
Digital Resilience Pays Off
Download this e-book to learn about the role of Digital Resilience across enterprises.

In today’s world, organizations need to continually learn to be successful. Learning from both challenges and successes in order to implement incremental improvements is critical. When customers experience an issue, organizations need to restore services quickly and to incorporate learnings in order to prevent the same issue from recurring.
Degradation conditions on performance and availability in a modern, distributed architecture are increasingly complex. Understanding patterns and uncovering the right signal to monitor often requires an iterative approach of fine-tuning and updating existing alerts. When an issue around performance arises, it is critical to have the visibility to identify the symptoms and the flexibility to analyze the root cause.
On August 26, we experienced a degradation in the SignalFx service. We heard from our customers that their charts and dashboards were taking a long time to load. We even noticed some slowness ourselves as some dashboard charts were stuck in the “Requesting data…” stage of chart load for minutes.
SignalFx is instrumented to report the total number of chart load requests and the number of those that loaded within five seconds. Both metrics are emitted to SignalFx for monitoring and alerting. This chart shows the behavior of these metrics on a typical day: blue is total requests over the last five minutes and pink is number of those loaded within five seconds.
Here, we see the behavior of these metrics exactly 24 hours later during the service degradation.

Prior to this, we had not experienced a failure mode that manifested itself in chart load time. We took this opportunity to refine the signals we monitor to track the performance and health of the SignalFx app.
The natural quantity to compute is the “error” rate, i.e., the number of requests that took more than five seconds to serve divided by the total number of requests. This quantity, computed over five minute intervals, is shown here. The elevated values indicate a potential issue.
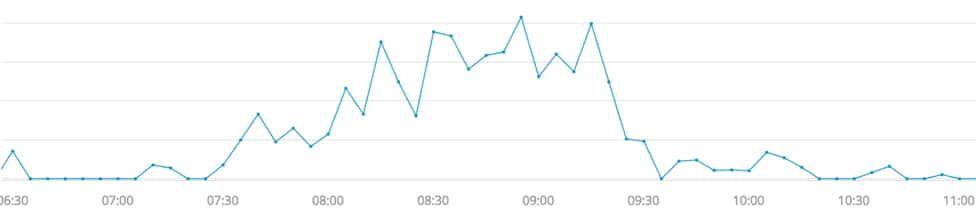
The error rate is a sensible metric on which to base alerts since it is scale invariant: if usage of SignalFx doubles within a few months, we would expect the number of requests and the number of slow loads both to (roughly) double. The error rate remains the same.
Determining a threshold for the error rate is guided by a combination of historical data and business requirements. By panning within a chart covering a period of several days, we can easily examine historical data within SignalFx. The error rate generally stays below 10% during regular business hours. Here is an example of three typical days:

The 1-day rolling mean plus three standard deviations (shown below in green) indicates the upper end of the distribution of error rates.

In this case we choose to combine the statistically-defined dynamic threshold with business requirements and declare that an error rate above the minimum of 20% and the dynamic threshold should enter into the alert logic.
In other words, fire an alert when the error rate is unusually high (i.e., is the error rate larger than the rolling mean plus three standard deviations?), but enforce the business requirement that most charts need to load quickly in any case.
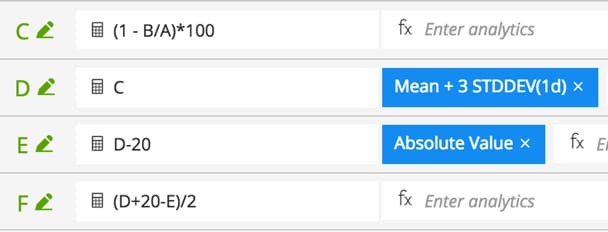
This composite threshold is captured in line F. Signal A contains the total number of chart load requests over the last five minutes and signal B contains the number of those requests served within five seconds. Thus line C corresponds to the error rate and D is the dynamic threshold based on the error rate. The composite threshold uses the formula for the minimum of two numbers:
min(x, y) = (x + y – |x-y|) / 2.
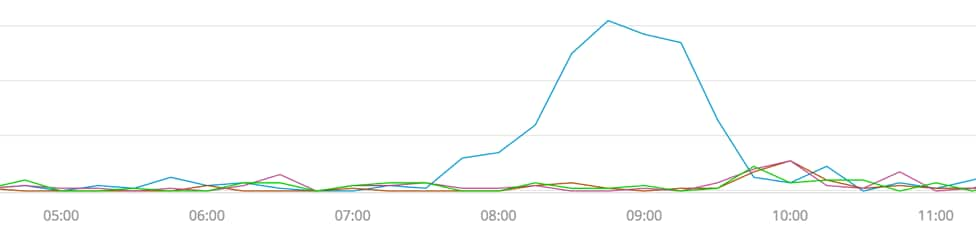
While the error rate is a useful measure of application performance, using it alone suffers from a serious drawback: the error rate may be high, by chance, during periods of relative inactivity.
For example, a 50% error rate overnight might just mean that two of four wall TVs are unhappy with the performance of our app. The error rate during an example period outside business hours is shown in this chart.

