
Digital Resilience Pays Off
Download this e-book to learn about the role of Digital Resilience across enterprises.
Distributed tracing has become popular in recent times as the preferred way to troubleshoot complex problems in diverse, microservice-based applications. And for good reason: distributed traces give DevOps teams end-to-end visibility into user requests (transactions) as they flow through an application and interact with individual services. But one area where distributed tracing is largely underutilized is the monitoring of service availability and performance. When used correctly for monitoring, the data available from distributed traces can be a treasure trove of information to Ops and SRE teams who need to keep a watchful eye over the entire application along with developers who are trying to troubleshoot a difficult, P99 issue.
As part of our strategy to offer our customers the most comprehensive, next generation APM solution, we specifically designed Splunk APM to use distributed trace data in a way that we can provide directed troubleshooting and application monitoring, all in one best-in-class product. To do this, we knew we needed to observe every transaction and run real-time, sophisticated analysis on trace data in order to develop accurate baselines, derive service dependencies, map topologies, and catch all anomalies. Only then would our customers be able to effectively monitor and troubleshoot their increasingly complex, cloud-native applications without needing to rely on custom application metrics or switching between multiple tools.
Distributed tracing is treated as a second class citizen by legacy APM tools because it fundamentally does not fit well with proprietary agents and head-based probabilistic sampling. New Relic, AppDynamics, and Dynatrace force customers to use heavy, proprietary agents that have limited support for distributed trace data, and result in excessive resource consumption on hosts, high maintenance, and worst of all vendor lock-in. Datadog also limits visibility into transactions by employing a random, head-based sampling approach that is proven to miss anomalies, which, as with the other alternatives, makes it difficult to provide accurate and reliable alerts in real-time.
Our approach to building Microservices APM is fundamentally different. We leverage our industry-leading, real-time infrastructure monitoring platform with the SignalFlow®-powered streaming analytics engine, and combine it with a set of unique capabilities purpose-built for today’s complex, microservices-based applications:
As a result, Splunk APM observes and analyzes 100% of traces and spans via our Smart Gateway and, during the process, generates RED metrics for each trace and span. These metrics feed built-in service and endpoint dashboards that provide users with a unified view across services and infrastructure. They are also the cornerstone to our new real-time, AI-driven problem detection algorithms, which now enable us to identify unique patterns and dynamically create baselines that are critical to accurately surfacing any anomalies in real-time. The net result for customers is a unified and powerful Microservices APM solution that enables orders of magnitude reduction in problem detection – mean time to detect (MTTD) – and problem resolution – mean time to resolve (MTTR).
Today, we announced four enhancements to Splunk APM that further extend our ability to help DevOps teams effectively monitor microservices-based applications in real-time:
Real-Time, AI-Driven Application Alerts: Splunk APM alerts now extend existing infrastructure alerting functionality with AI-driven advanced analysis that operates on automatically-generated trace metrics (e.g. error rate or latency). By leveraging the innovative NoSample tail-based approach that observes every transaction and the RED metrics that are automatically generated for each trace and span, Splunk Infrastructure Monitoring now provides the most accurate service-level monitoring and alerting. The alerts from Splunk APM also exploit the full power of our SignalFlow streaming analytics engine, so they are real-time, flexible, and easy to configure. Splunk APM alerts can be triggered based on multiple conditions, sudden changes, and historical anomalies, and have a built-in mechanism to adjust for low-data volumes to avoid inaccurate alerts. These self-configuring alerts learn and trigger on behavior changes, and remove the guesswork and back-and-forth associated with manual configuration. This helps DevOps and SRE teams quickly detect sudden spikes and historical anomalies in services and endpoints, resulting in the shortest mean time to detect (MTTD) and mean time to resolution (MTTR) solution in the industry.
