
Digital Resilience Pays Off
Download this e-book to learn about the role of Digital Resilience across enterprises.

Security teams can’t defend what they can’t see. As organizations move more workloads to the cloud, security teams need added visibility into these new workloads or risk having blind spots that lead to compromise. In the first installment of our "Getting Data In" webinar series, "Modernizing your SOC for the Cloud Age Starts with Security Foundations," we demonstrate how to quickly and easily onboard data into Splunk Cloud.
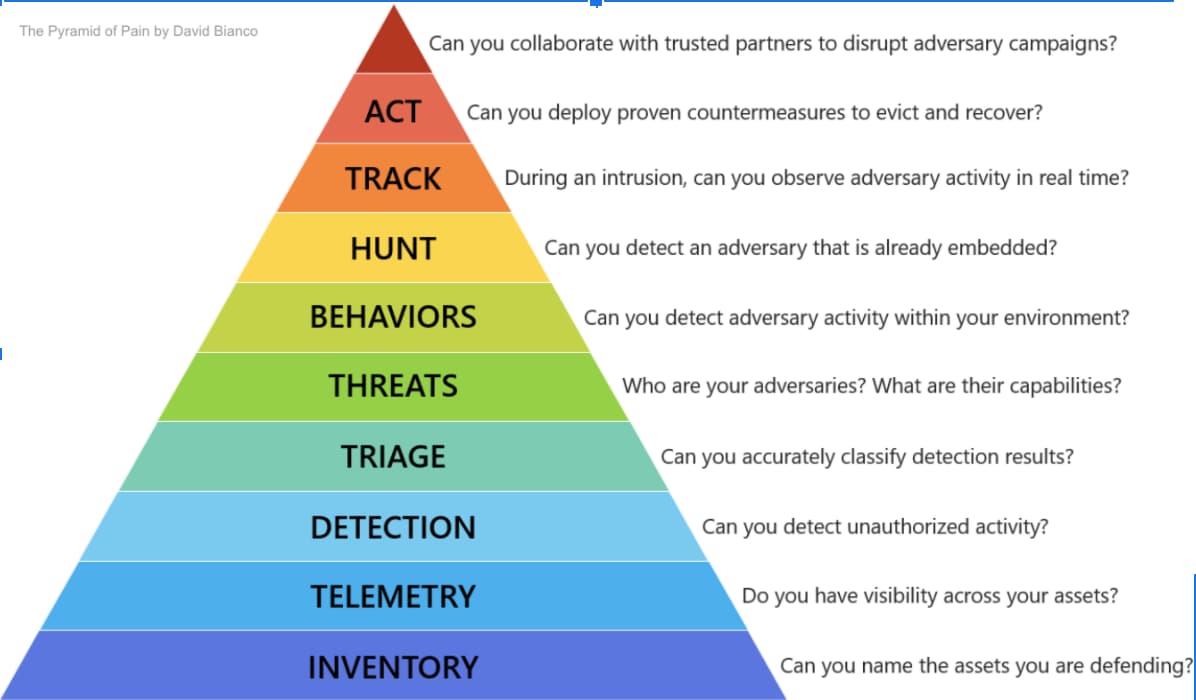 Let’s Get Back to Basics
Let’s Get Back to BasicsOrganizations should understand their data in terms of its value to the business. We’ve asked security teams “What are the most important assets and applications to the business?” and we often get answers along the lines of “Routers, switches, and firewalls.” While these tools are critical, focusing only on tools and not the data the tools interact reflects a static view to a much more dynamic environment. The data creates a whole new world of insights that can help to provide business value and further reduce risk.
By leveraging the correct data, security teams can better protect their organizations — not just their IT systems — by first reframing their perspectives to identify business-critical assets and applications. To get started, analysts need to be able to answer foundational questions about their environment, such as naming assets they’re defending and what databases are behind these assets. This foundational knowledge enables security teams to answer more complex questions later on, establishing an effective and more proactive security program as a result of a strong understanding of their environment. This level of understanding will also help organizations of all sizes and industries identify the right data to onboard into Splunk.
We’ve outlined a few data discovery questions you can ask yourself to start getting valuable insights from your data:
We go into more detail in the webinar with a step-by-step demo showing why these questions are important as you onboard your data sources in Splunk Cloud. You might be surprised to find out that onboarding data into Splunk Cloud is not only fast and effective but also safe.
