
Digital Resilience Pays Off
Download this e-book to learn about the role of Digital Resilience across enterprises.
*for legal reasons neither the author nor Splunk inc. can guarantee victory in Fantasy Football
They say football is “predictably unpredictable” and arguably its magic is derived from this sense of not knowing what’s around the corner.
But when it comes to Fantasy Premier League, an online game where you construct a virtual team of football players and score points based on their real-life performances, this unpredictability is less magical and more flat-out frustrating.
Well, having explored in the first half of this blog how to utilise a data-driven approach to pick your fantasy football team with Splunk, this second half will go one step further and focus on how, leveraging the Splunk Machine Learning Toolkit, we can move from the analytical to the predictive and project the performances of every player, across every game in the 20/21 Premier League season.
After completing the majority of the necessary data wrangling in part 1 of this blog post, we have two primary data sets that will be utilised for prediction modelling:
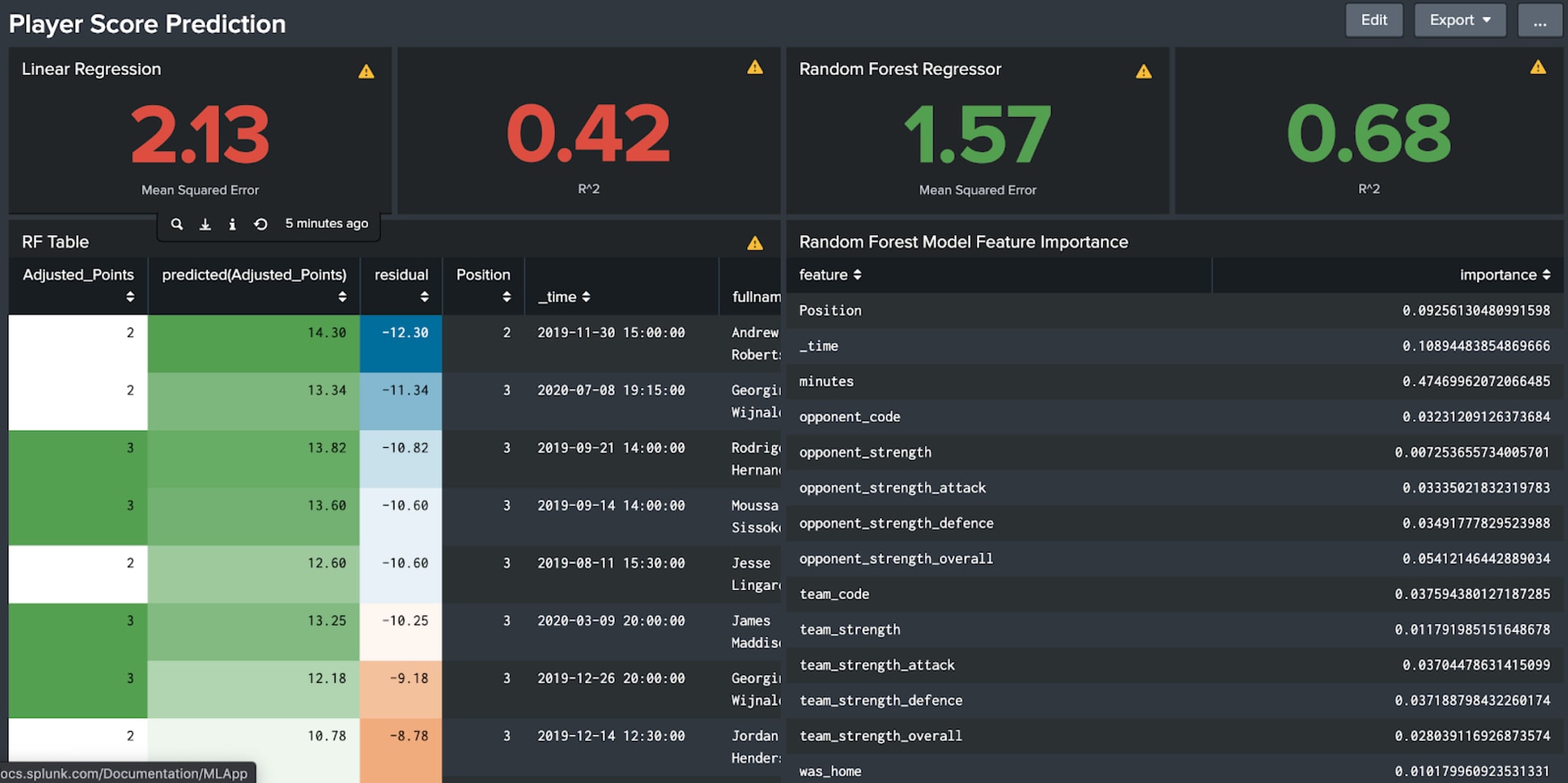
With the end goal of this exercise being to populate the prediction dataset with the predicted points scored by each player, the first step is identifying the data fields within the training set which produce the most accurate predictions - allowing us to focus on the most important fields when we later make our Regressor algorithm predictions.
