
Digital Resilience Pays Off
Download this e-book to learn about the role of Digital Resilience across enterprises.

We are very excited today to introduce Splunk APM, the newest component of the Splunk Infrastructure Monitoring for monitoring of microservices-based applications. At Splunk, we strive to deliver the industry’s most powerful cloud monitoring solution to accelerate our customers’ journey to cloud-native. With monoliths and legacy applications getting re-engineered as service-oriented architectures, enterprises need a new class of application monitoring tools to get visibility into transactions that now travel through complex paths across distributed services.
Traditional APM is a misfit for monitoring microservices. In a multi-part blog series, we outlined the shortcomings of the existing APM solutions and the need to fundamentally transform application monitoring to support cloud-native architectures.
Industry analysts have reported similar challenges experienced by their clients. In a recent research report Gartner said:
"Most APM solutions were designed for a prior generation of applications that were monolithic and long-lived. These approaches are ill-suited to the dynamism, modularity and scale of today’s emerging microservice-based applications."
Practitioners also see the complexity of microservices. This tweet, which went viral because it rings true, is a particularly humorous take on the challenge:
No doubt. Troubleshooting microservices in the middle of the night with traditional APM solutions seems like solving a murder mystery because:
In this blog, we will lay out how Splunk APM addresses these gaps with a unique set of capabilities and features:
Traditional APM vendors and open-source solutions only capture a small and arbitrary portion of your transactions via probabilistic sampling, leaving you blind to actual issues. To quote one of our customers: “Sampling is the elephant in the war room!”
We tackled one of the biggest shortcomings of traditional APM with a unique approach to sampling trace data. Splunk APM is built on a unique architecture that we refer to as NoSample™. Unlike other APM tools, Splunk analyzes 100% of transactions throughout your distributed services and intelligently captures errors, anomalies, and outliers. This approach – also known as ‘tail-based sampling’ – is implemented via the Smart Gateway, a highly scalable and intelligent relay that lives in the customers’ environment.
The chart below shows the stark difference between the head-based sampling strategy used by most of the APM vendors and the Splunk Infrastructure Monitoring NoSample Architecture approach. Splunk Infrastructure Monitoring NoSample approach captures all outliers so that you don’t miss crucial trace data when you are troubleshooting a performance issue. Our early testing with customers shows that visibility into anomalous and long-tail traces increases by 10x using a tail-based sampling approach.
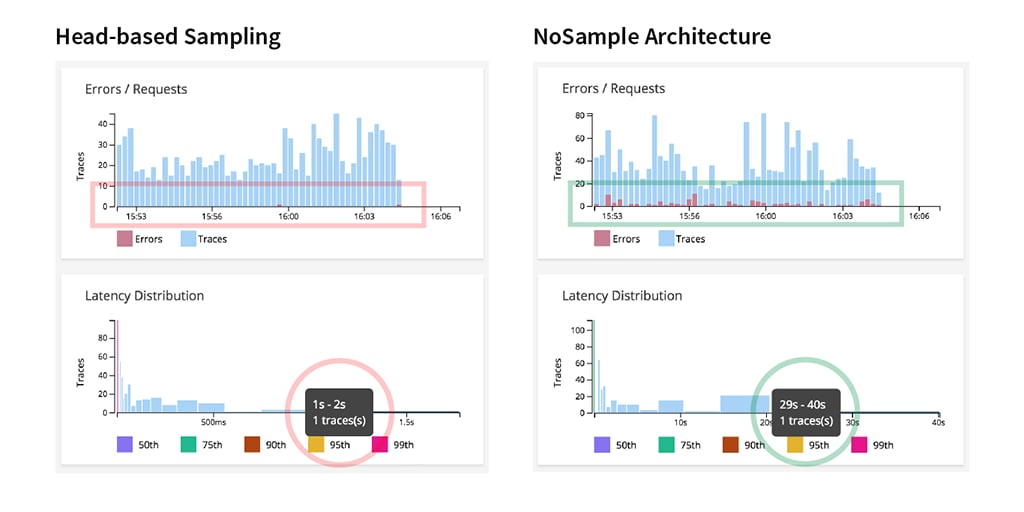
Fig 1: Head-based sampling vs Splunk Infrastructure Monitoring NoSample Architecture approach
Splunk Infrastructure Monitoring NoSample Architecture assures that you will have the trace data when you need it the most to troubleshoot end-user issues. Next, you need to narrow down to the right traces quickly to begin incident resolution.
Narrowing down whether a performance issue is caused by infrastructure or application code can be like looking for needles in a haystack. Traditional APM tools require you to manually correlate performance issues across different layers of the application stack – resulting in higher MTTR, siloed troubleshooting, war room scenarios, and finger-pointing.