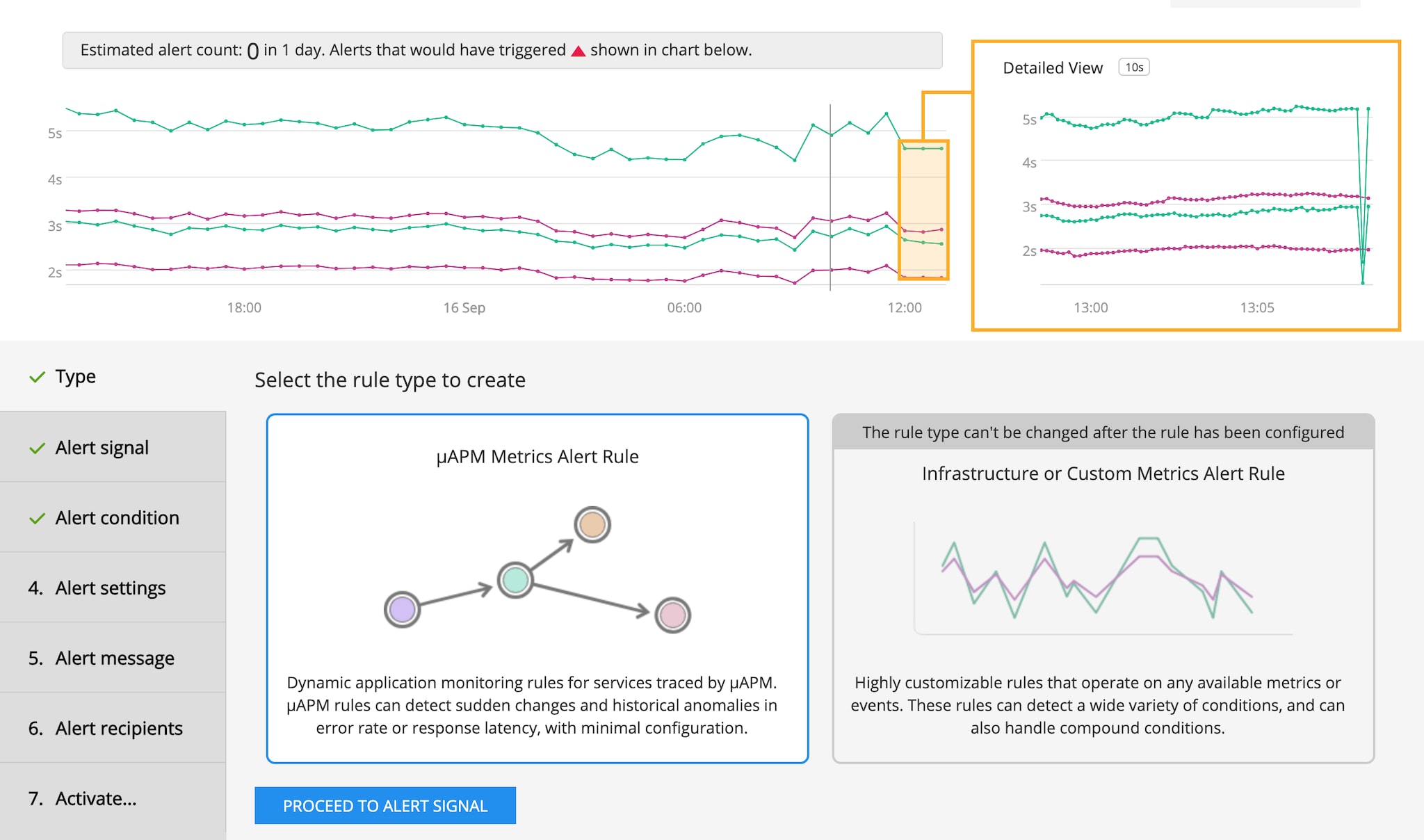
From the services tab in Splunk APM, you can set up service-level alerts based on error rate or latency.
