
Digital Resilience Pays Off
Download this e-book to learn about the role of Digital Resilience across enterprises.

|
There are so many ways to eat Neapolitan ice cream; some people eat the vanilla and chocolate and leave a big hunk of strawberry for the end. I scoop across the flavors, like a monster, ruining the experience for purists everywhere.
Similarly, there are many different ways to calculate and use anomalies to get answers from your data. I couldn’t possibly show every permutation, but I can take a single data set and show you how to generate univariate statistical anomalies (vanilla!), multivariate regression anomalies (strawberry!), and dimensional behavioral anomalies (chocolate!).
Much like eating Neapolitan ice cream, you will end up using the techniques in different orders and combinations. At the end of this series we'll scoop across the flavors like a monster, using multiple anomaly detection techniques in one search (although you can of course keep your flavors pure by detecting vanilla anomalies, strawberry anomalies, and chocolate anomalies separately, and then combine them in a glorious ensemble ice cream sundae). Some of you are lactose intolerant and don’t believe in anomalies in your data—I wish you luck...or soy-based alternatives.
Let's start with our data—an Apache Dataset of customers going through a webstore, sometimes buying things, sometimes making a basket and abandoning it, sometimes just browsing and maybe even some bots trying to scrape the store or possible fraud exploits. While this is an example of typical machine data in Splunk, you may have other data formats; the searches we're going to “sample” below can be repurposed for any use. As always, I'm focusing on workflow first—you can lift the math easily enough into your Data Model or Summary Index searches too.
Everything goes with vanilla, and everything starts with statistics. I wrote a 3-part blog series around statistical anomalies using the Splunk Machine Learning Toolkit's Numeric Outlier Detection Assistant, "Cyclical Statistical Forecasts and Anomalies." Let’s take the Median Abs Deviation anomaly option from the Assistant’s dropdown this time, and we can take our base search and use the Assistant to write some SPL for us:

Base Search
index=demo sourcetype="apache:access" response_time!=0 |eval action=if(isnull(action),"null",action) |eval base_action=if(isnull(base_action),"null",base_action) | eval newid=action.".".base_action | eval date_hour=date_hour."_" | table _time,response_time,newid,date_hour
A quick note on the “newid” field: my data is kind of messy and I don’t have a single clear “customer action” field; instead, I have to create an id on the fly based on a combination of other fields. Before I had “./cart” in action and base_action might be “add” or “view," and for login I might not have any action at all, just a base_action. Quickly munging data together to create meaningful ids or net new behaviors for machine learning features is a key strength of SPL.
Place the search above in the assistant, select Median Absolute Deviation, add in the “by” clause box in the fields newid and date_hour. The Assistant writes the following for us:
| eventstats median("response_time") as median by "newid", "date_hour"
| eval absDev=(abs('response_time'-median))
| eventstats median(absDev) as medianAbsDev by "newid", "date_hour"
| eval lowerBound=(median-medianAbsDev*exact(2)), upperBound=(median+medianAbsDev*exact(2))
| eval isOutlier=if('response_time' < lowerBound OR 'response_time' > upperBound, 1, 0)
You can see an explanation for the above SPL in the Assistant by clicking the Show SPL button:

