping criteria. None of my anomalies (cluster -1) flavors will be similar to any other flavor group, or to any other anomaly flavors, because I was very strict in my similarity criteria.
In the webstore, I'm looking for unknown anomalies in my customers' and IT behaviors through the systems. Do have I unknown anomalies when a user makes a POST action from an iPhone trying to put dark roast coffee into their cart? I have no idea and I don’t want to take the time to measure every possible dimension; I just want to have machine learning actually LEARN the density of my data and then I will look at how much chocolate is in each density/cluster. Er, I mean look at the behaviors of my users, systems, and products...I’m thinking about chocolate too much.
index=demo sourcetype="apache:access" response_time!=0 |eval action=if(isnull(action),"null",action) |eval base_action=if(isnull(base_action),"null",base_action) | table _time, response_time,base_action,date_hour,date_wday,action,device,http_method,request_bytes,response_bytes,web_server | eval newid=action.".".base_action | eval date_hour=date_hour."_" |eval this_day=date_wday | streamstats window=10 avg(response_time) as trend_responsetime current=f by newid | search trend_responsetime=* | eval device=coalesce(device,"Null") | fit StandardScaler "response_time" "request_bytes" "response_bytes" "trend_responsetime" | fit PCA k=3 SS* "device" "http_method" "web_server" "newid" "date_hour" | fit DBSCAN eps=0.5 PC*
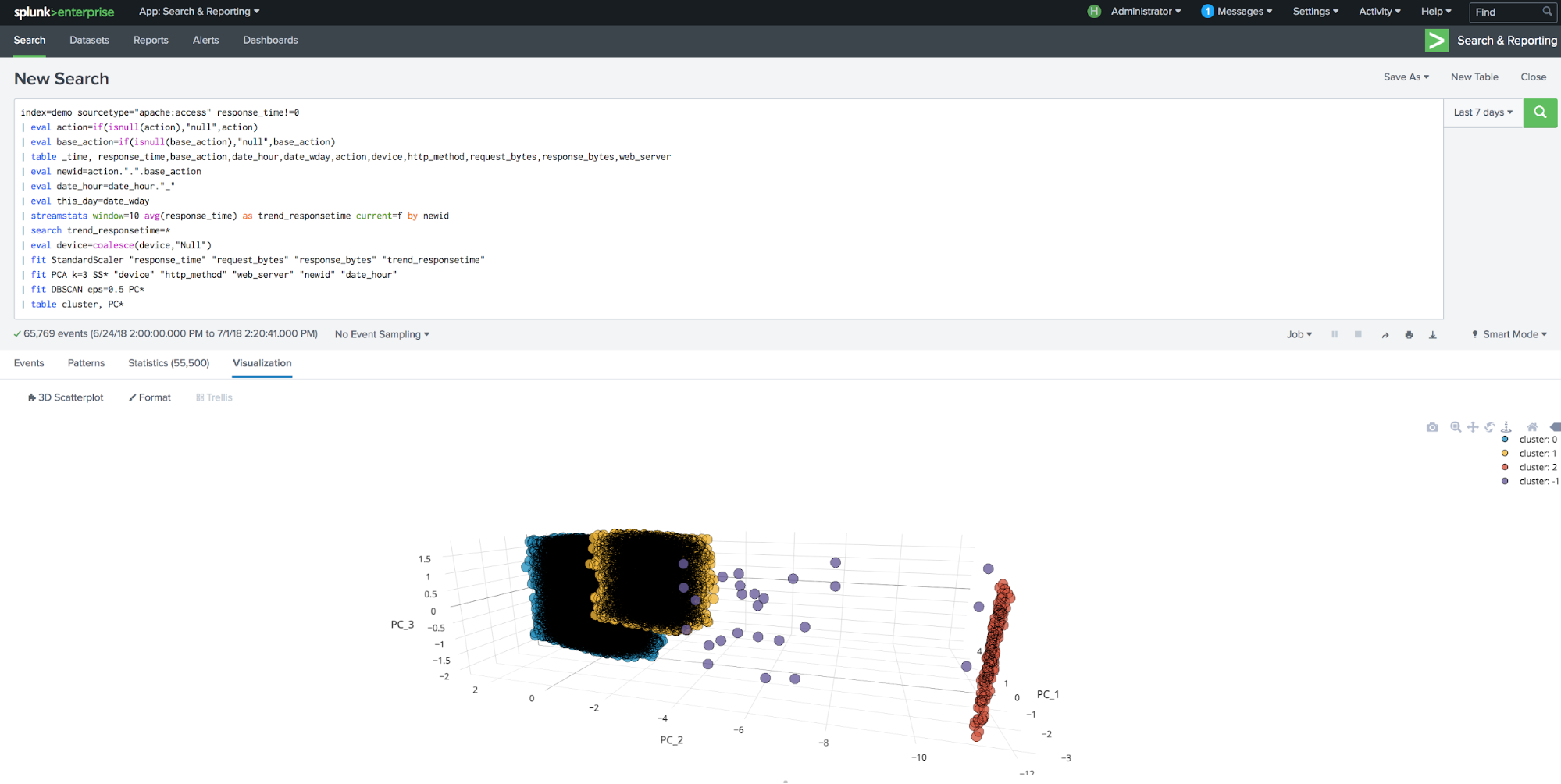
In the above search, PCA can discover collinearity among categorical variables and remove those that are not as informative.