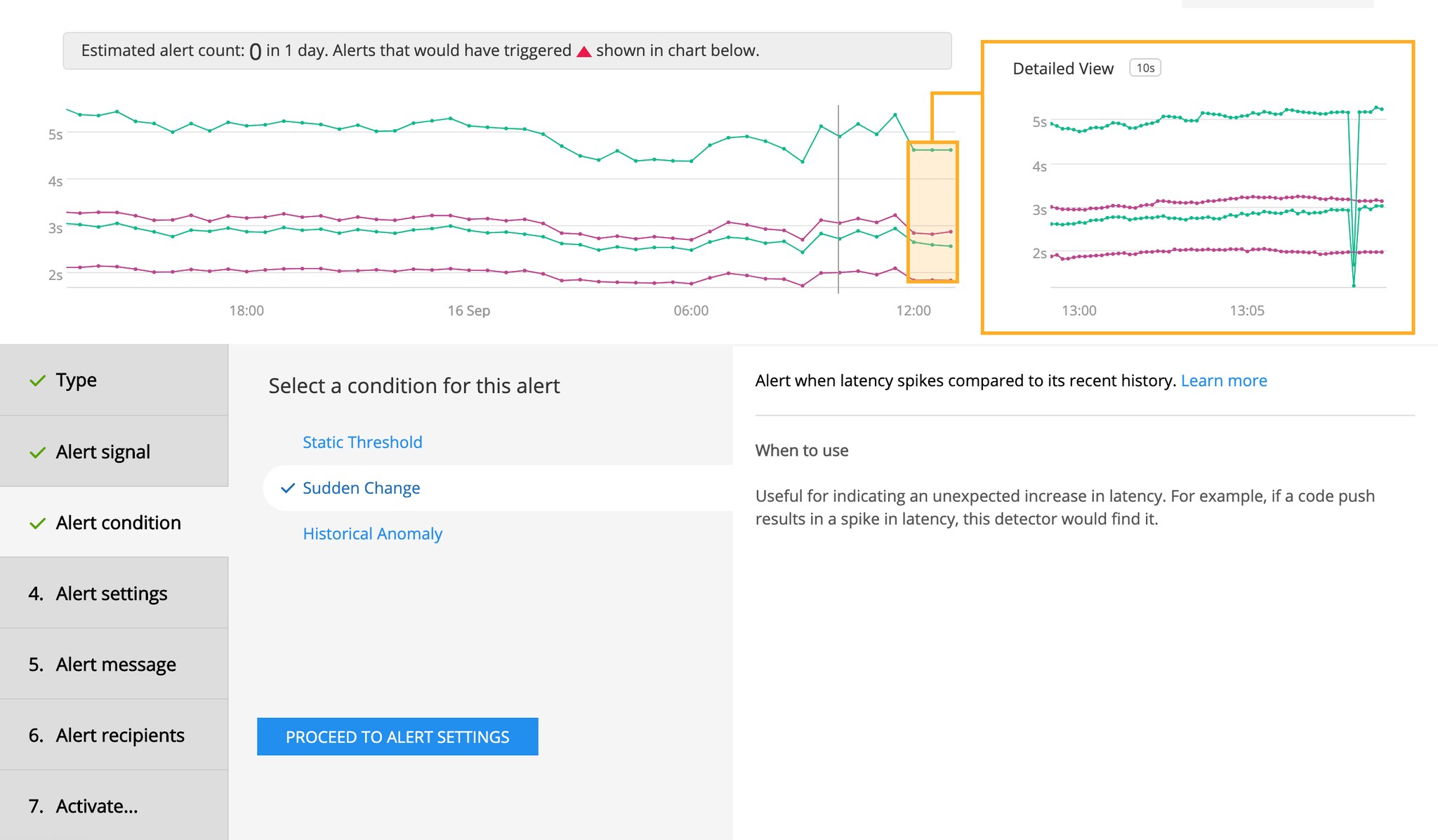
Splunk APM provides built-in algorithms to for complex conditions such as sudden change and historical anomaly.