Now that you’ve prepped and primed your data, it’s time to consider the different ways to onboard it. Splunk provides hundreds of ways to capture data depending on where your data exists and how you’re bringing the data in. For example, when considering a data source methodology, you can use Splunk’s Universal Forwarder for local file monitoring, or you could use HTTP Event Collector (HEC) for mobile apps, IOT devices, or applications where a forwarder can’t be installed. At the end of the day, these different methods will serve the same purpose – sending your data directly to Splunk Enterprise or Splunk Cloud for indexing.
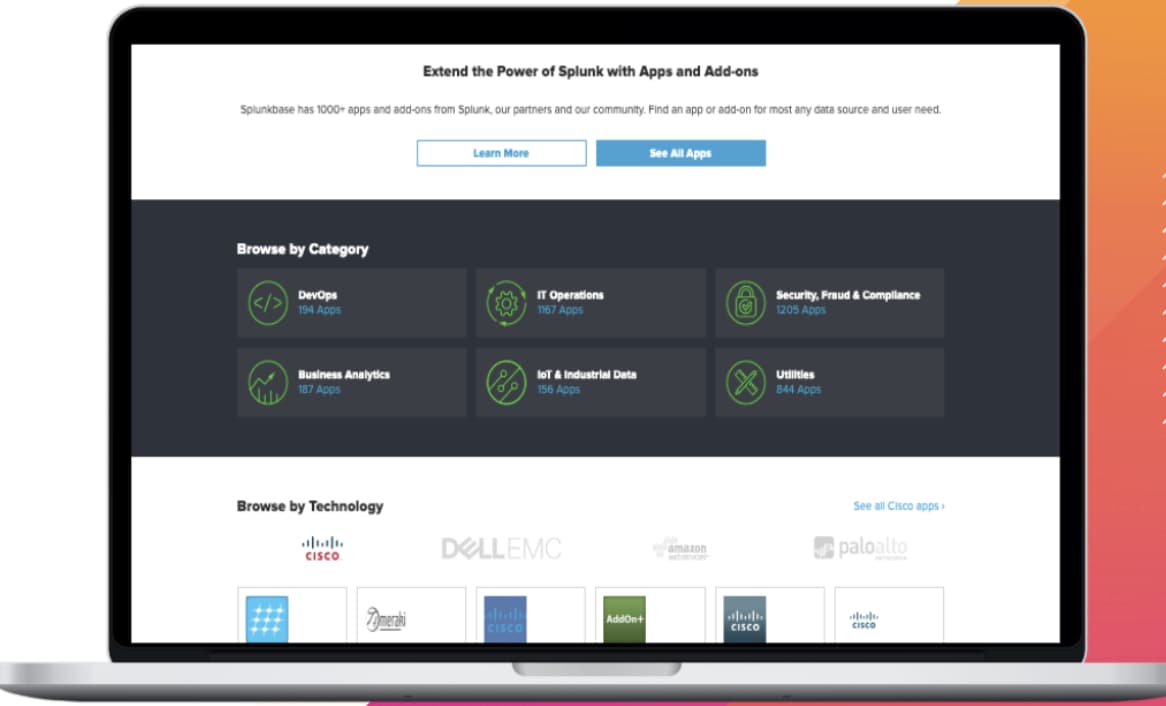 There Might be an App (and Add-On) For That!
There Might be an App (and Add-On) For That!With Splunk’s robust community and ecosystem, you might not need to lift a heavy finger to onboard and massage your data into the platform. Customers can take advantage of Apps and Add-ons on Splunkbase to onboard data quickly and start getting immediate value from it.
As you onboard multiple data sources into the platform, normalizing the data is a crucial next step. The Common Information Model (CIM) provides a predictable field schema regardless of data source and helps standardize fields when onboarding data. The CIM will standardize values from a field, such as time, regardless of how the field was originally labeled from the source.
While you can sift through pages of documentation on getting data in Splunk, we captured a true end-to-end narrative of the process for you to watch in our latest webinar, "Modernizing your SOC for the Cloud Age Starts with Security Foundations." Along with our partner, Zivaro, we show best practices on identifying business-critical data, configuring your systems, and demonstrating how to onboard and normalize Windows, Linux, and Cisco ASA data into Splunk Cloud so that you can start getting valuable insights today.
----------------------------------------------------
Thanks!
Amy Heng

The Splunk platform removes the barriers between data and action, empowering observability, IT and security teams to ensure their organizations are secure, resilient and innovative.
Founded in 2003, Splunk is a global company — with over 7,500 employees, Splunkers have received over 1,020 patents to date and availability in 21 regions around the world — and offers an open, extensible data platform that supports shared data across any environment so that all teams in an organization can get end-to-end visibility, with context, for every interaction and business process. Build a strong data foundation with Splunk.

Get the latest articles from Splunk straight to your inbox.
© 2005 - 2024 Splunk Inc. All rights reserved.