For this preprocessing we can utilise the MLTK’s Predict Numeric Fields assistant and field selector algorithm.
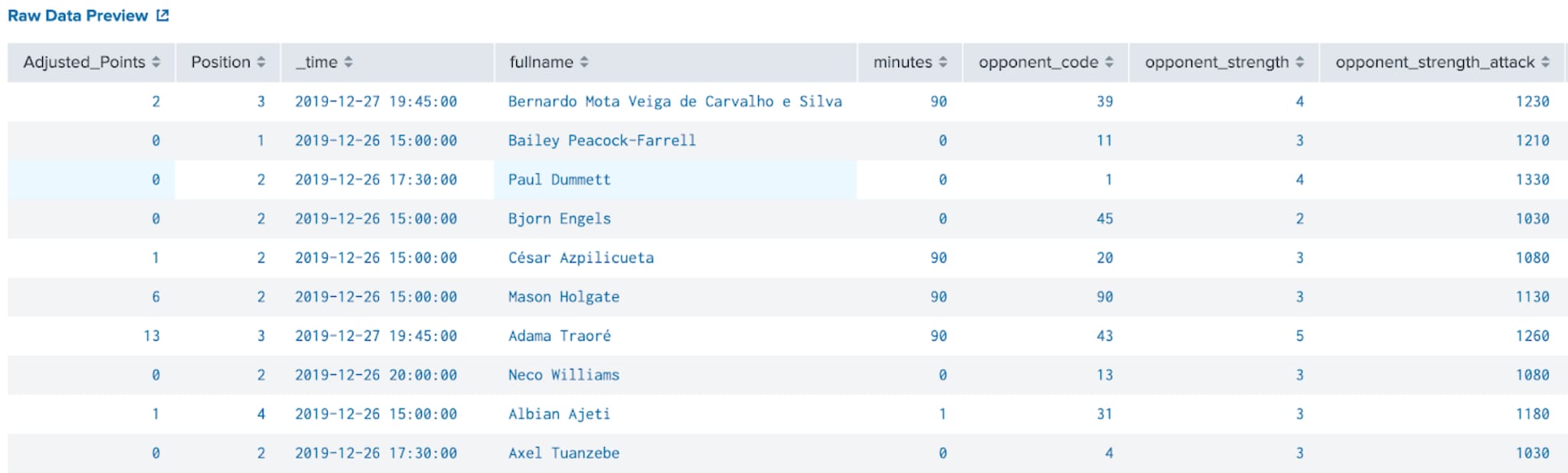
While fields that are intrinsically linked to the points scoring calculation (i.e. goals scored, goals conceded and red cards) have been removed from the training set as they would have too strong a weighting to any prediction (and are as unknowable prior to the game happening) we are still left with 15 fields with which to choose from.

From the output of the field selector we can see that, of these 15 fields, the most important are the various strength values of the player opponent (interestingly more so than the team of the player) and crucially the minutes played by the player.
But how can we know how many minutes a player is going to play prior to a game? Well, fortunately with the MLTK we can forecast.