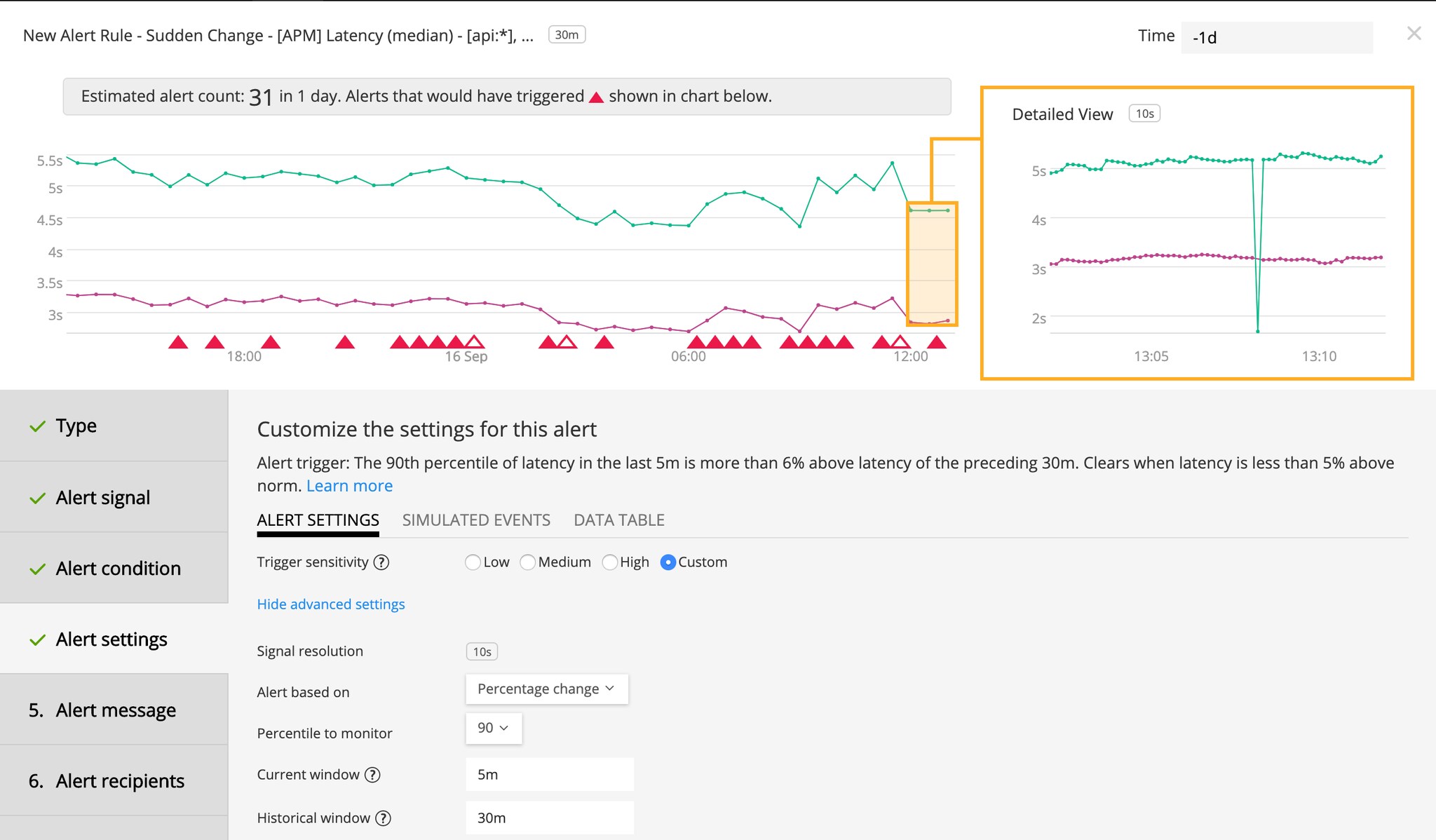
Alert previews show you ahead of time how many alerts would have been triggered with your settings, so you can optimize your rules.