To reproduce this visual, make sure to download the 3D Scatterplot - Custom Visualization app from Splunkbase and add the following line to the above search:
| table cluster, PC*
We can see the behaviors, but we don’t understand how those clusters are “different” or similar. For that we need to use a little vanilla on the last line of that search—Descriptive Statistics!
| stats count avg(response_time) max(response_time) min(response_time) avg(trend_responsetime) values(device) values(http_method) values(web_server) values(newid) values(date_hour) values(this_day) by cluster
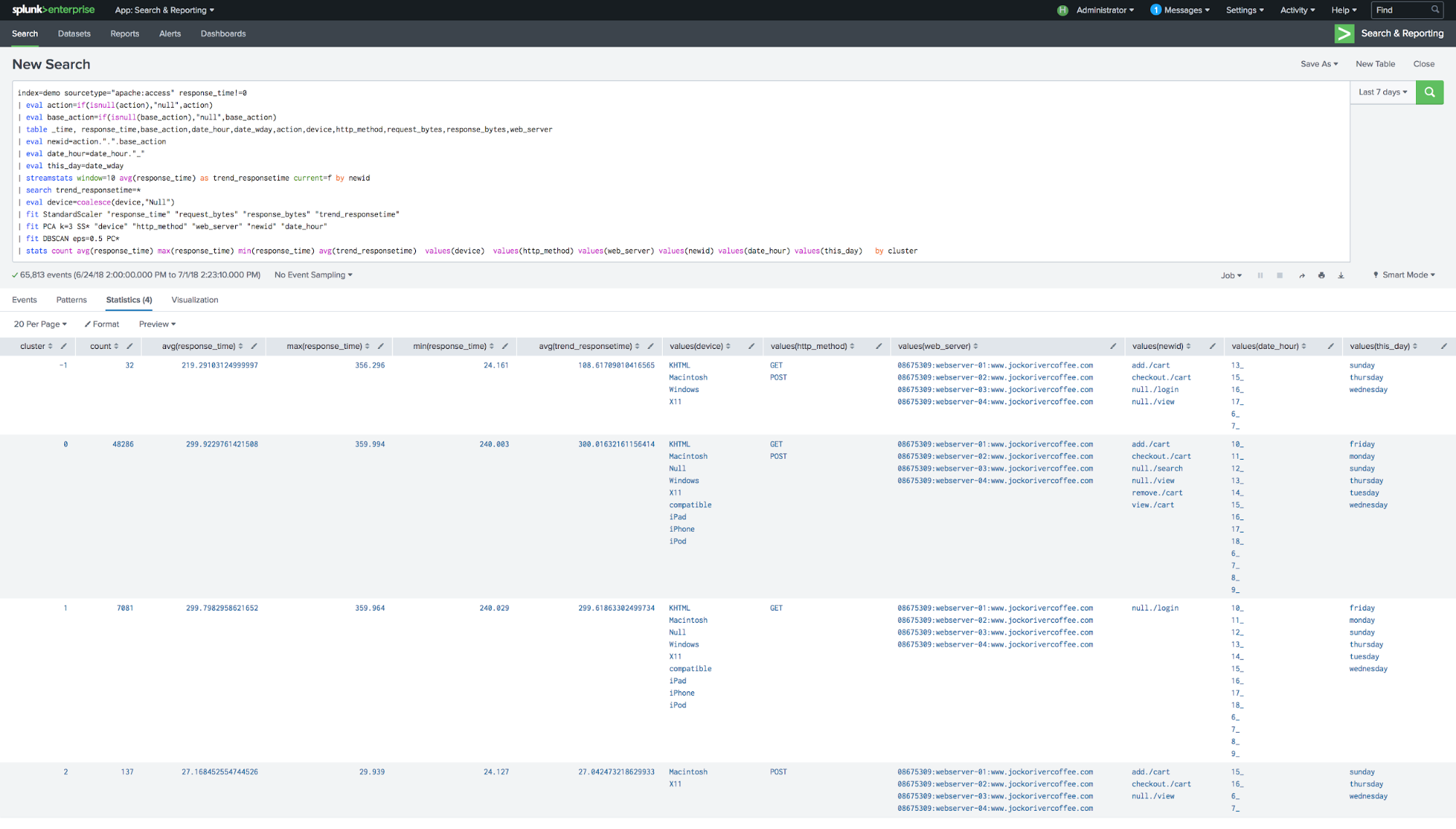 What am I looking at? Not chocolate ice creams, sadly. I've cracked open the discovered anomalies and discovered groups, and I'm comparing what the behaviors are that in each group. I can drill into just the anomaly cluster and really investigate the 32 events that are anomalous instead of looking at all 65k+ events; or if a group has some odd business qualities—maybe some security issues perhaps—I can focus on just the events in that group.
