
Digital Resilience Pays Off
Download this e-book to learn about the role of Digital Resilience across enterprises.

I spent most of the late '80s as a petulant, nerdy teen growing up in Northern Virginia. On the day I turned 16, I got my drivers license and since I was one of the first in my group of sweet and tender hooligans to do so, found myself carting them around the suburbs from one aimless activity to another. We’d pop Depeche Mode or The Cult or Bauhaus into the aftermarket Pioneer cassette player, I’d drive just under the speed limit to avoid speeding tickets or other interaction with Fairfax County’s finest, and we’d intimidate...exactly no-one. But man, we thought—no, we knew—we were cool.
My ride? A 1971 Lincoln Continental handed down from my late great-uncle, almost exactly like this one, including the color and the whitewalls:
Now this car was SLOW, but it had incredible horizontal scale potential. We could pack ten folks in the back seat comfortably since we were all sallow-skinned malnourished goth kids. And we still had room for a case of Crystal Pepsi.
What the hell does this have to do with Splunk and hunting, Brodsky? Did someone give you the admin password to the blogging software again?!? GET ON WITH IT BEFORE I IGNORE YOU AND ORDER A BAHN MI FROM UBER EATS. Please.
Oh, fine. Let’s compare my slow-but-massive 1971 land yacht—which scaled well but didn’t get us anywhere fast—to some common issues we see in Splunk when hunting for malicious behavior in endpoint data.
That last one above, #3, is the main inspiration for this blog post. You see, Roberto Rodriguez (@Cyb3rWard0g) over at SpecterOps wrote a wonderful series of three posts on real-time Sysmon processing right before Christmas detailing how to use Microsoft Sysmon + Kafka + KSQL + HELK to find signatures of lateral movement across a massive amount of Sysmon data by effectively mining Process Create and Network Connect events. The magic in his solution is the ability to use Kafka's KSQL to perform joins of Sysmon event data at the Kafka layer before the data is ingested in HELK so that you can effectively hunt through the resulting merged events without having to perform costly joins at search time. This method is really cool! Moreover, he points out that while you can do this in SIEM technology like Splunk, it "loads the SIEM with heavy computations when done through terabytes of data at rest.”
Sad, but true.
Note! Leveraging Kafka and KSQL in the exact same way Roberto describes in his post but using Splunk instead of HELK to capture and report on the data is 100% possible. To do so, check out the free Splunk Connect for Kafka.
If you try and join Sysmon Process Create events and Network Connect events in Splunk at search time using standard raw data and regular search, you’re gonna have a bad time looking at any significant amount of data. But...by using some fairly standard out-of-the-box Splunk functionality, you can rip through terabytes of Sysmon (and other Endpoint) data pretty quickly, without having to stand up a whole new data ingest architecture like Kafka to do it. All you need are the following:
In October of 2018, we announced and released a version of the CIM with full support for a new Endpoint data model. Details of this model have been covered in our Security Research Team's blog post, "Get More Flexibility and Accelerated Searches with the New Endpoint Data Model," and further by fan-favorite Splunker Kyle Champlin in his "| datamodel Endpoint" blog. Our Research Team recently updated the Sysmon Add-On to correctly map them to this new model (and by the way, they're working diligently on doing the same for osquery.) These two milestones make the rest of this solution possible.
We'll assume you are already Splunking the Sysmon data coming from your Windows endpoint fleet (you've checked out "A Salicious Soliloquy on Sysmon," so of course you are, right?), and have the EventCode 1 (Process Create) and EventCode 3 (Network Connect) events arriving properly in your Splunk instance. If so, you’re almost ready to search through this data at blazing speed.