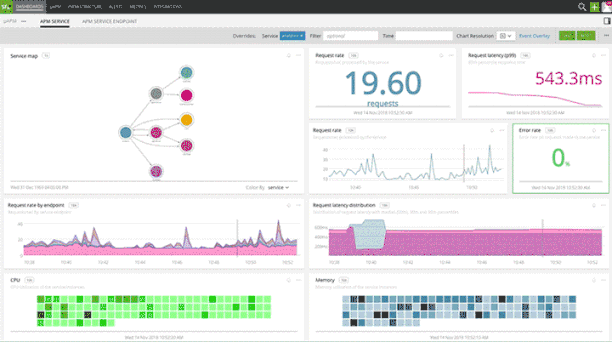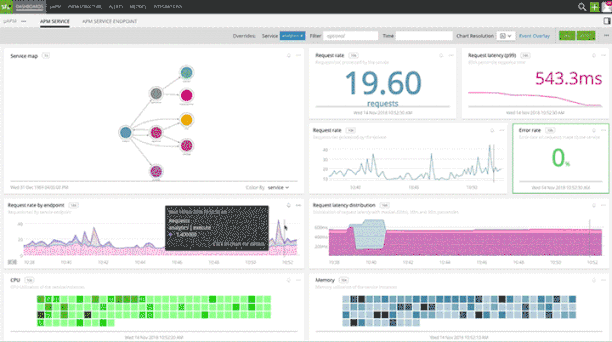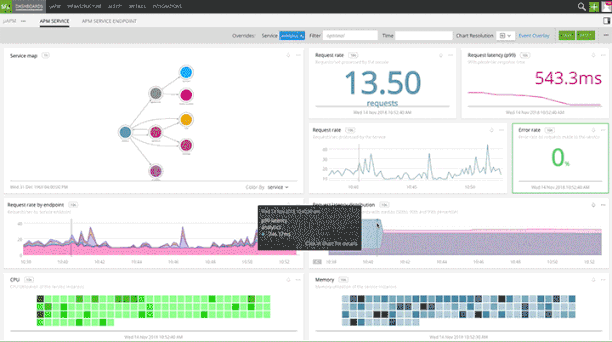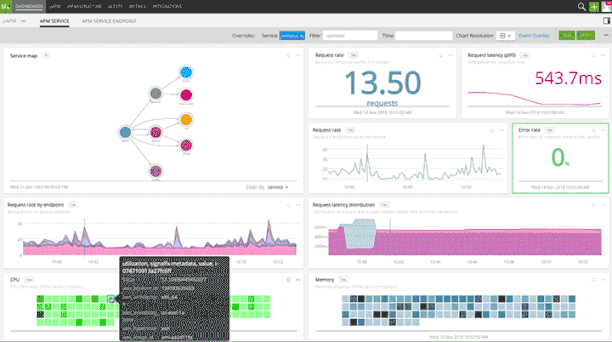
Fig 2: Service and Endpoint dashboard with infrastructure correlation
Splunk APM provides an intuitive, end-to-end service map to quickly isolate the service which is causing the latency spike. You get pre-built dashboards for every service and all endpoints. Built-in infrastructure correlation helps immediately identify the root cause of a performance issue and engage the right team for resolution.
"Splunk Infrastructure Monitoring acts as a single source of truth for our teams. Service dashboards reduce our mean time to engage as they quickly narrow down the performance issue to code or infrastructure and help us engage the relevant team quickly."
- Senior DevOps Manager, Manufacturing Design SaaS Firm
Tagging metrics and traces with dimensional key-value pairs and labels is a common practice in modern monitoring systems. However, as the number of dimensions grows, traditional APM solutions struggle to search and filter data without incurring performance penalties.
Splunk Infrastructure Monitoring provides a multi-dimensional data model and the industry’s best high-cardinality analytics capabilities, giving you the infinite flexibility to slice and dice trace data and quickly isolate relevant traces and spans.
Cloud-native deployments can be extremely complex to debug and troubleshoot because of the increased number of individual components backing an application. There can be many factors causing the latency of a transaction to go up. Where do you start your troubleshooting efforts? When using existing APM solutions, our customers told us they needed to examine each and every outlier trace and manually correlate among the traces to determine a pattern before starting troubleshooting.