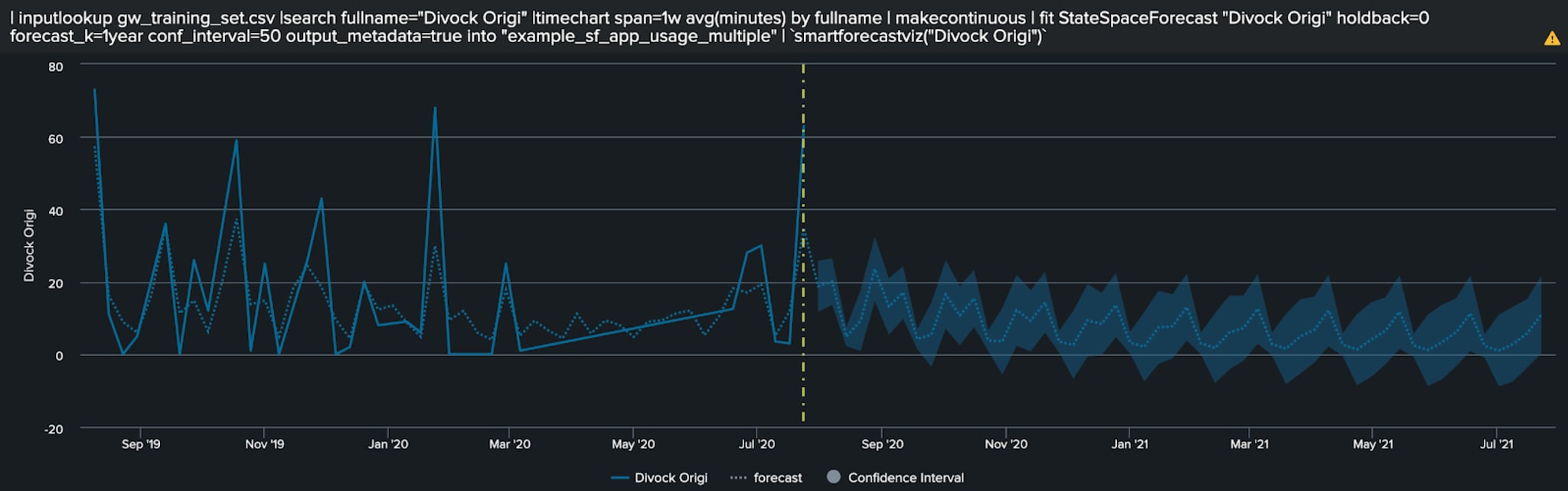
Using the Smart Forecasting Assistant and StateSpaceForecast algorithm, underpinned by Kalman filtering, we can forecast each player’s minutes over the next year entirely through the UI and without manually typing any SPL.
Below we can see the example of Liverpool back-up striker Divock Origi’s minutes, who, after a season of mostly featuring sporadically, forecasts to consistently receive between 0 and 20 minutes, a number which trends downward as the season continues - an entirely possible outcome given the emerging squad competition of Liverpool academy products.
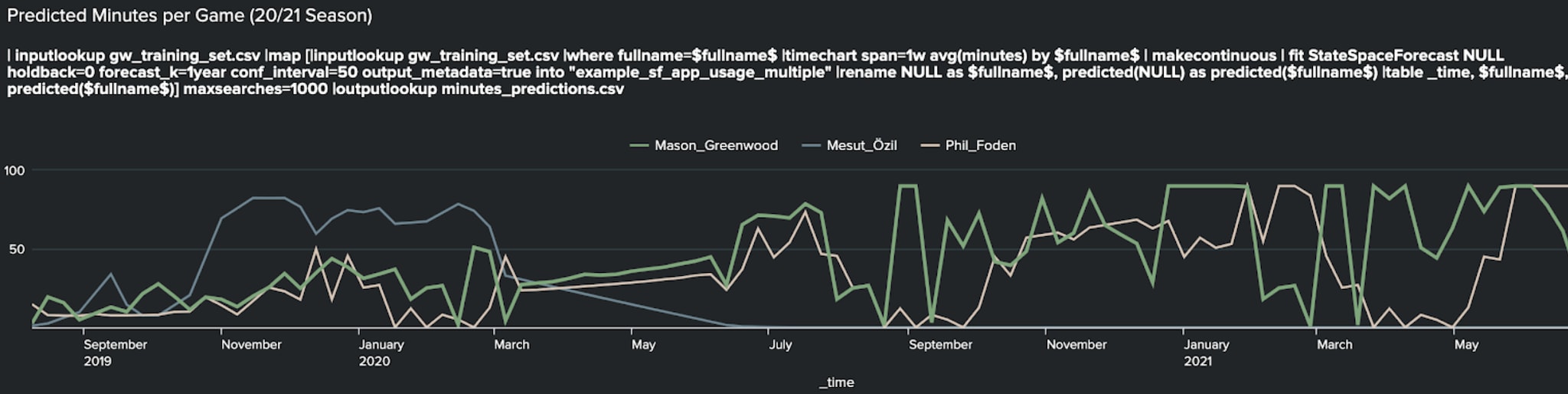
Leveraging the below SPL we can cycle through all the players in the dataset and automatically generate forecasts for each. Here are the projections for three such players: Mesut Özil, who fell out of favour at Arsenal during the final months of the 19/20 campaign (and projects to receive no minutes during the upcoming season), Mason Greenwood (who projects to continue his recent increase in game time at Manchester United) and Phil Foden (who forecasts to return to the bit-part role he began last season with at Manchester City before increasing in minutes towards the end of this season).