Once you have the Sysmon TA and CIM installed, there’s a simple addition we will make to the Endpoint.Ports portion of the data model: we need to add the process_guid field. After installation of the CIM app, you’ll see that this field exists, as it should, in the Endpoint.Process model—but not in Ports. We can use the GUI (Settings->Data Models->Endpoint.Ports->Edit) to add it, like so:
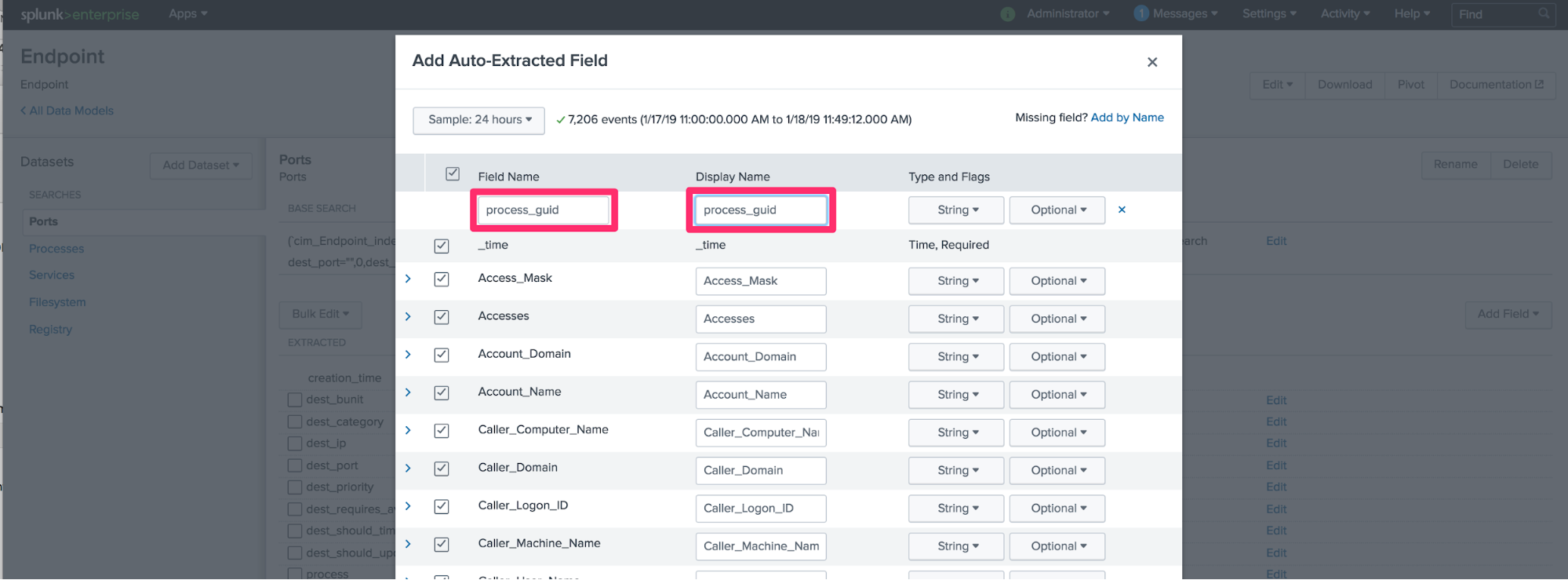
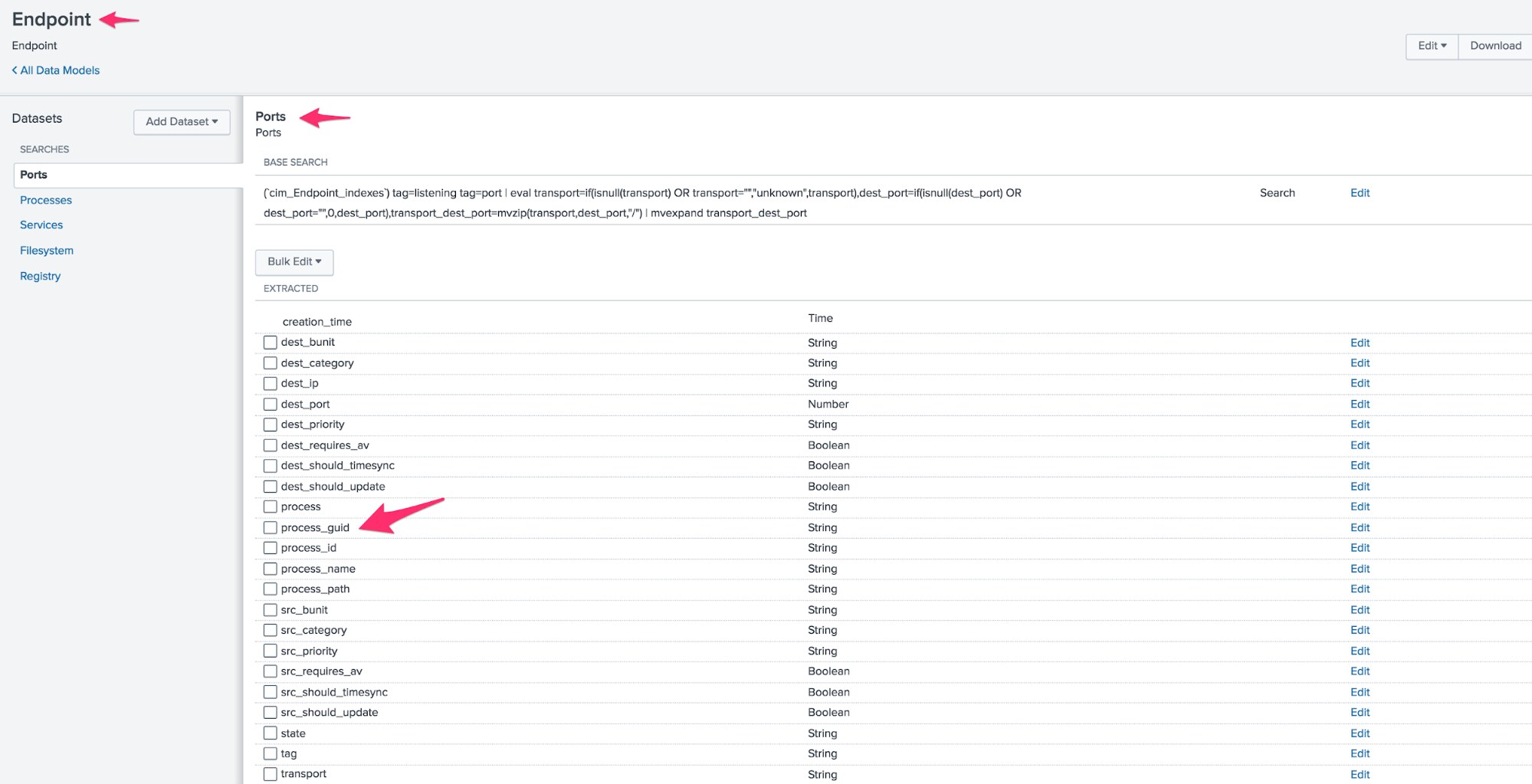
(If you are 1337 or wear a fez, or both, you might just edit the underlying Endpoint.json, add the field, and restart everything.) Don’t forget to rebuild the model so your new field is usable!
