
Digital Resilience Pays Off
Download this e-book to learn about the role of Digital Resilience across enterprises.
Data creation is exploding – in 2020, it’s estimated that 1.7MB of data will be generated every second for every person on earth. According to Forbes, each day another 2,500 petabytes of data is created. Massive amounts of data make it hard to collect, protect and deliver the right information to the right users and systems. Data driven decision making is also challenged by all the locations we store our data; in multiple instances, subsidiaries, and on-premises/cloud/multi-cloud environments. Speed to insights is still paramount in today's environment with e-commerce becoming front and center; customer purchases, online customer behavior and supply chain checks demand immediate attention as they impact revenue and costs. Imagine how powerful having this information at hand can be for businesses, from identifying problems early on, to driving customer outcomes.
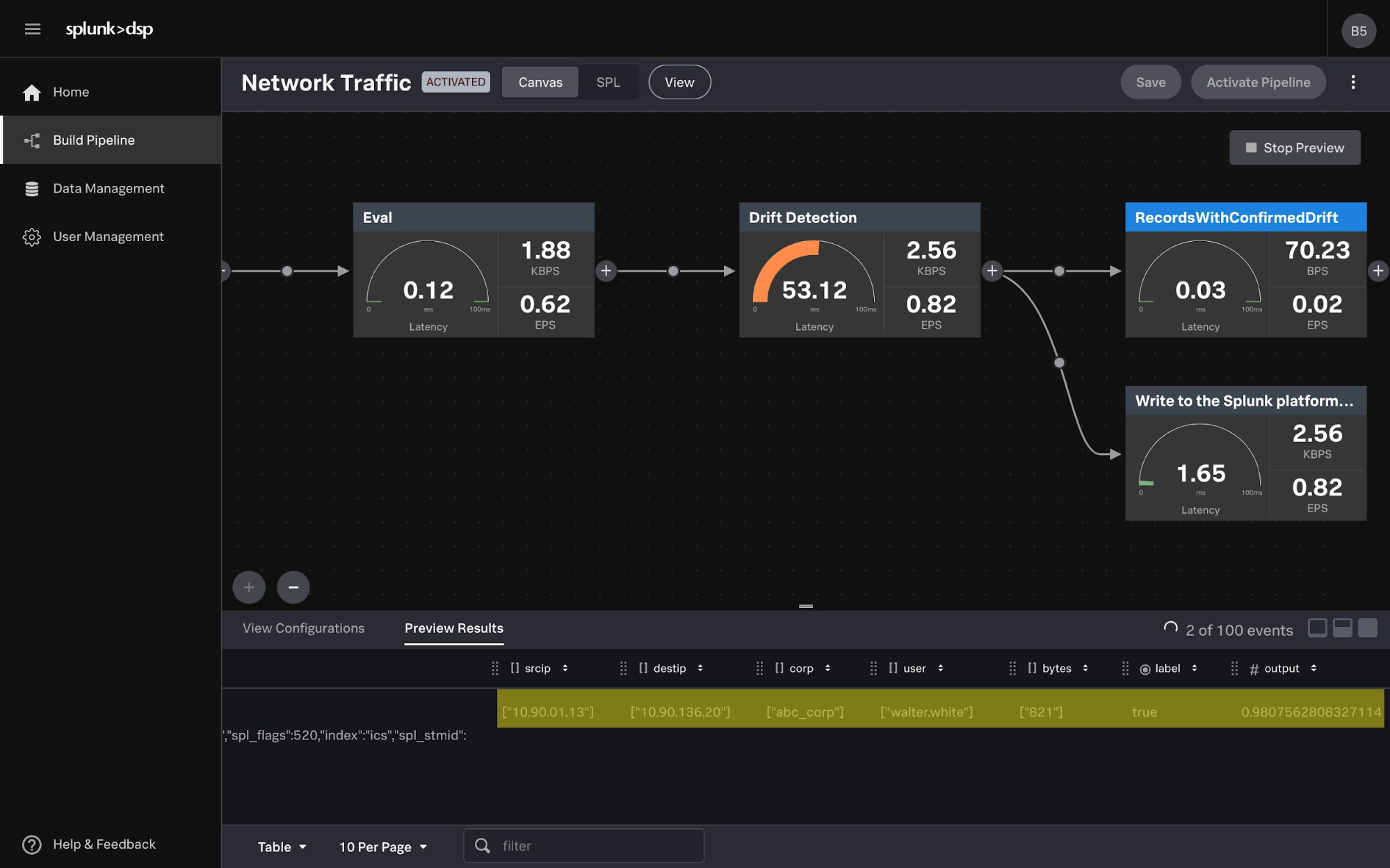
This is where data streaming is critical in the information lifecycle by providing more control, visibility and validation. With Splunk’s launch of Data Stream Processor (DSP) 1.1, we are packing a ton of additional customer value that we are excited to share!