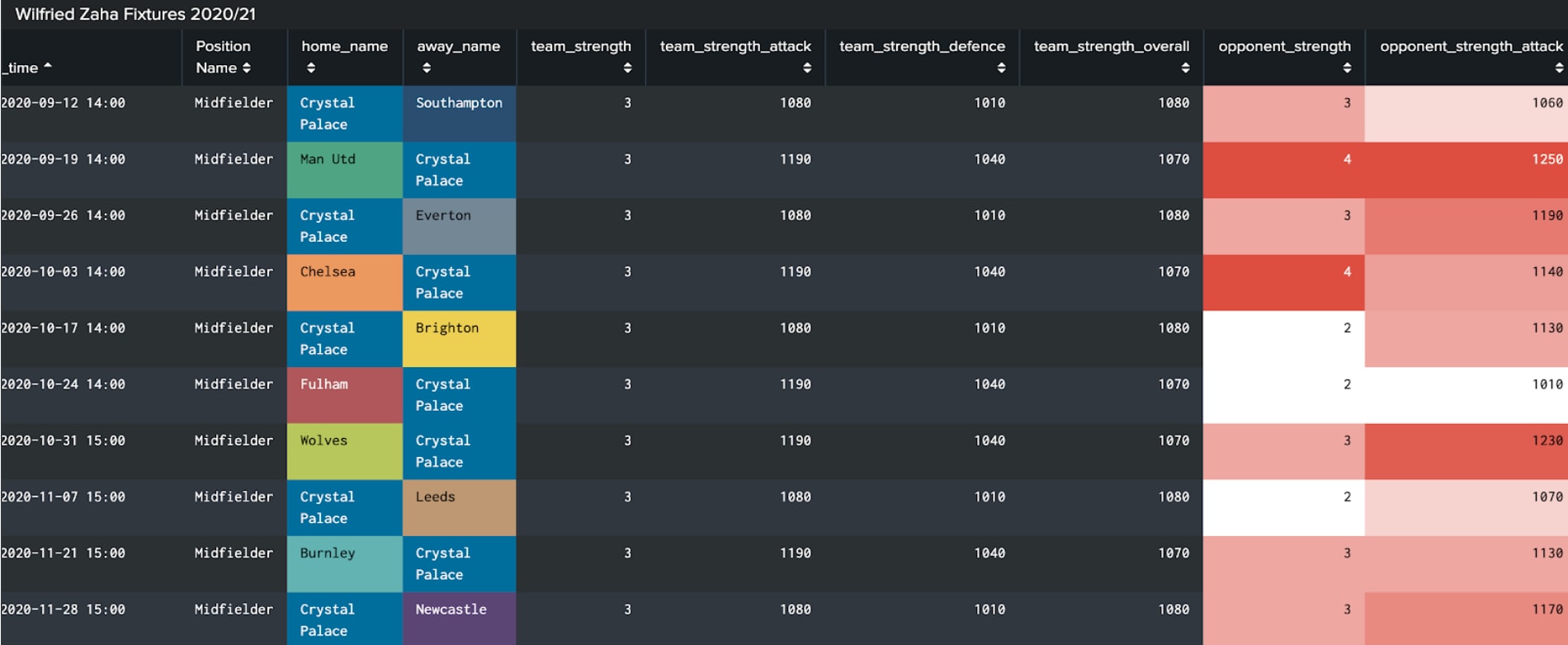
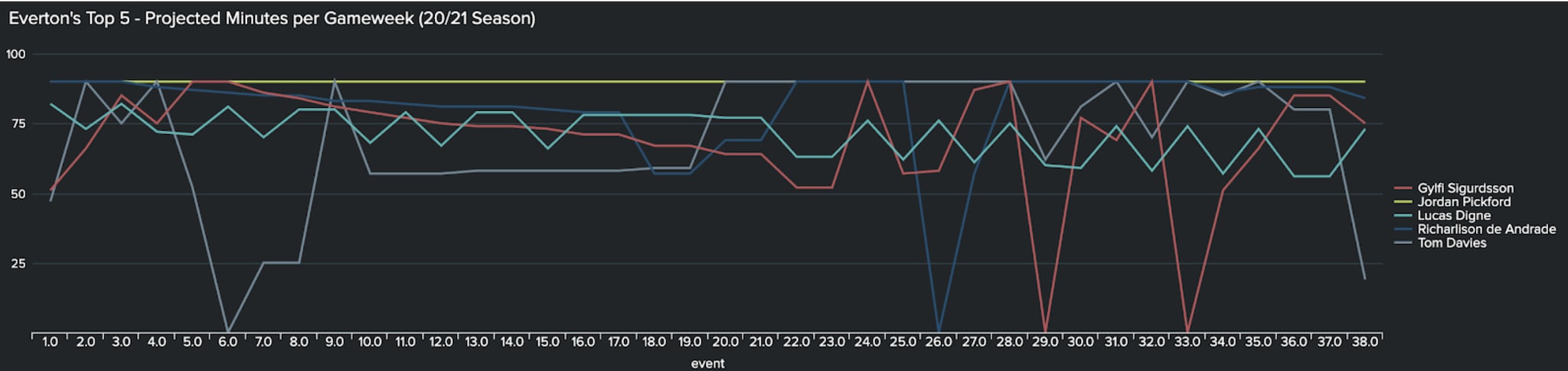
Finally, using time buckets these predicted minutes are mapped to the closest future fixtures to those dates - illustrated by the below chart showcasing the projected minutes of 5 of Everton’s key contributors over each gameweek.