To test that this works, you can run this search:
| tstats summariesonly=t count from datamodel=Endpoint.Ports by Ports.process_guid
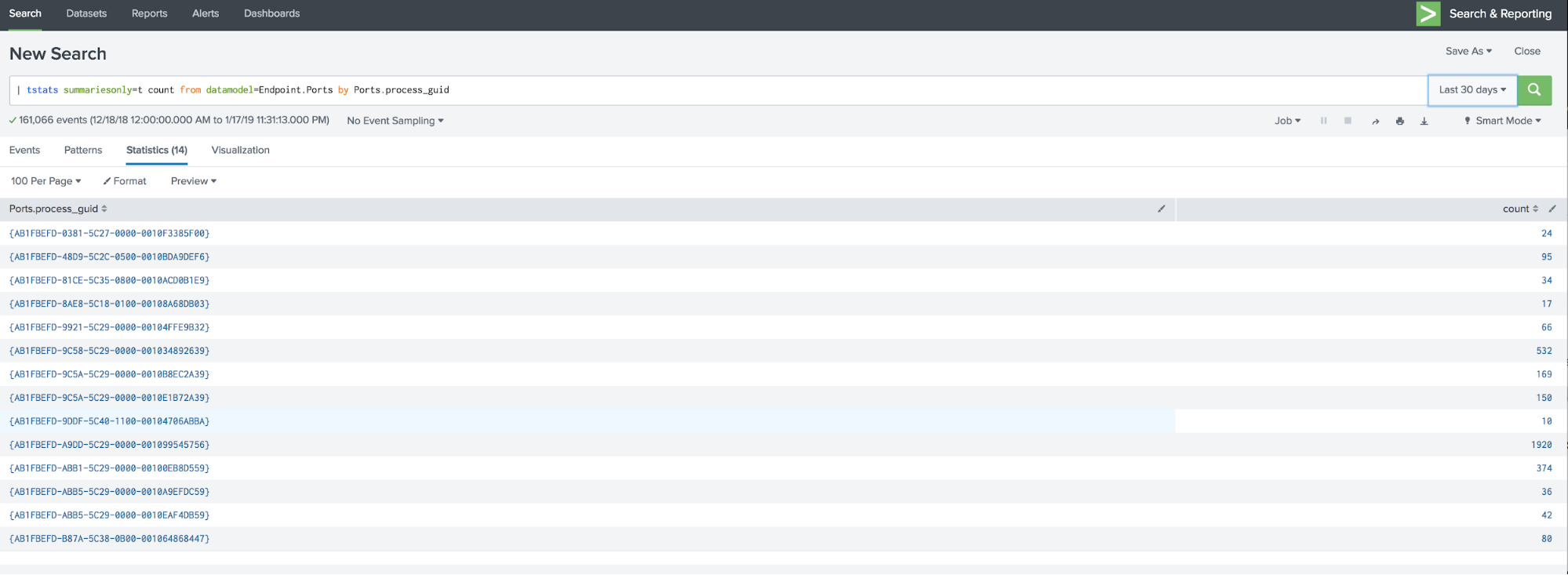
Got data? Good.
So in my small lab network this past summer, during some research before working on BOTS, I installed Windows 7 on three victim machines called DOLORES, TEDDY, and CLEMENTINE. I fully instrumented these machines with everything mentioned above: Sysmon, the Splunk UF, and a slightly modified version of TaySwifts Sysmon config (Olaf Hartong has a good one too). This gave me plenty of Process Create and Network Connect events upon which to search.
I then brought a Windows 10 machine, MAEVE, onto my network to serve as the initial compromised host. On a Linux box with IP address 192.168.10.187 (in the real world, this would likely be an external IP), I installed Empire. Once MAEVE was compromised, I then moved laterally from MAEVE to DOLORES, TEDDY, and CLEMENTINE using Empire’s lateral_movement/invoke_wmi module and captured all of the resulting Sysmon data from the three hosts in Splunk.
We want to look for network connections, made by PowerShell, where the parent process is wmiprvse.exe. This behavior is described in MITRE ATT&CK technique T1086:PowerShell. To do this, we need to join process_guid between the two kinds of Sysmon events: Process Create and Network Connect. The traditional raw-data search through this data to first find evidence of lateral movement via WMI and then join the hash values and destination targets of the binary would look something like this:
index=latmove sourcetype="XmlWinEventLog:Microsoft-Windows-Sysmon/Operational" ((EventCode=1 AND ParentCommandLine=*wmiprvse*) OR (EventCode=3 AND Image=*powershell*))
| stats first(_time) as Last_Seen, last(_time) as First_Seen, values(host) as host, values(dest) as TARGET_IP, values(SHA256) as HASH, values(CommandLine) as COMMAND, values(ParentCommandLine) as PARENT by process_guid
| rex max_match=10 field="COMMAND" "(?<splitregex>.{0,50}(?:\s|$)|.{50})"| eval COMMAND=splitregex
| search HASH=*
| eval Last_Seen=strftime(Last_Seen,"%m/%d/%y %H:%M:%S"), First_Seen=strftime(First_Seen,"%m/%d/%y %H:%M:%S")
| fields - splitregex,process_guid
Which does the following:
Yeah, you could also do that using transaction, but every time you use that command, a goth teenager in Leesburg mopes—so don’t do it.