As outlined in the previous blog series, we can persist this sort of anomaly detection via lookups or summary indexes, but we're limited to a single value moving through time and basic statistical scoring. What if we want more?
Sometimes you scoop the Neapolitan ice cream and you get some contamination from other flavors. How can you quickly remove the unwanted flavors from your pure scoop? Well, it's the same thing with anomalies; few companies have significant sets of data without anomalies for machine learning to learn baselines from. A simple solution is to detect the anomalies and remove them before building a model. So let’s remove the Vanilla anomalies:
… | eval new_smoothed_value=coalesce(lowerBound,upperBound,response_time) ------ | eval new_smoothed_value=if(response_time<lowerBound,lowerBound,response_time) | eval new_smoothed_value=if(response_time>upperBound,upperBound,response_time) | eval new_response_time=if(isOutlier=1,new_smoothed_value,response_time) | eval new_smoothed_value=if(response_time<lowerBound,lowerBound, if(response_time>upperBound,upperBound,response_time))
The new field, new_response_time, is a bounded field that will never have a value above the upperBound or below the lowerBound. There are many ways to smooth your univariate data, and this is just one easy way to get the pure scoop of vanilla.
Final Vanilla Search
index=demo sourcetype="apache:access" response_time!=0
| eval action=if(isnull(action),"null",action)
| eval base_action=if(isnull(base_action),"null",base_action)
| eval newid=action.".".base_action
| eval date_hour=date_hour."_"
| table _time,response_time,newid,date_hour
| eventstats median("response_time") as median by "newid", "date_hour"
| eval absDev=(abs('response_time'-median))
| eventstats median(absDev) as medianAbsDev by "newid", "date_hour"
| eval lowerBound=(median-medianAbsDev*exact(2)), upperBound=(median+medianAbsDev*exact(2))
| eval isOutlier=if('response_time' < lowerBound OR 'response_time' > upperBound, 1,0)
| eval new_smoothed_value=if(response_time<lowerBound,lowerBound,response_time)
| eval new_smoothed_value=if(response_time>upperBound,upperBound,response_time)
| eval new_response_time=if(isOutlier=1,new_smoothed_value,response_time)
| stats min(lowerBound) as SmoothedLowerBound max(upperBound) as SmoothedUpperBound by newid,date_hour
|outputlookup StatisitcalSmoothForServerResponseTime.csv
We can see where new_response_time has become a “smoothed," outlier-removed version of response_time.
index=demo sourcetype="apache:access" response_time!=0
| eval action=if(isnull(action),"null",action)
| eval base_action=if(isnull(base_action),"null",base_action)
| eval newid=action.".".base_action
| eval date_hour=date_hour."_"
| table _time,response_time,newid,date_hour
| lookup StatisitcalSmoothForServerResponseTime.csv newid as newid date_hour as date_hour OUTPUTNEW SmoothedUpperBound as SmoothedUpperBound SmoothedLowerBound as SmoothedLowerBound
| eval isOutlier=if('response_time' < SmoothedLowerBound OR 'response_time' > SmoothedUpperBound, 1, 0)
| eval new_smoothed_value=if(response_time<SmoothedLowerBound,SmoothedLowerBound,if(response_time>SmoothedUpperBound,SmoothedUpperBound,response_time))
| eval new_response_time=if(isOutlier=1,new_smoothed_value,response_time)
| table _time, new_response_time,response_time
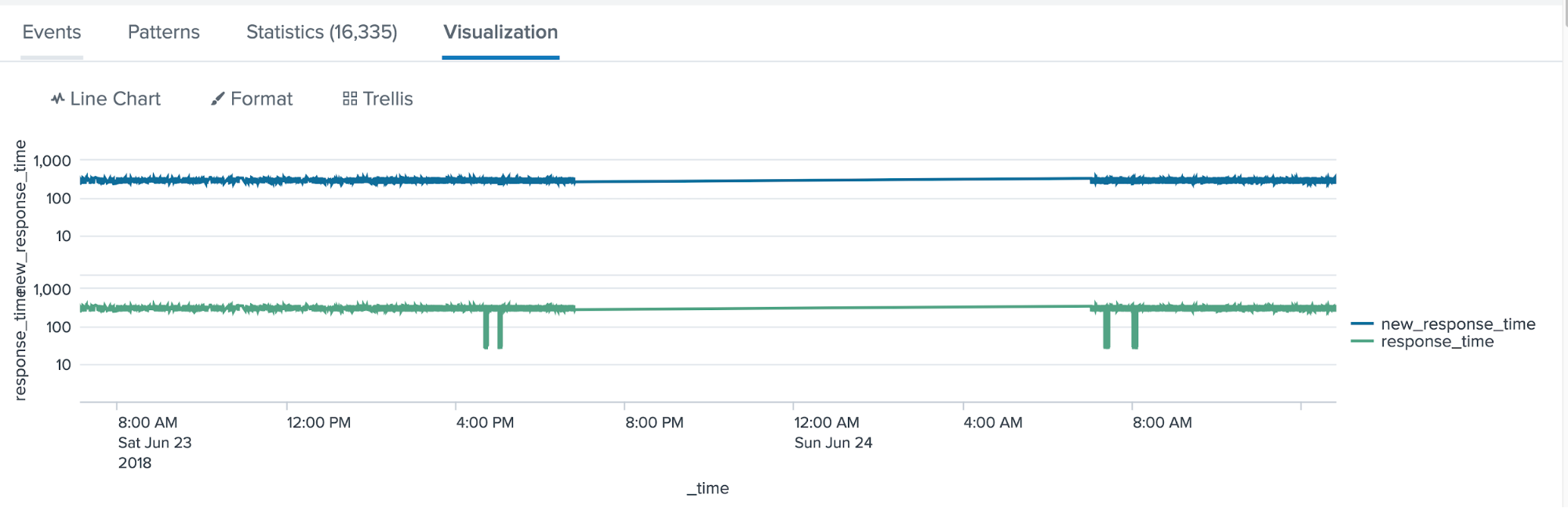
You may be wondering about those eventstats and stats combinations in my search above. Technically, you can be more efficient if you want, but workflow first—get something working and then go back and try to make those searches more efficient if that's of value to your organization. With Splunk, you can quickly build these workflows and change them up later—only the raw data is immutable; the searches are VERY “mutable."
 |
The goal for great strawberry ice cream is balance—icy and creamy, sweet and mild, tangy and smooth. Think of each of those flavor profiles as a field in Splunk and you want to relate all those fields to some ground truth, like the quality of your ice cream. Or maybe setting the target of a Predict Numeric Fields Assistant to service health score as shown in the previous blogs, "ITSI and Sophisticated Machine Learning."
In our example, we're interested in the response time of the system based on time of day and different actions by a user and a host of other interactions to find out when there's an anomalous behavior in our web store; maybe there's a bot scraping our product pages, some sub system is having a poor response time, or we have a new bug on a specific browser on a specific phone OS. How do we even know where the anomalies ARE? We need to find a balance between all the fields we might want to use.