Now all the data is correctly formatted, we can finally begin projecting player points for the upcoming season and ironically, thanks to Predict Numeric Fields Assistant, this is the easiest part. We merely point the search to our training set, select the fields contained within it and choose from the 7 numeric prediction algorithms contained within it.
Here the linear regression and random forest regressor algorithms are selected and scored based on their performance on the training set - with the lower mean squared error and higher R2 value of the latter indicating it produces more accurate predictions. In addition, less important features such as whether the game was at home or away are removed to optimise performance.
So what does the optimized model predict for the 2020/21 season? Well, let’s start with gameweek one - the only football to have been played at time of writing.
Using knapsack optimisation, as outlined in part 1 of this blog, Splunk created the below optimised team which was predicted to score 60.36 points (or 67.57 if you captained projected top scorer Raúl Jiménez for double points).
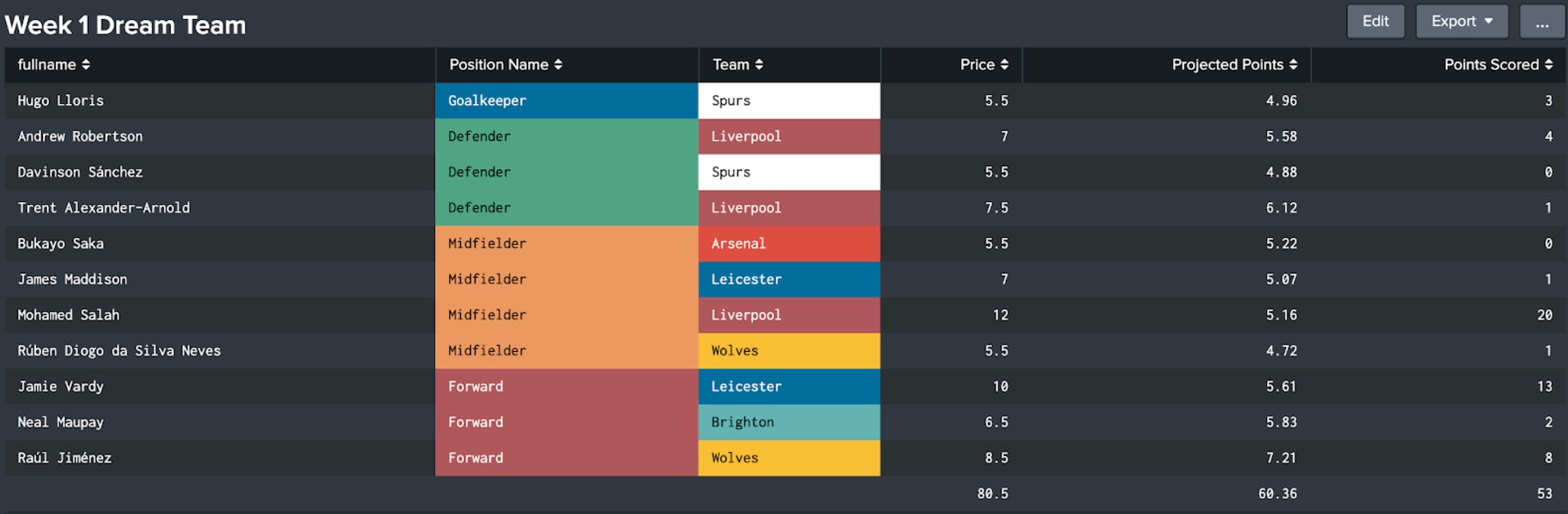
In reality, AI Milan (as I’ve monikered them) scored 53 or 60 including the aforementioned captain choice. Fortunately the more questionable player choices were counterbalanced by Salah, Vardy and a captained Jiménez all scoring highly. This score, combined with some automatic replacements for the non-featuring Saka and Sanchez, was good enough for a global GW1 rank of 914,811 out of over 7,000,000 players - not a bad showing at all (and embarrassingly better than my non-algorithm selected team!).