The results of the above search are useful and look like this:
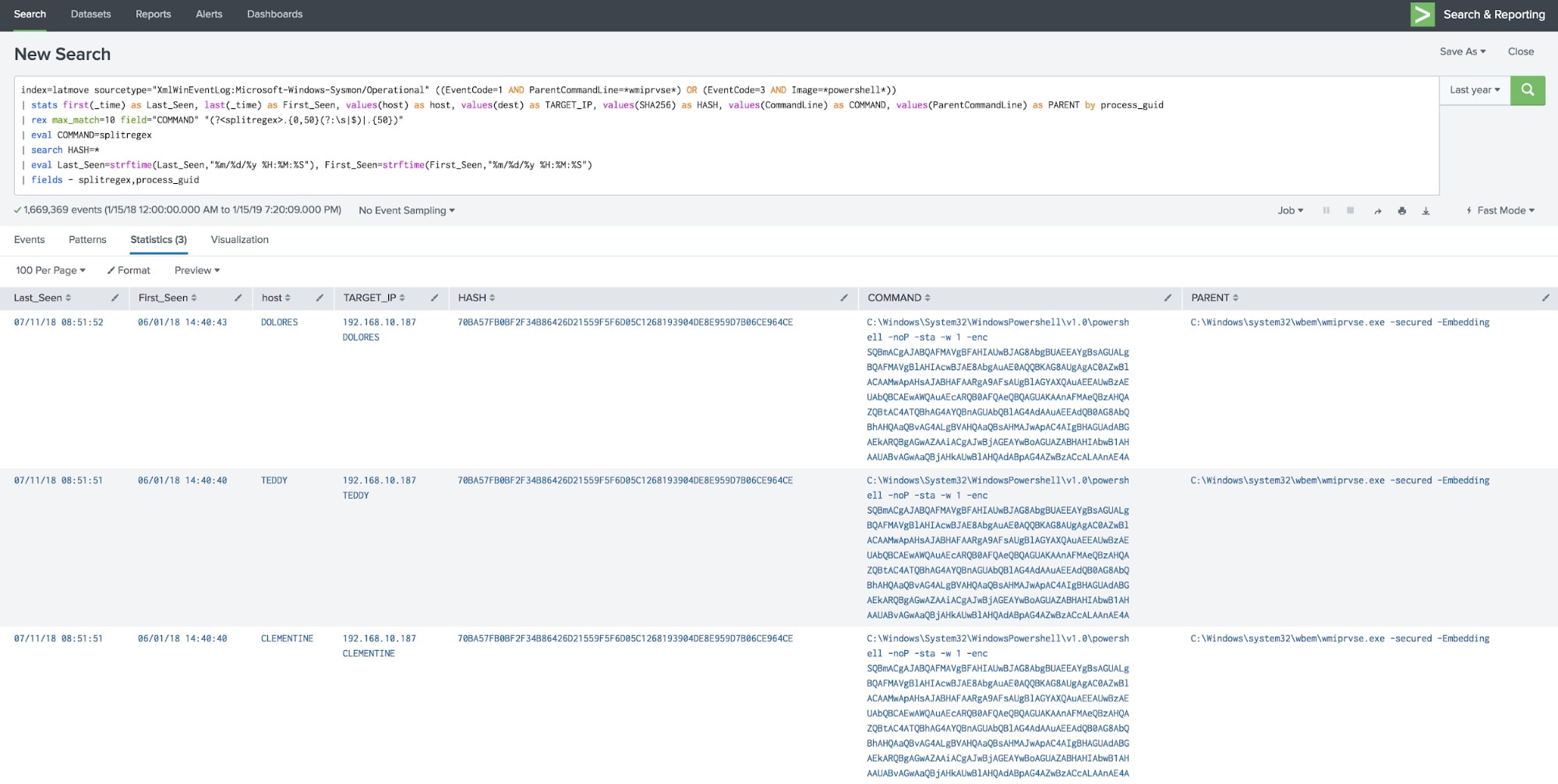
So sure enough, we see that DOLORES, TEDDY, and CLEMENTINE are showing signs of lateral movement infection and are communicating to the C2 host at 192.168.10.187. Great!