Splunk Infrastructure Monitoring solves this challenge for our customers by using the latest innovations in data science. Outlier Analyzer uncovers patterns relating trace tags to trace durations, highlighting possible explanations for degraded system performance (or slowness in steady state). It automatically can answer questions such as:
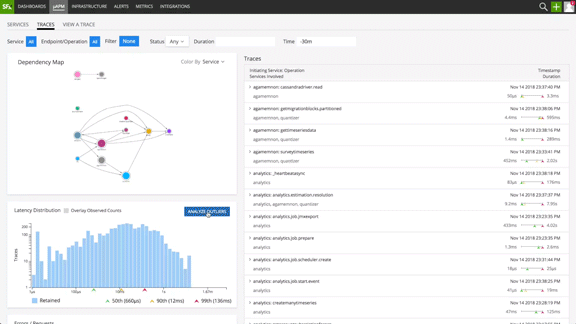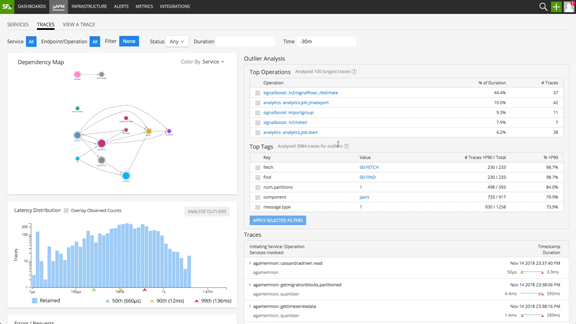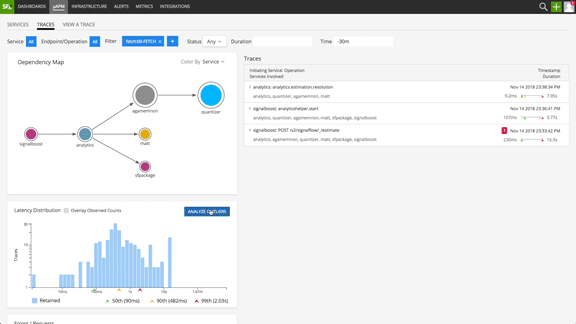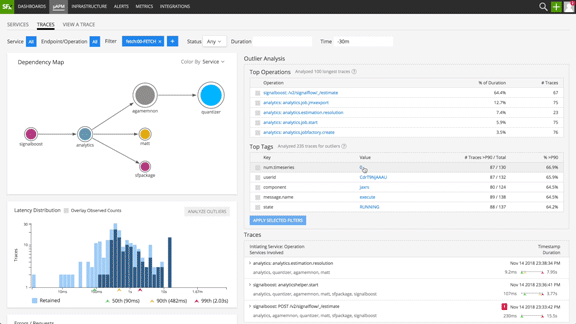
Fig 3: Outlier Analyzer surfacing most commonly represented patterns in the long tail transactions
Outlier Analyzer offers prescriptive insights to significantly reduce MTTR. One of our customers put it simply: “Before Outlier Analyzer we used to open 50 tabs and try to understand patterns manually ”
When a particular span contributes most to the latency of a trace, how do you determine whether this is a normal behavior, or that a bug got introduced in a canary version of your code?
Other APM solutions capture RED metrics at the service level, or at best provide metrics at the root, originating span, giving you a very partial view of your environment.
The Smart Gateway observes every single transaction across distributed services, assembles the traces, and metricizes all of your traces and spans into metrics automatically. Additionally, it keeps the distribution of the performance at the trace execution path, as well as at the span level.