What about the rest of the season? Well, I’m not going to give away all my secrets, but the below team projects to score the most points of any in budget team over the course of the season.
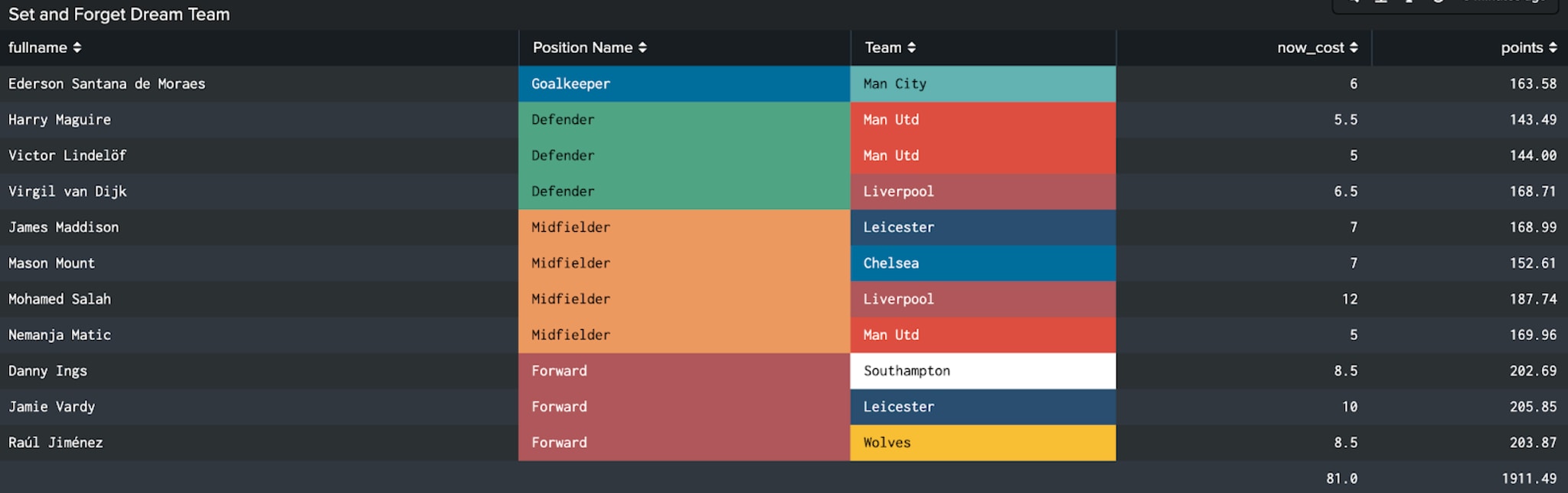
Led by projected season top scorer Jamie Vardy and featuring surprising selections in Manchester United’s Nemanja Matic and Victor Lindelof (as well as week 1 captain Jiménez), the side projects to score 2117 points with a captained Vardy which last season would have been enough for a top 750,000 place finish.
So maybe I still have someway to go in showing you how to win at fantasy football with machine learning, but if you want to try what I’ve described here (and see if you can create a better lineup) check out the MLTK on Splunkbase.
In the meantime, I hope you enjoyed this blog series and good luck to your fantasy team for the season ahead.
Happy Splunking!

The Splunk platform removes the barriers between data and action, empowering observability, IT and security teams to ensure their organizations are secure, resilient and innovative.
Founded in 2003, Splunk is a global company — with over 7,500 employees, Splunkers have received over 1,020 patents to date and availability in 21 regions around the world — and offers an open, extensible data platform that supports shared data across any environment so that all teams in an organization can get end-to-end visibility, with context, for every interaction and business process. Build a strong data foundation with Splunk.

Get the latest articles from Splunk straight to your inbox.
© 2005 - 2024 Splunk Inc. All rights reserved.