What am I looking at? Not chocolate ice creams, sadly. I've cracked open the discovered anomalies and discovered groups, and I'm comparing what the behaviors are that in each group. I can drill into just the anomaly cluster and really investigate the 32 events that are anomalous instead of looking at all 65k+ events; or if a group has some odd business qualities—maybe some security issues perhaps—I can focus on just the events in that group.
DBSCAN is a powerful algorithm that can’t be saved into a model state, meaning that I have to fit DBSCAN every time I want to get insight and that slows down my chocolate consumption...I mean slows down getting answers from my data. Ya, that.
 How About a Scoop of All Three Flavors in One Awesome Scoop?
How About a Scoop of All Three Flavors in One Awesome Scoop?What if I want to scoop across like a monster? Why have one flavor when you can have all three? No beautiful margins or differentiation between the three flavors, just one scoop of awesomeness.
I'm going to get around the limitation of DBSCAN, the lack of a model file and inability to use the |apply step, by combining some strawberry-flavored math—classification. Very similar to the regression workflow above, we are using the algorithms found in Predict Categorical Fields—they look just like Regressors, but instead of predicting a number, they predict a label. In this case, the label is the cluster discovered by DBSCAN.
I’m already eating my ice cream like a monster—combining all three flavors in every scoop, ruining it for the purists—so let’s also create three types of clusters. I want anomalies from specific similarity criteria, from assuming everyone should be very similar (large EPS), somewhat similar (middle range EPS), and strictly similar only (small EPS).
index=demo sourcetype="apache:access" response_time!=0 | table _time, response_time,base_action,date_hour,date_wday,action,device,http_method,request_bytes,response_bytes,web_server | eval newid=action.".".base_action | eval date_hour=date_hour."_" | streamstats window=10 avg(response_time) as trend_responsetime current=f by newid | search trend_responsetime=* | eval device=coalesce(device,"Null") | fit StandardScaler "response_time" "request_bytes" "response_bytes" "trend_responsetime" into my_new_StandardScaler_model | fit PCA k=3 SS* "date_hour" "device" "http_method" "web_server" "newid" into my_new_PCA_model | fit DBSCAN eps=0.3 PC* |eval NotSimilar=cluster | fit RandomForestClassifier NotSimilar from PC* "newid" into my_new_cluster_model_NotSimilar | fit DBSCAN eps=0.5 PC* |eval Similar=cluster | fit RandomForestClassifier Similar from PC* into my_new_cluster_model_Similar | fit DBSCAN eps=0.7 PC* |eval VerySimilar=cluster | fit RandomForestClassifier VerySimilar from PC* into my_new_cluster_model_VerySimilar
We can now predict the cluster of behavior as an output of RandomForestClassifier, without the need for DBSCAN until we want to learn new behaviors on new data. We just repeat the |fit sequence again on a scheduled search every seven days for example.
How do I apply these models to new data with the |apply step?
index=demo sourcetype="apache:access" response_time!=0 | table _time, response_time,base_action,date_hour,date_wday,action,device,http_method,request_bytes,response_bytes,web_server | eval newid=action.".".base_action | eval date_hour=date_hour."_" | streamstats window=10 avg(response_time) as trend_responsetime current=f by newid | search trend_responsetime=* | eval device=coalesce(device,"Null") | apply my_new_StandardScaler_model | apply my_new_PCA_model | apply my_new_cluster_model_NotSimilar as NotSimilar | apply my_new_cluster_model_Similar as Similar | apply my_new_cluster_model_VerySimilar as VerySimilar
Where are our anomalies? We look for cluster -1 in any field or combination of fields (NotSimilar, Similar, VerySimilar)—those are the anomalies by each criteria of similarity.