By the way, there are clever ways to figure out that MAEVE was the commanding endpoint that infected DOLORES, TEDDY, and CLEMENTINE, and you don't need an HBO subscription to figure it out. Email me and I'll share that search with you.
But what’s wrong with that? Let’s look at Splunk’s Job Inspector:

Ooof. Almost three minutes to search through 1.7M events to get back three results. BOO! Roberto was right—that's slow! This is almost as long as it took to drive the Lincoln to the Burger Chef at 2am.
Let’s apply the magic of the new Endpoint datamodel accelerated with a year’s worth of data and see how much faster we can go, shall we?
Now, just like many Splunkers and Splunk customers, the concept of using tstats in searches is still foreign to me. If it is also foreign to you, I highly recommend David Veuve's classic “From Raw to tstats” .conf presentation, which explains this in the kind of detail and pure joy that only Veuve can approach. The search below implements many of his teachings.
| tstats summariesonly=t prestats=t count,values(Processes.parent_process),values(host),values(Processes.process_hash),values(Processes.process) from datamodel=Endpoint.Processes where index=latmove AND Processes.parent_process="*wmiprvse*" by Processes.process_guid
| tstats summariesonly=t prestats=t append=t count,values(Ports.Image), values(Ports.dest), values(Ports.creation_time) from datamodel=Endpoint.Ports where index=latmove AND Ports.Image="*powershell*" by Ports.process_guid
| rename Ports.process_guid as GUID Processes.process_guid as GUID
| stats first(Ports.creation_time) as Last_Seen,last(Ports.creation_time) as First_Seen values(Processes.process) as COMMAND, values(host) as HOST, values(Ports.dest) as TARGET_IP,values(Processes.parent_process) as PARENT,values(Processes.process_hash) as HASHES by GUID
| rex max_match=10 field="COMMAND" "(?<splitregex>.{0,50}(?:\s|$)|.{50})" | eval COMMAND=splitregex