With additional sources like AWS S3, GCP Monitoring Metrics and Microsoft 365, customers can easily bring their data into a single unified location for better visibility, then leverage advanced streaming capabilities as needed like performing data formatting, filtering or aggregations. We make data collection easier with SPL2 and visual query builder which provides insight into your data pipelines.
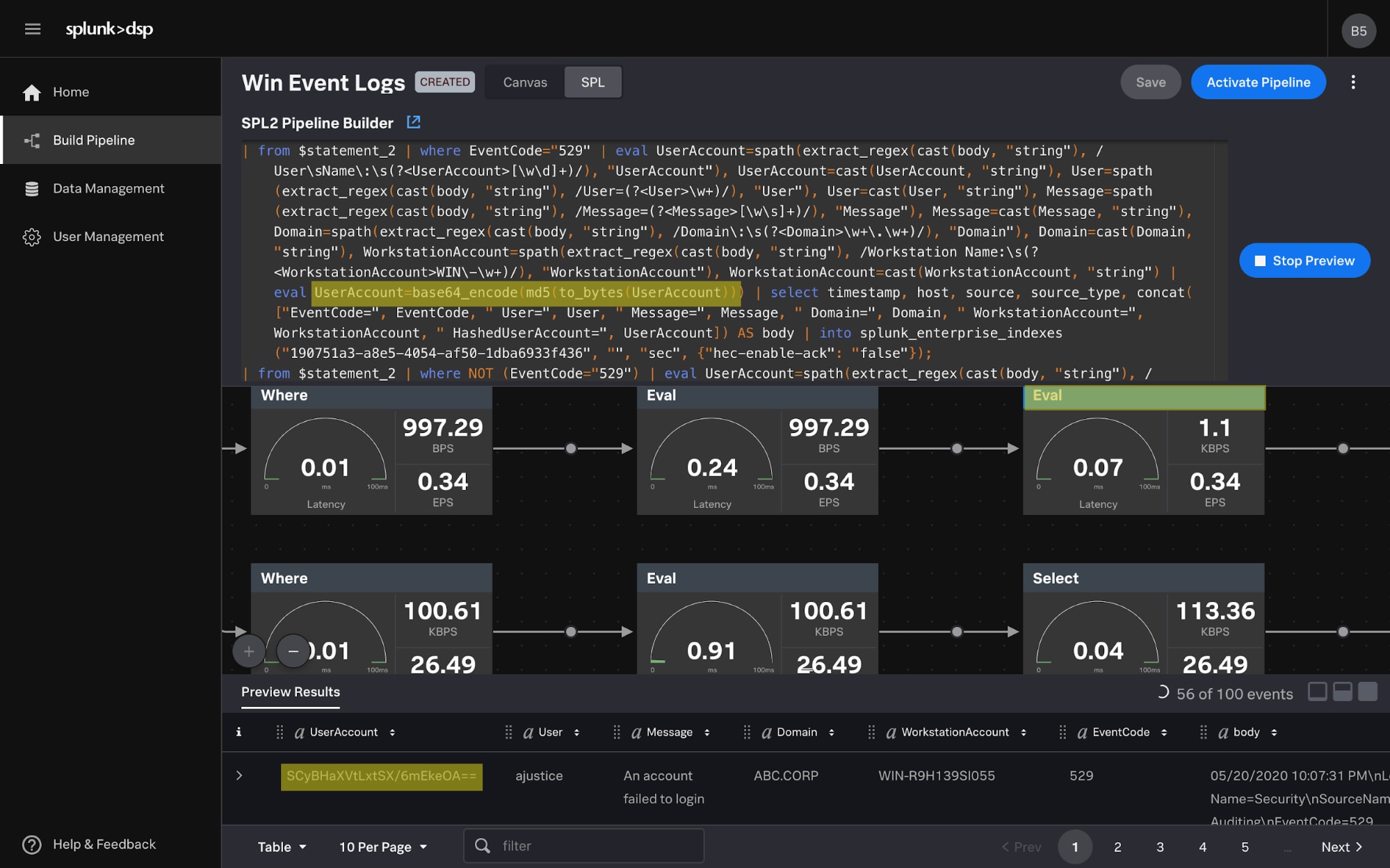
In addition, many on-premises data sources utilize syslog, including networking gear and security products like firewalls, intrusion detection/prevention, web proxy and anti-virus. Collection of these sources historically has been challenging—but with Splunk Connect for Syslog (SC4S) from our Splunk Enterprise platform, you can easily push them into DSP for further streaming functionality.