In this base search I've added a new field to tell me about the temporally localized typical response time by customer action (the streamstats command below). I have also added a ton of fields already in my data to the <code> |fit </code> line below:
index=demo sourcetype="apache:access" response_time!=0 |eval action=if(isnull(action),"null",action) |eval base_action=if(isnull(base_action),"null",base_action) | table _time, response_time,base_action,date_hour,date_wday,action,device,http_method,request_bytes,response_bytes,web_server | eval newid=action.".".base_action | eval date_hour=date_hour."_" | streamstats window=10 avg(response_time) as trend_responsetime current=f by newid | fit LinearRegression response_time from date_hour,newid,trend_responsetime,device,http_method,request_bytes,response_bytes,web_server into MyServerModel
Now we can estimate on new data what our expected server response time should be, like so:
index=demo sourcetype="apache:access" response_time!=0 |eval action=if(isnull(action),"null",action) |eval base_action=if(isnull(base_action),"null",base_action) | table _time, response_time,base_action,date_hour,date_wday,action,device,http_method,request_bytes,response_bytes,web_server | eval newid=action.".".base_action | eval date_hour=date_hour."_" | streamstats window=10 avg(response_time) as trend_responsetime current=f by newid | apply MyServerModel as expected_response_time
Yummy strawberry. Looking at statistical anomalies in the residual (from the Assistant) of the model is also good for understanding what additional data sources might be enhance the model. If there's an anomaly in server response time and not in any of the fields I used for the model, then what happened? Where is that anomaly coming from? Where else can I look for data?
Sometimes you get more than one flavor with a scoop and it tastes even better. Ever think about how few companies have a significant set of data without anomalies for machine learning to learn baselines from? How can we get around that? We now have a really interesting way to remove multiple types of anomalies from our training data set and create a real baseline to understand what's the hidden normal.
Thanks to the last line of our vanilla search, we have an easy lookup with upper and lower bounds for what we think response time should be for any hour of day and user action. Remember, if we want to do these at scale or through time, we can use the workflow from my "Cyclical Statistical Forecasts and Anomalies - Part 2" blog post.
index=demo sourcetype="apache:access" response_time!=0
|eval action=if(isnull(action),"null",action)
|eval base_action=if(isnull(base_action),"null",base_action)
| table _time, response_time,base_action,date_hour,date_wday,action,device,http_method,request_bytes,response_bytes,web_server
| eval newid=action.".".base_action
| eval date_hour=date_hour."_"
| streamstats window=10 avg(response_time) as trend_responsetime current=f by newid
| lookup StatisitcalSmoothForServerResponseTime.csv newid as newid date_hour as date_hour OUTPUTNEW SmoothedUpperBound as upperBound SmoothedLowerBound as lowerBound
| eval isOutlier=if('response_time' < lowerBound OR 'response_time' > upperBound, 1, 0)
| where isOutlier!=1
| fit LinearRegression response_time from date_hour,newid,trend_responsetime,device,http_method,request_bytes,response_bytes,web_server into MyServerModel
| eval residual = response_time - 'predicted(response_time)'
Now I have a baseline model, creating a balance between multiple fields, with the anomalies for our target - response_time- removed.
What's next? Check out part 2 of this series.
Special thanks to Andrew Stein and Iman Makaremi for all the rich content presented in this blog post, and to Anna Drieger for her amazing art that we’re using in this blog post!
----------------------------------------------------
Thanks!
Manish Sainani

The Splunk platform removes the barriers between data and action, empowering observability, IT and security teams to ensure their organizations are secure, resilient and innovative.
Founded in 2003, Splunk is a global company — with over 7,500 employees, Splunkers have received over 1,020 patents to date and availability in 21 regions around the world — and offers an open, extensible data platform that supports shared data across any environment so that all teams in an organization can get end-to-end visibility, with context, for every interaction and business process. Build a strong data foundation with Splunk.

Get the latest articles from Splunk straight to your inbox.
© 2005 - 2024 Splunk Inc. All rights reserved.