| search HASHES=*
| rex field=HASHES "MD5=(?<MD5>.+)\,SHA256=(?<SHA256>.+)$"
| fields - splitregex,HASHES,GUID
Run for the hills! Scary, right? Not really—the bottom half of this search is essentially the same as the one above. So let’s go through the top half…
The payoff?
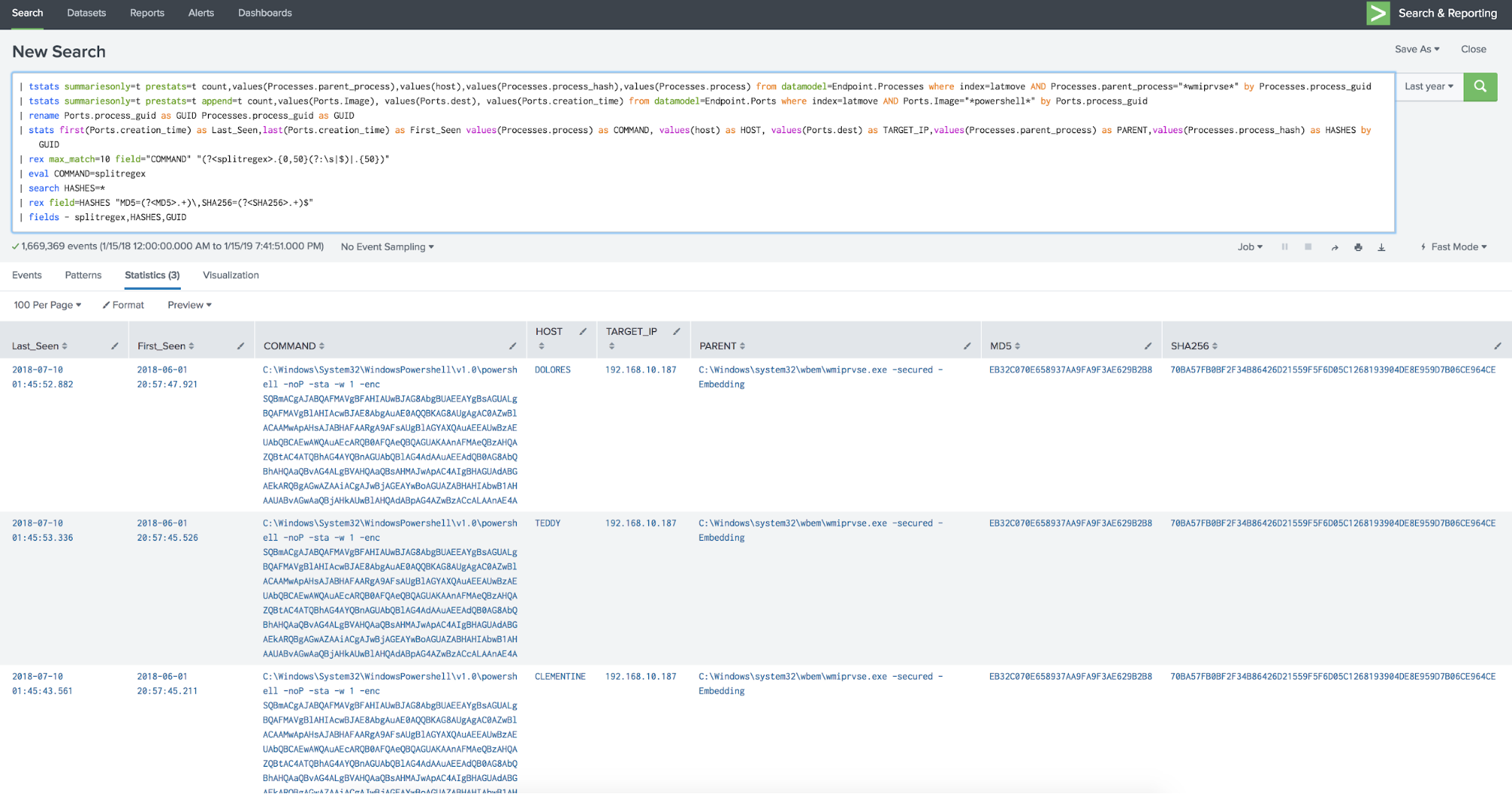
A very similar result to our first search against raw data. But how long did it take?

Just over 8 seconds! The same results, but in about 5% of the time it took for the standard search methodology; and this is on my crappy old virtual server with slow cores and slower disk that I probably shouldn't even be running Splunk on, anyway. Woot! This is far better—the modern Tesla, if you wish, to that grand old Lincoln.
I think these kinds of searches hold significant promise for actually being able to hunt through mountains and mountains of granular endpoint data at scale, and I’m very interested in hearing from you if you do it.
Until next time, keep your Lincoln in the middle lane, your ten goth friends in the back seat, your cassettes properly rewound, and your endpoints flowing their data into Splunk!
Happy Hunting!

The Splunk platform removes the barriers between data and action, empowering observability, IT and security teams to ensure their organizations are secure, resilient and innovative.
Founded in 2003, Splunk is a global company — with over 7,500 employees, Splunkers have received over 1,020 patents to date and availability in 21 regions around the world — and offers an open, extensible data platform that supports shared data across any environment so that all teams in an organization can get end-to-end visibility, with context, for every interaction and business process. Build a strong data foundation with Splunk.

Get the latest articles from Splunk straight to your inbox.
© 2005 - 2024 Splunk Inc. All rights reserved.