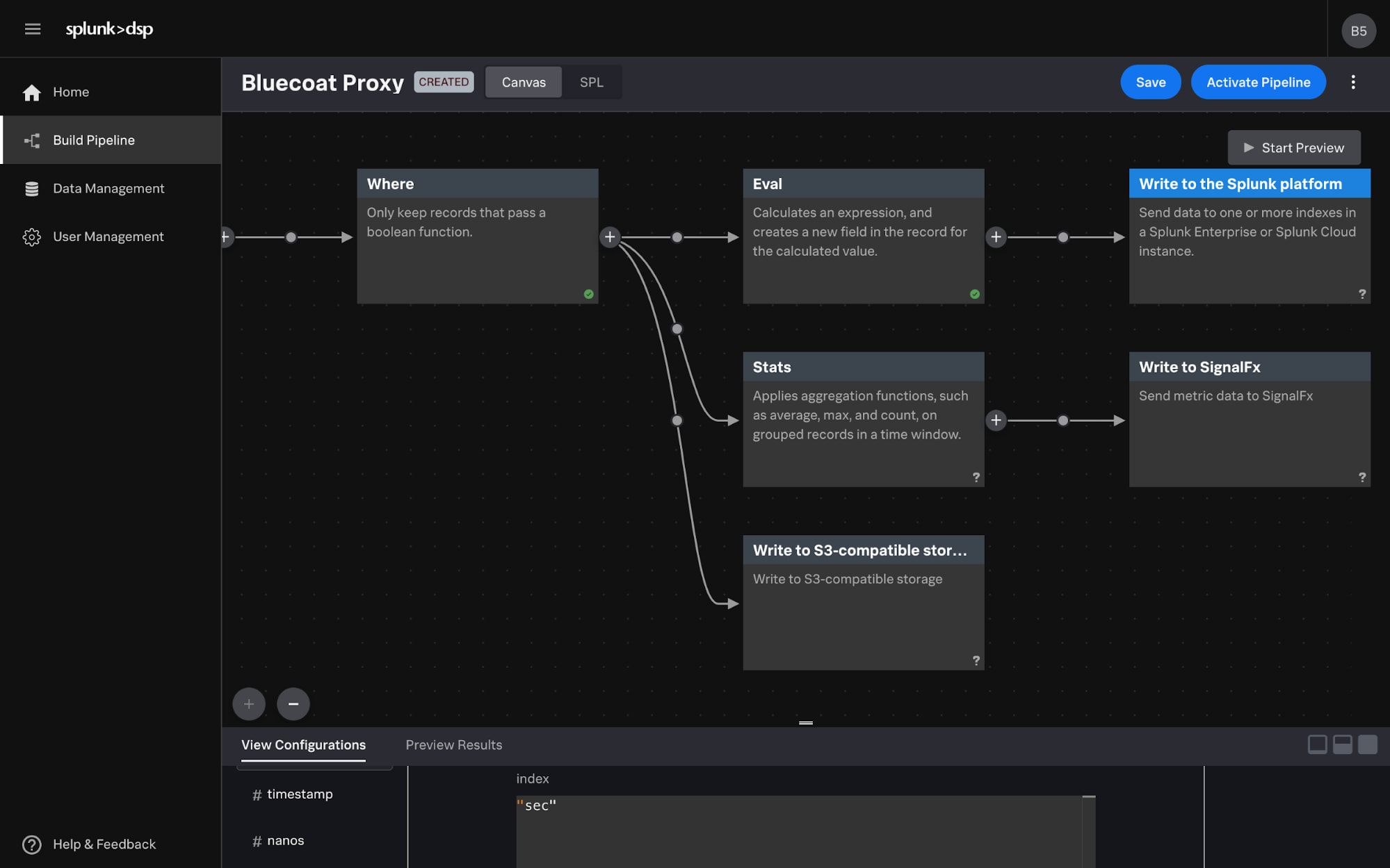
With established sinks to AWS S3, Azure Event Hubs, as well as SignalFx and Splunk Enterprise, customers can tag, then easily route data to other teams and systems—for example, tagging all relevant security data for the security team so they don’t have to search for it in multiple instances, then sending it to different locations like Splunk Enterprise for more investigation or a data lake for economical storage. This is exactly how Mars, Inc. is leveraging DSP, with the goal of having DSP act as a central hub for their data sources. Security data can be tagged, then routed by DSP directly to the Security organization which can help accelerate troubleshooting and overall security posture.