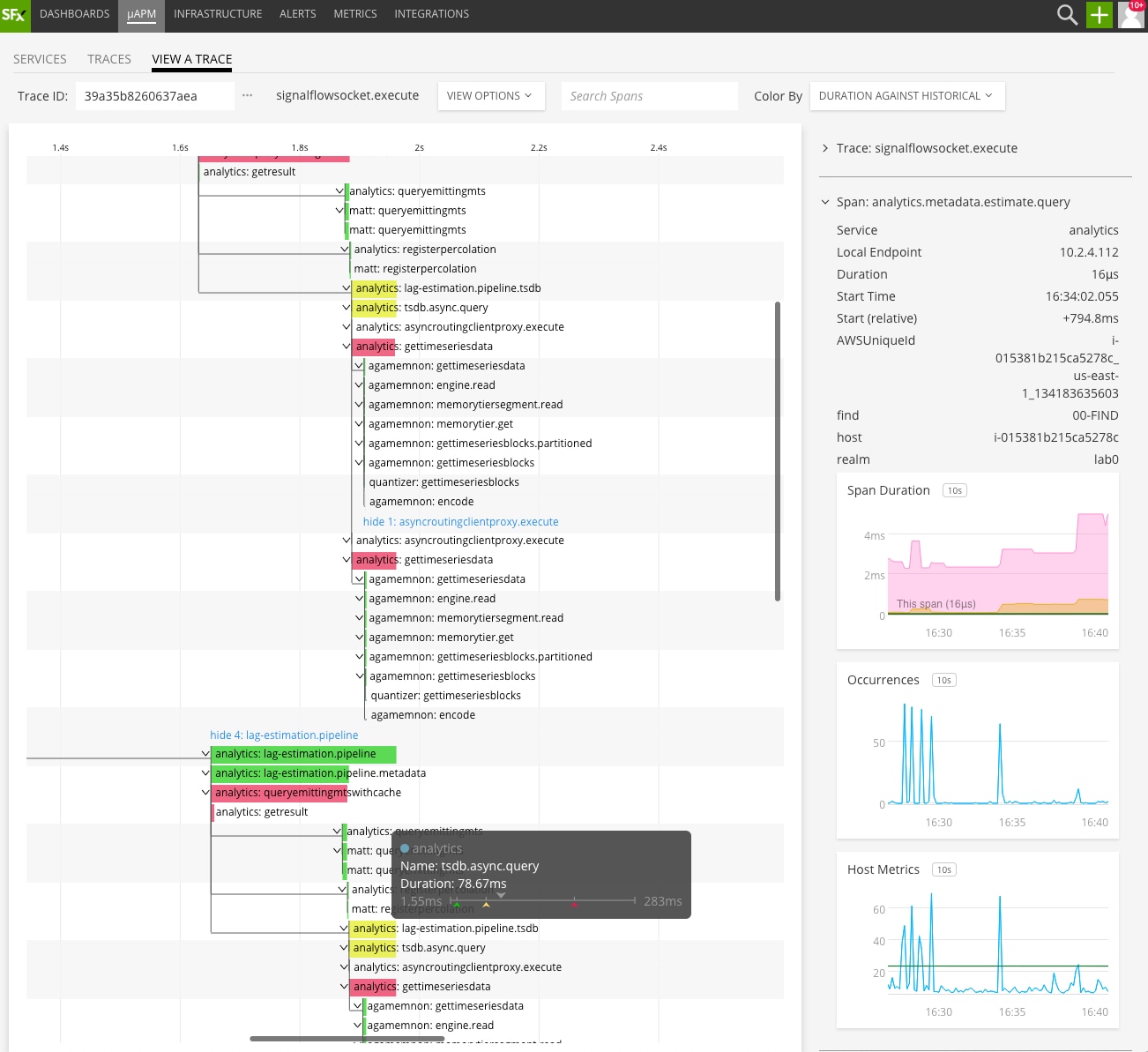
Fig 4: Span performance details with historical comparison alongside infrastructure correlation – all within the trace context
Metricization provides you out-of-the-box, real-time visibility into the health of microservices deployed, as well as the historical performance trends at the span level. You can quickly determine how a new code release performs compared to historical baselines and automatically identify what is contributing the most to the latency of your transactions – down to the specific line of code.
In short, span-level metricization enables you to understand what constitutes normal performance behavior for any span or trace.
Splunk Infrastructure Monitoring does all of these things to expedite the incident response process and significantly reduce MTTR, while giving complete flexibility to our customers for instrumentation so they can remain vendor-neutral. You can choose any or a combination of following instrumentation methods:
Additionally, Splunk Infrastructure Monitoring Auto Instrumentation agents and libraries, built upon open standards, provide automatic instrumentation for the most commonly used open source packages and frameworks.
It’s no secret that every company is a software company today, and software is driving new digital business initiatives. It is also true that distributed systems are much more complex compared to monolithic environments. Today, we have taken a huge step toward helping our customers successfully adopt cloud-native architectures by cutting through microservices complexity with Splunk APM.
Splunk APM is feature packed. We’ve just scratched the surface here and can’t wait to show you all the features we’ve built that will accelerate your journey to cloud-native.
Check out key fetures of Splunk APM in the video below:
This post contains contributions from Maxime Petazzoni and Amit Sharma.
----------------------------------------------------
Thanks!
Amit Sharma

The Splunk platform removes the barriers between data and action, empowering observability, IT and security teams to ensure their organizations are secure, resilient and innovative.
Founded in 2003, Splunk is a global company — with over 7,500 employees, Splunkers have received over 1,020 patents to date and availability in 21 regions around the world — and offers an open, extensible data platform that supports shared data across any environment so that all teams in an organization can get end-to-end visibility, with context, for every interaction and business process. Build a strong data foundation with Splunk.

Get the latest articles from Splunk straight to your inbox.
© 2005 - 2024 Splunk Inc. All rights reserved.