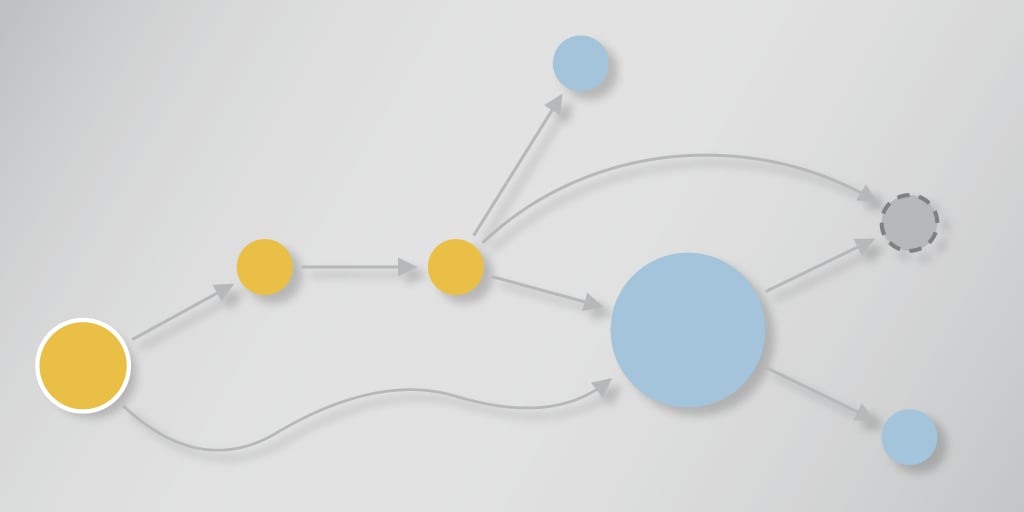
Enhanced Service Maps: We’ve enhanced existing service maps with the ability to automatically infer services that are not explicitly instrumented, including databases, message queues, caches, and third party web services. Visibility into inferred services gives monitoring teams a much more complete picture of how their application is behaving by having real-time visibility into all related service dependencies. With this enhancement, you can now view inferred services in our dynamic service map, search across all traces, slice-and-dice to view specifics for inferred services, and view traces that span inferred services. Combined with existing service performance and alert status details in the service map, you can more easily visualize, correlate, and pinpoint potential issues in complex microservices environments. If any inferred services are contributing to the latency or error rate of a specific transaction, they’ll be picked up by our Outlier Analyzer™ as an anomalous span in a trace. With Outlier Analyzer, users can more easily correlate and pinpoint potential issues in complex microservices environments that include non-instrumented services.