In addition, DSP builds confidence that your data is landing where it’s supposed to with data guarantees by using best in class messaging technologies supporting both publish/subscribe and queuing techniques to keep your data safe. This combined with a robust and distributed modern clustering technology which offers multiple masters for data duplication, means you don’t have to worry about losing data again.
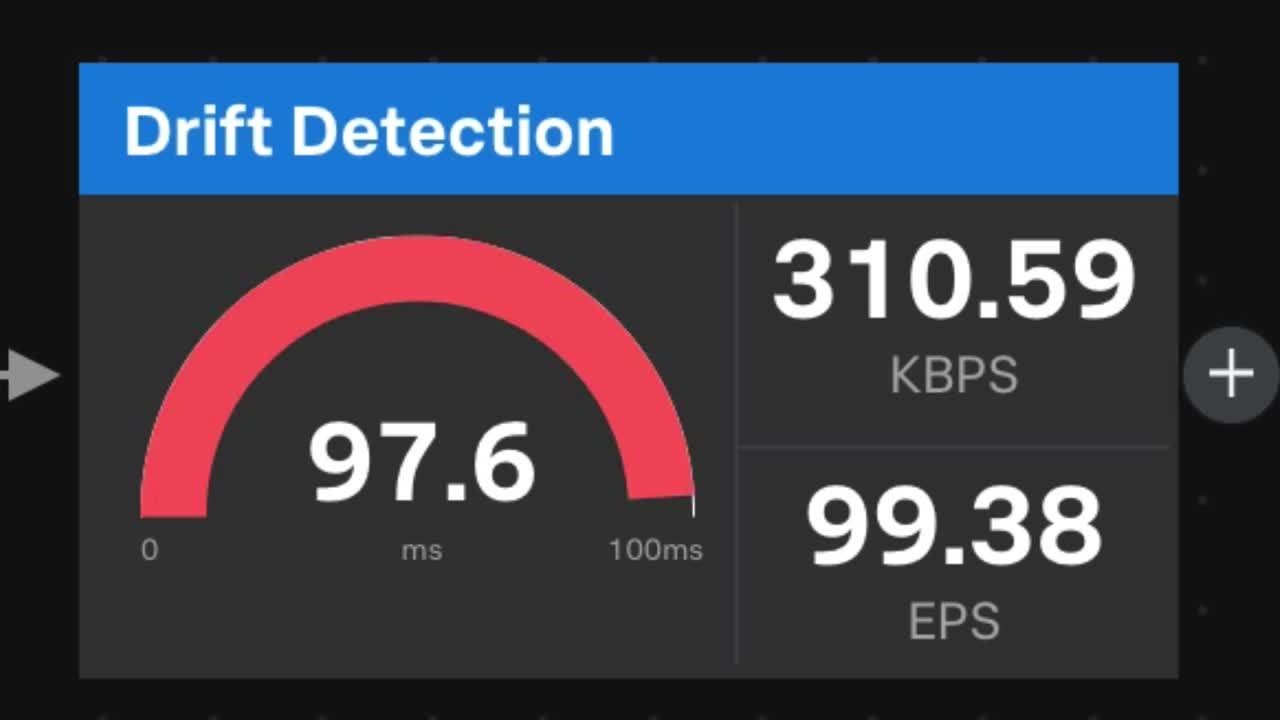
And while the machine learning capabilities are still in beta, DSP 1.1 leverages a number of new predictive features, specifically around adaptive thresholding, drift detection and sequential outlier detection. Traditionally, machine learning frameworks require you to clean your data, train a model and then retrain that model as data patterns change over time. DSP's streaming machine learning functions allow you to deploy out-of-the-box algorithms once and never retrain them again because they are always learning. This allows businesses to intelligently monitor things like internal network traffic as it fluctuates throughout the work week, and reduce false positives when detecting shifts in behavior or actual outliers.
Check out our Data Stream Processor page to learn more about how customers are finding success with DSP, and watch our short demo in the video below.
----------------------------------------------------
Thanks!
Cody Bunce

The Splunk platform removes the barriers between data and action, empowering observability, IT and security teams to ensure their organizations are secure, resilient and innovative.
Founded in 2003, Splunk is a global company — with over 7,500 employees, Splunkers have received over 1,020 patents to date and availability in 21 regions around the world — and offers an open, extensible data platform that supports shared data across any environment so that all teams in an organization can get end-to-end visibility, with context, for every interaction and business process. Build a strong data foundation with Splunk.

Get the latest articles from Splunk straight to your inbox.
© 2005 - 2024 Splunk Inc. All rights reserved.
