
Digital Resilience Pays Off
Download this e-book to learn about the role of Digital Resilience across enterprises.

This is the second in a series of blogs on monitoring Docker containers. In the first post, I discussed what’s important to monitoring Dockerized environments, how to collect container metrics you care about, and your options for collecting application metrics.
In this post, I’ll discuss how SignalFx monitors its containerized environment, the tools used to orchestrate across our various environments, and how we get visibility across all layers of the stack, from cloud infrastructure up to services.
SignalFx has been running Docker containers in production since 2013. Every single application we manage executes within a Docker container. Along the way, we’ve learned how to monitor our Docker-based infrastructure and how to get maximum visibility into our applications, wherever and however they run.
SignalFx began using and deploying containers as Docker was emerging in 2013. Despite a strong community, the Docker ecosystem was just burgeoning at the time. Early adopters struggled to understand how this new container technology would change the way applications were managed and orchestrated in production.
At the time, orchestration tools like Mesos + Marathon, Kubernetes, Docker Compose, and Docker Swarm hadn’t been released or even invented yet. This meant manual, repetitive tasks on a regular basis and the inability to efficiently scale operations.
To solve our container orchestration needs, we wrote MaestroNG. MaestroNG is a Python tool that allows users to describe infrastructure of services, decide which Docker image to use, determine how to execute and configure containers, and, most importantly, where to run each individual container. With this orchestration tool, the deployment of Docker containers and control of complex, multi-host environments is easy and accessible for all our engineers.
From this static configuration of containers and common service definitions, MaestroNG allows us to orchestrate, manage, and control various environments. Not only can we execute the same Docker images, but we can also configure and control those containers in the same way with the same tool, regardless of whether there is a handful of containers on a local Vagrant VM or hundreds of containers across production hosts.
The rapid adoption of Docker in the last few years has enabled the container ecosystem of tools to grow and expand. Similar concepts and features of MaestroNG can, for example, be found today in Docker Compose.
Join us for a free webinar on Operationalizing Docker with monitoring »
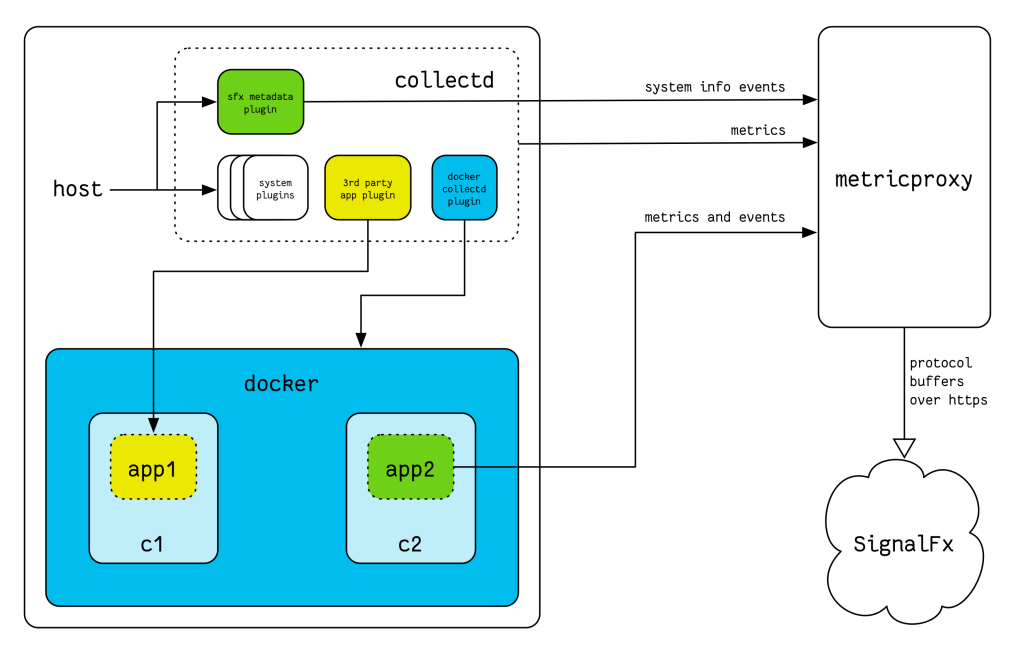
Every application at SignalFx runs inside a Docker container. The hosts that these containers execute on all belong to a specific service or role. Salt, our configuration management system, sets up and configures collectd on each of these hosts.
We use collectd the same ways as we recommend our customers to use collectd—with the SignalFx collectd package, the SignalFx collectd metadata plugin, and the Docker collectd plugin. The SignalFx collectd package provides the base set of plugins for host-level metrics, the SignalFx collectd metadata plugin reports additional metadata about the host, and the Docker collectd plugin reports metrics from the containers that run on each host.
Salt also configures additional plugins depending on the service, such as:
Because the application container runs on the same host, we simply configure those plugins to point to localhost.