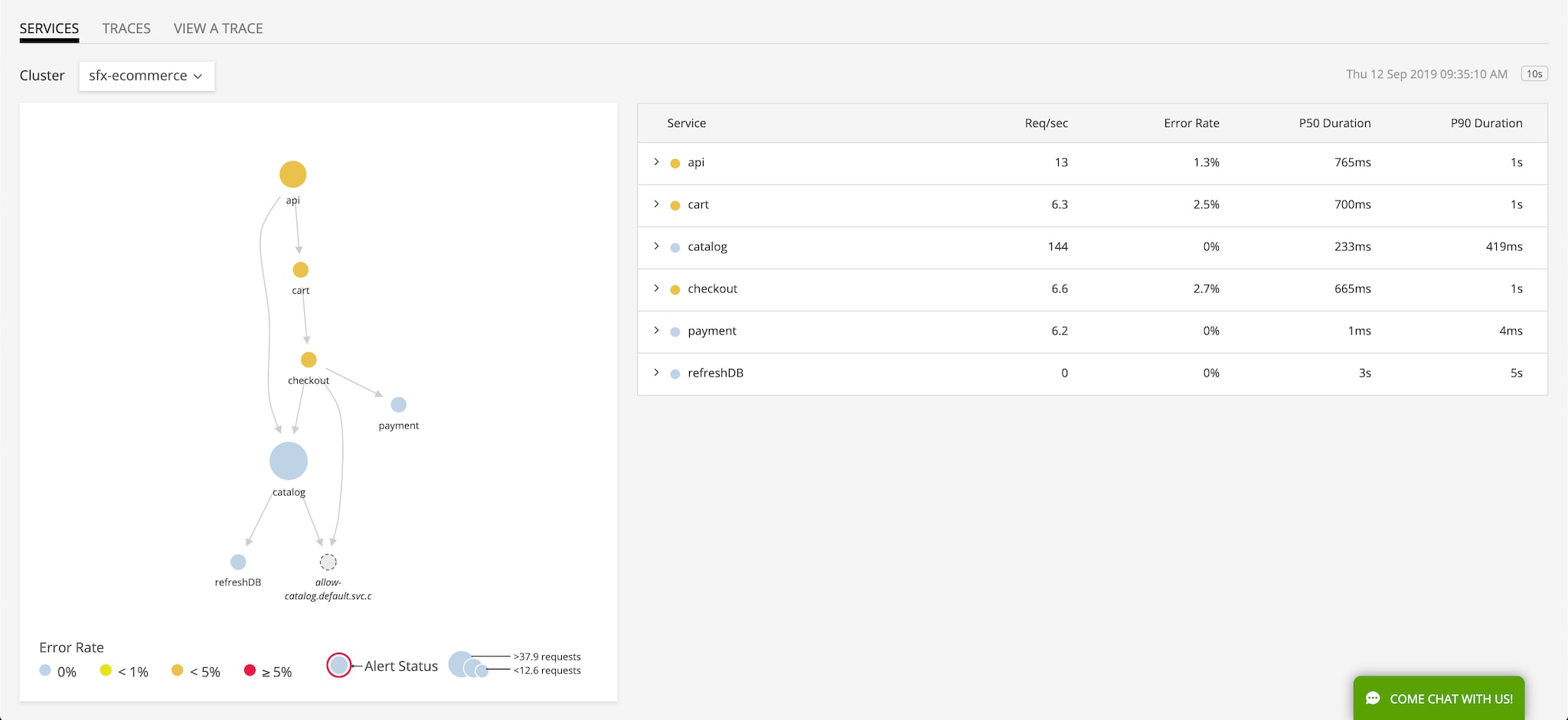
Inferred services are displayed in the service map as dashed icons and have different shapes based on their type – database, cache, pub/sub, or http.
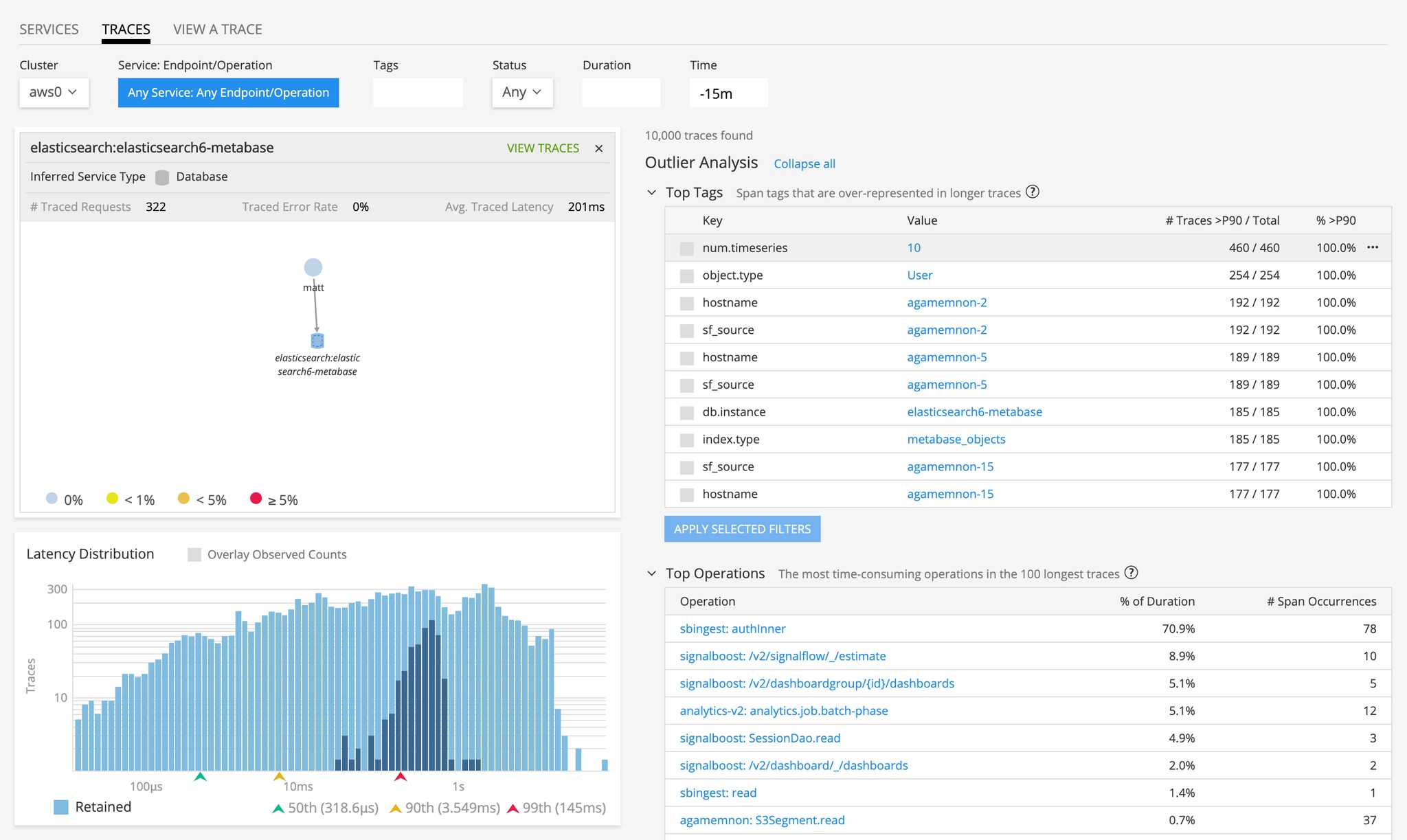
Outlier Analyzer provides out-of-the-box support for inferred services.
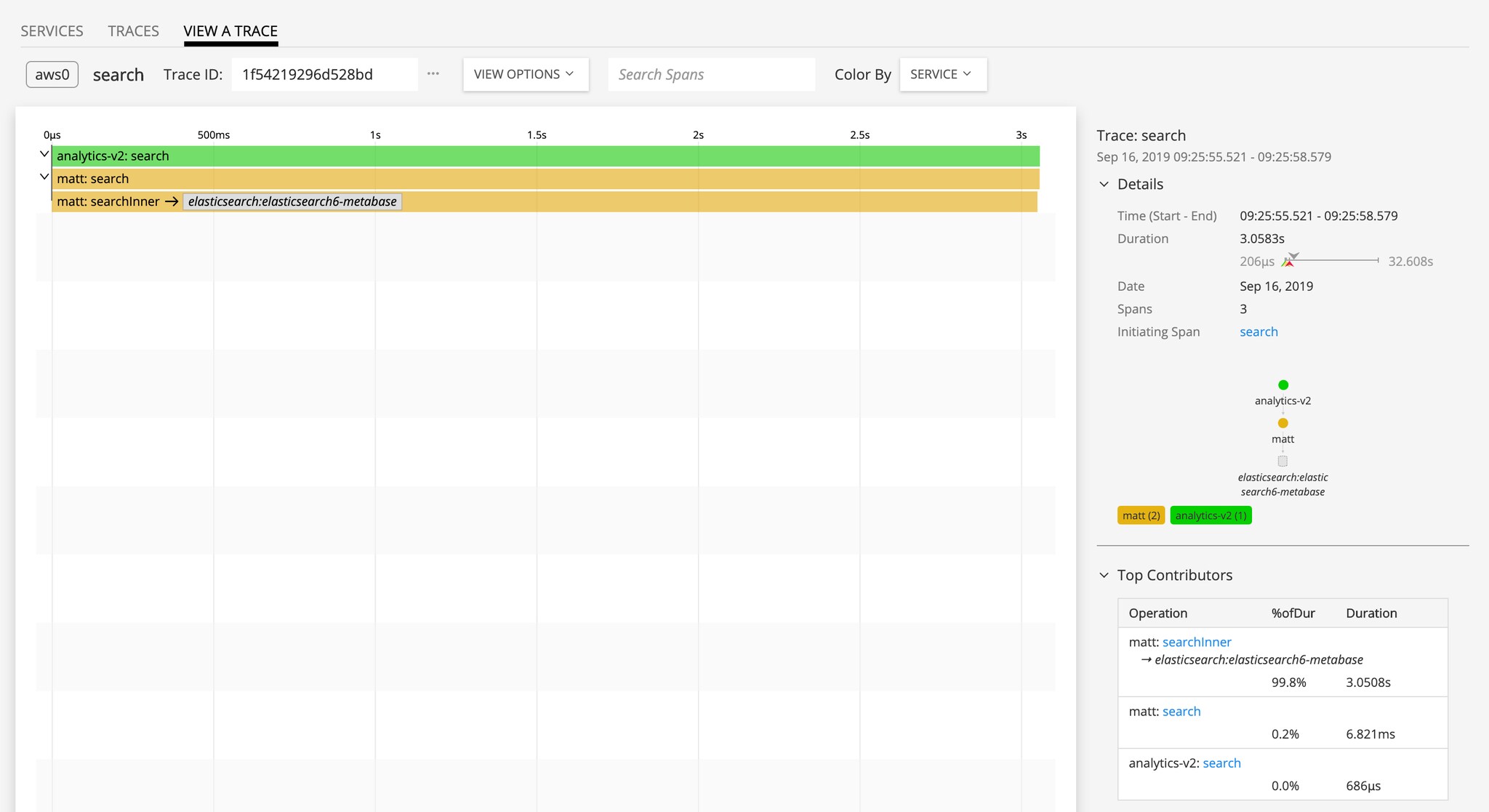
Calls to inferred services and their contribution to latency are clearly identified within individual transactions.
Database Query Metrics: Many customers have asked us for visibility into database performance, so we will be introducing database query metrics within the next month, which contain details such as the most frequently run queries and the longest running queries over a period of time. This makes it easy to not only spot problematic databases but also potential problems on a specific database instance. Since databases are now picked up as inferred services in Microservices APM, any long running queries that impact database performance will be detected by our Outlier Analyzer and show up as part of an anomalous trace. So if there is a problem with your database, it will show up like any other problematic service. Like all other metrics in