
Supercharge Your IT Monitoring
Download this e-book to learn about the 3 Pillars of Observability.

According to recent surveys and reports on the industry, Kubernetes and containers are more popular than ever. Containers and serverless functions are being mainstream and ubiquitous – with a more than 300% increase in container production usage in the past 5 years. This trend is especially true for large organizations, which are often using managed platforms and services.
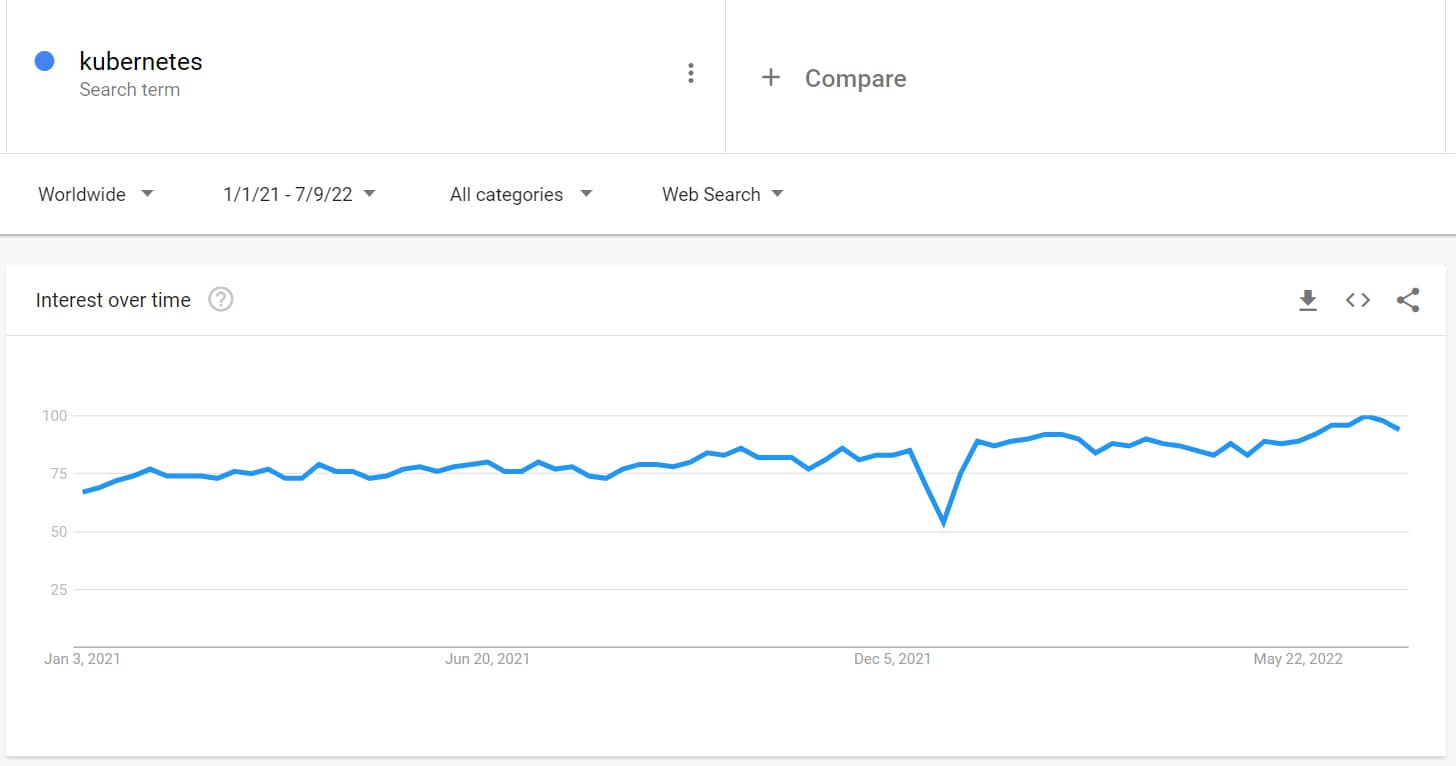
Despite a drop in interest during 2020, Google Trends shows growth in search interest for Kubernetes since the beginning of 2021. Search growth is likely to continue over the next few years as the technology further expands and with no clear competitors.
In this blog post, we’ll take a look at a variety of surveys and data that collectively describe the Kubernetes landscape. Some of the consistent trends we’re seeing in the meta-analysis include:
CNCF has conducted an annual survey of the cloud native community since 2016 to gauge adoption and trends within the industry. The most recent survey report, released in February 2022, was the largest yet with more than 3,800 participants from six continents are across a wide range of industries. This iteration of the survey was divided into two parts: (1) Kubernetes and Containers; (2) Cloud Native Technologies.
Key survey findings include:
One of the more interesting trends found in the report is the increasing usage of Kubernetes within large enterprises. Survey participants from large organizations (defined as more than 5k full-time employees) were far more likely to use Kubernetes in production than those working in smaller organizations.
Among those who participated in the first part of the survey, the majority of respondents (79%) rely on Hosted platforms like Amazon Elastic Container Service for Kubernetes (ECS), Azure Kubernetes Service, and Azure (AKS) Engine. Nearly 40% of those who took the second part of the survey indicated they rely on serverless technology like AWS Lambda and Google Cloud Functions.
Based on prior year schedules, the next CNCF will likely open in late Summer or Fall of 2022, with a report released in early 2023. You can participate in the community and contribute data to the project. Learn more by visiting https://www.cncf.io/.
Learn more about the Cloud Native Community Foundation in this podcast from The New Stack:
In addition to the annual CNCF report, another annual report was published in April 2022 by VMWare Tanzu. This survey included more than 750 respondents from organizations with more than 1k employees, including more than 200 respondents from enterprises with more than 5k full time employees.