Slow load of a small number of charts outside business hours is not sufficient reason to page the on-call team. Thus we seek an alert that fires when the error rate and the number of slow loads are both elevated.
The threshold for the number of slow loads is difficult to divine. Since these metrics are driven directly by user engagement, we expect a weekly periodicity. Using the timeshift function in SignalFx, we can examine the behavior of this metric (the number of slow loads) after smoothing and compare to values one, two, and three weeks ago. The approximate alignment validates the expectation of a (rough) weekly periodicity.

By sliding the time window, we can see the same timeshifted plots during the service issue.
Now we derive a threshold for the number of slow loads by using a comparison to the previous week. The signal H is the number of slow loads shifted by one week. From this we calculate thresholds based on the last hour and the last day.

Next, we take the maximum of K and L. During business hours, the last hour estimate will likely be larger than the last day estimate. However, during periods of relatively little activity, the last day estimate will generally be larger (and will be larger than the current values). To allow for some week-over-week variation, we multiply the larger threshold by 3.
Why did we go through the trouble of defining a threshold in terms of statistics, rather than choose some number of slow loads after the data exploration? The motivation is that the alert rule we employ should be scale invariant. If our overall load doubles, whether or not the current value exceeds the (statistically-defined) dynamic threshold will not be changed. The practical consequence is that dynamic thresholds do not require constant maintenance as the load of a system changes (for example, as new customers are added).
Note that our detector has parameters (e.g., three standard deviations) which can and should be tuned to control sensitivity, but these numbers do not affect the scale invariance of the overall detector logic.
The observed unusual behavior of total chart load requests and chart load times caused us to investigate whether these were symptoms of an underlying issue. We created a signal where the value of 2 corresponds to elevated levels of both error rate and number of slow loads. We plotted that signal over a three-day period (including the occurrence of the service degradation) to observe whether the alert would have fired or remained silent.

Note the two shorter spikes (from -2 to 0) correspond to one (but not both) of the alert conditions being met.
We now proceed to explain how to use further analytics to construct the signal shown above, i.e., to create an alert which fires when both the error rate and the number of slow loads cross our statistically defined thresholds. The error rate is signal C and the dynamic threshold for that error rate is signal F. The number of slow loads is signal G and the dynamic threshold for it is signal N.
We derive signals expressing the magnitude of the difference between the signals of interest and their corresponding thresholds.
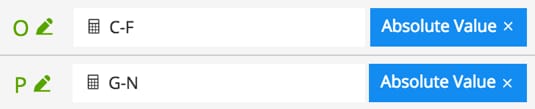
Then (C-F)/O is equal to 1 when the error rate lies above the threshold (i.e., satisfies the alert condition), and is -1 when that rate lies below the threshold. Similarly, (G-N)/P is 1 when the number of slow loads lies above the threshold, and is -1 when that number lies below the threshold. Then the sum:

Can take three possible values:
Our alert is then set to fire when Q is above 0.
At SignalFx, we work hard to ensure reliable service to our customers. While this issue was resolved by identifying a communication deadlock within a specific service cluster, we take each incident as a learning experience to improve how we monitor and alert on our production environment.
Subtle patterns in application performance metrics may provide an early indication of service degradation. We leveraged real-time visibility into our system to observe unusual behavior and hone in on the key metrics to further investigate. Analytics helped us determine a more precise signal to alert on, based on dynamic thresholds, timeshifted metrics, and algebraic operations. We had the flexibility to update our existing alert detectors so that we can take action if these patterns emerge again in the future.
It’s not always easy to catch these subtle patterns in modern, distributed architectures. But we’ve found that having the power of analytics to find the right signal is extremely valuable in understanding patterns and incorporating learnings to ensure the same failure mode does not occur again.

The Splunk platform removes the barriers between data and action, empowering observability, IT and security teams to ensure their organizations are secure, resilient and innovative.
Founded in 2003, Splunk is a global company — with over 7,500 employees, Splunkers have received over 1,020 patents to date and availability in 21 regions around the world — and offers an open, extensible data platform that supports shared data across any environment so that all teams in an organization can get end-to-end visibility, with context, for every interaction and business process. Build a strong data foundation with Splunk.

Get the latest articles from Splunk straight to your inbox.
© 2005 - 2024 Splunk Inc. All rights reserved.