Splunk Infrastructure Monitoring, database query metrics can be used for alerting, so you can be instantly notified of any erroneous conditions, such as excessively high latency and the like.
New Auto-Instrumentation Options: We’re also expanding our auto-instrumentation capabilities to include the addition of three languages: Kotlin, Go, and PHP. Kotlin is already generally available, and Go and PHP will follow in GA and Beta, respectively, later this quarter. Along with existing support for Java, Python, Ruby, and Node.js, this brings us to a total of seven auto-instrumented languages and hundreds of different libraries and frameworks. In addition to these auto-instrumentation options, Splunk APM also supports custom and bytecode level auto-instrumentation for JVM based languages. Unlike many of the legacy APM vendors in the market like New Relic, AppDynamics, and Dynatrace, we believe that customers should not be forced to use proprietary agents. We want our customers to have the flexibility to choose not only the language but also the method of data collection that best fits their application. Along with our wide range of auto-instrumentation language support, we also support the most popular open standards for distributed tracing, including OpenTracing, OpenCensus (active contributor), Jaeger, and Zipkin.
Over the coming weeks, we’ll post additional blogs that go into more details on each of these four new features. Until then, reach out to us if you have any questions or would like to learn more.
If you’re not already using Splunk Infrastructure Monitoring, get started with a free trial.
----------------------------------------------------
Thanks!
Jeff Lo

The Splunk platform removes the barriers between data and action, empowering observability, IT and security teams to ensure their organizations are secure, resilient and innovative.
Founded in 2003, Splunk is a global company — with over 7,500 employees, Splunkers have received over 1,020 patents to date and availability in 21 regions around the world — and offers an open, extensible data platform that supports shared data across any environment so that all teams in an organization can get end-to-end visibility, with context, for every interaction and business process. Build a strong data foundation with Splunk.

Get the latest articles from Splunk straight to your inbox.
© 2005 - 2024 Splunk Inc. All rights reserved.