Key survey findings include:
Nearly half of those surveyed expect their total number of Kubernetes clusters to expand by 50% in the next year.
Learn more about the role of multi-cloud in Kubernetes in this short video from VMWare Tanzu’s own Michael Coté:
More from our 2022 State of Kubernetes Survey. Here, I look at the deal with "multi-cloud" - is that a thing or just a bunch of words? Check out more in my analysis of the survey: https://t.co/oO1ROLJzyq
— Michael Coté (@cote) April 28, 2022
Released in May 2022, the State of Kubernetes Security report from Red Hat (and previously published by StackRox) has valuable insight into how organizations are dealing with some of the biggest security challenges. While a smaller total number of respondents than the other two surveys in this analysis, this report includes respondents from all sizes of organization and industries. Roles of the survey participants included: Security, Compliance/Risk, Operations, and Product Development/Engineering.
Key findings from this report include:
Despite security concerns, Kubernetes is growing and becoming a fundamental part of the technology stack for many large organizations. More organizations are using Kubernetes, containers, and serverless functions – and in more ways encompassing more use cases. This technology has “crossed the chasm”, moving from small-scale isolated and often vanilla deployments to becoming critical infrastructure.
If you are using container and Kubernetes, its vital to setup proper monitoring. Download a free copy of Splunk’s e-book The Modern Guide to Container Monitoring and Orchestration to learn best practices for how to setup and monitoring your Kubernetes environment.
Like this post? Be sure to check out our coverage of the State of DevOps!
This posting does not necessarily represent Splunk's position, strategies or opinion.

The Splunk platform removes the barriers between data and action, empowering observability, IT and security teams to ensure their organizations are secure, resilient and innovative.
Founded in 2003, Splunk is a global company — with over 7,500 employees, Splunkers have received over 1,020 patents to date and availability in 21 regions around the world — and offers an open, extensible data platform that supports shared data across any environment so that all teams in an organization can get end-to-end visibility, with context, for every interaction and business process. Build a strong data foundation with Splunk.

Get the latest articles from Splunk straight to your inbox.
© 2005 - 2024 Splunk Inc. All rights reserved.