Add the following to the search above and you can even have them vote (equally weighted in this case):
| table _time, *Similar* | eval Alert_NotSimilar = if (NotSimilar<0,1,0) | eval Alert_Similar = if (Similar<0,1,0) | eval Alert_VerySimilar = if (VerySimilar<0,1,0) | eval Alert_level=Alert_NotSimilar+Alert_Similar+Alert_VerySimilar

If we want to investigate the other clusters, we can! But we need to do one more step…on new data we no longer have the training data to run statistics against. That’s okay, we can still crack open the different clusters from the training set and get to the raw data summarized any way we want, and then bring that intelligence into any subsequent search on new data using only the <code> |apply </code> steps (like alerts).
How?
Good thing we all ready understood the previous series, "Cyclical Statistical Forecasts and Anomalies - Part 1," because….we are using it AGAIN. Even though we are using the <code> |apply </code> step in the next search, we are still using the same training set of data because we want to populate some statistical descriptive lookups to enrich our <code> |apply </code> on brand new data.
index=demo sourcetype="apache:access" response_time!=0 | table _time, response_time,base_action,date_hour,date_wday,action,device,http_method,request_bytes,response_bytes,web_server | eval newid=action.".".base_action | eval date_hour=date_hour."_" | streamstats window=10 avg(response_time) as trend_responsetime current=f by newid | search trend_responsetime=* | eval device=coalesce(device,"Null") | apply my_new_StandardScaler_model | apply my_new_PCA_model | apply my_new_cluster_model_NotSimilar as NotSimilar | apply my_new_cluster_model_Similar as Similar | apply my_new_cluster_model_VerySimilar as VerySimilar | multireport [| stats count by NotSimilar | outputlookup NotSimilar.csv] [| stats count by Similar | outputlookup Similar.csv] [| stats count by VerySimilar | outputlookup VerySimilar.csv]
In the above, I'm simply getting a count of each cluster discovered; I could bring in as many fields from the past as I want—say avg(response_time) or max(trend_responstime). I could even build a continuous summary index of relevant data by using collect instead of outputlookup (see "Cyclical Statistical Forecasts and Anomalies - Part 2").
When I'm examining new data for investigation or alerting, for example, I can use the same |Apply search but now with lookups to enrich the discovered clusters with their statistical behavior data:
index=demo sourcetype="apache:access" response_time!=0 | table _time, response_time,base_action,date_hour,date_wday,action,device,http_method,request_bytes,response_bytes,web_server | eval newid=action.".".base_action | eval date_hour=date_hour."_" | streamstats window=10 avg(response_time) as trend_responsetime current=f by newid | search trend_responsetime=* | eval device=coalesce(device,"Null") | apply my_new_StandardScaler_model | apply my_new_PCA_model | apply my_new_cluster_model_NotSimilar as NotSimilar | apply my_new_cluster_model_Similar as Similar | apply my_new_cluster_model_VerySimilar as VerySimilar | lookup NotSimilar.csv NotSimilar as NotSimilar OUTPUTNEW count as count_NotSimilar | lookup Similar.csv Similar as Similar OUTPUTNEW count as count_Similar | lookup VerySimilar.csv VerySimilar as VerySimilar OUTPUTNEW count as count_VerySimilar
Remember, a cluster number from the 1st DBSCAN and any other DBSCAN isn’t related—just because a row of data is labeled “cluster 1” in both the NotSimilar and VerySimilar doesn’t mean they share any similarity. The only cluster that has universal meaning in this workflow is cluster -1, the anomalies in each similarity criteria.
What do you get from bringing the statistical observations of the clusters from training window (7 days or so) into the |apply step (maybe only 5 minutes of data)? You get context—who wants to be woken up at 2am in the morning for every anomaly? You can score the strength of the anomaly with the lookupdata just like we did in "Cyclical Statistical Forecasts an Anomalies - Part 1."
If you don’t have an ice cream headache from running through these exercises, you may be doing it wrong! Or hopefully you have the ML bug and want to use more—check out the Splunk for Analytics and Data Science class or some of our other tutorials and YouTube videos. I'll be teaching at Splunk University this year just before .conf18—hope to see you there!
Special thanks to Andrew Stein and Iman Makaremi for all the rich content presented in this blog post, and to Anna Drieger for her amazing art that we’re using in this blog post!
----------------------------------------------------
Thanks!
Manish Sainani

The Splunk platform removes the barriers between data and action, empowering observability, IT and security teams to ensure their organizations are secure, resilient and innovative.
Founded in 2003, Splunk is a global company — with over 7,500 employees, Splunkers have received over 1,020 patents to date and availability in 21 regions around the world — and offers an open, extensible data platform that supports shared data across any environment so that all teams in an organization can get end-to-end visibility, with context, for every interaction and business process. Build a strong data foundation with Splunk.

Get the latest articles from Splunk straight to your inbox.
© 2005 - 2024 Splunk Inc. All rights reserved.