With this setup, we get complete visibility across all the layers of our infrastructure—from every AWS instance that we have to every application instance that we run. collectd provides system-level and container-specific metrics. All our first-party applications directly emit metrics into SignalFx. For third-party applications, application metrics are provided via the corresponding plugin.
All metrics emitted by our applications and by collectd are sent to a load-balanced set of metricproxy instances. The metricproxy then forwards this data to an instance of the SignalFx stack specifically dedicated to monitoring SignalFx.
With all this data from our systems and applications going into SignalFx, our streaming analytics gives us immediate, real-time visibility into our infrastructure. We can see overall performance of all our services and applications, dive into specific availability zones or plugin, and double-click on individual hosts or containers for a detailed look.
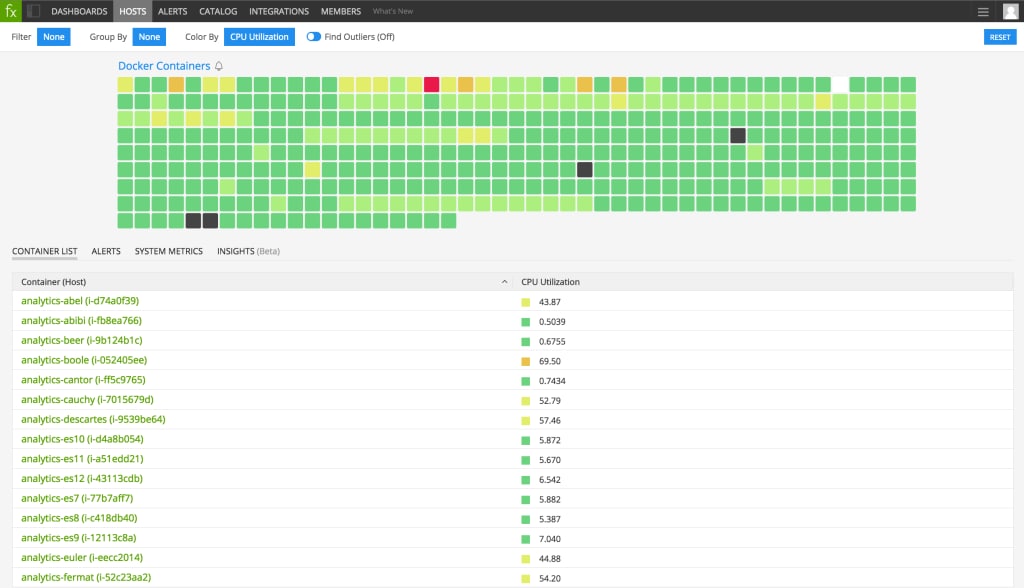
The snapshot of the state of our infrastructure on Host & Container Navigator gives instant visibility into the status of all our Docker containers. This heatmap provides a real-time and continuous survey of container status across our environment.
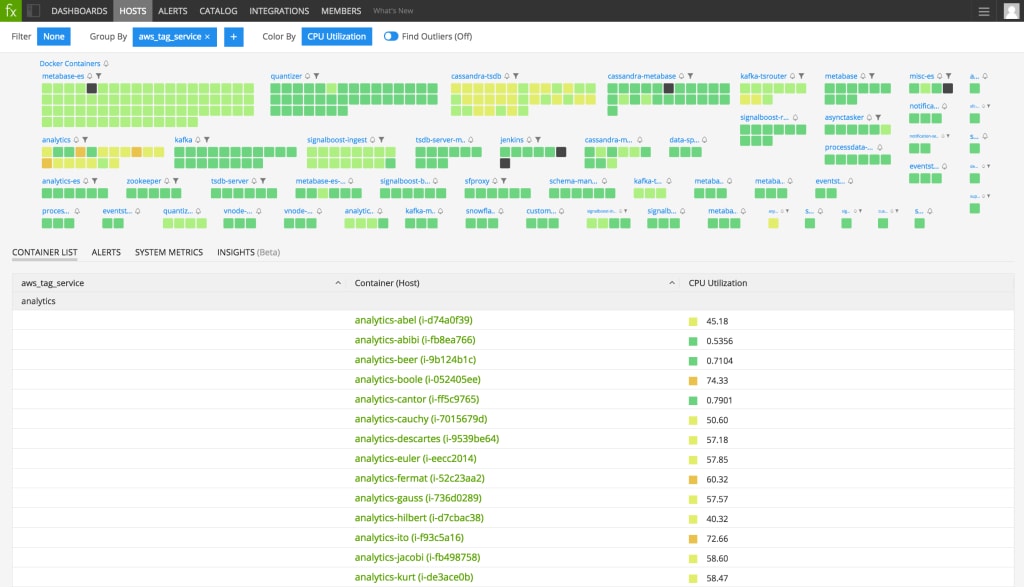
From the Host & Container Navigator view, we can drill into different perspectives of our environment by specific availability zone or microservice, for example. This gives us a starting point to quickly determine where our attention may be required.
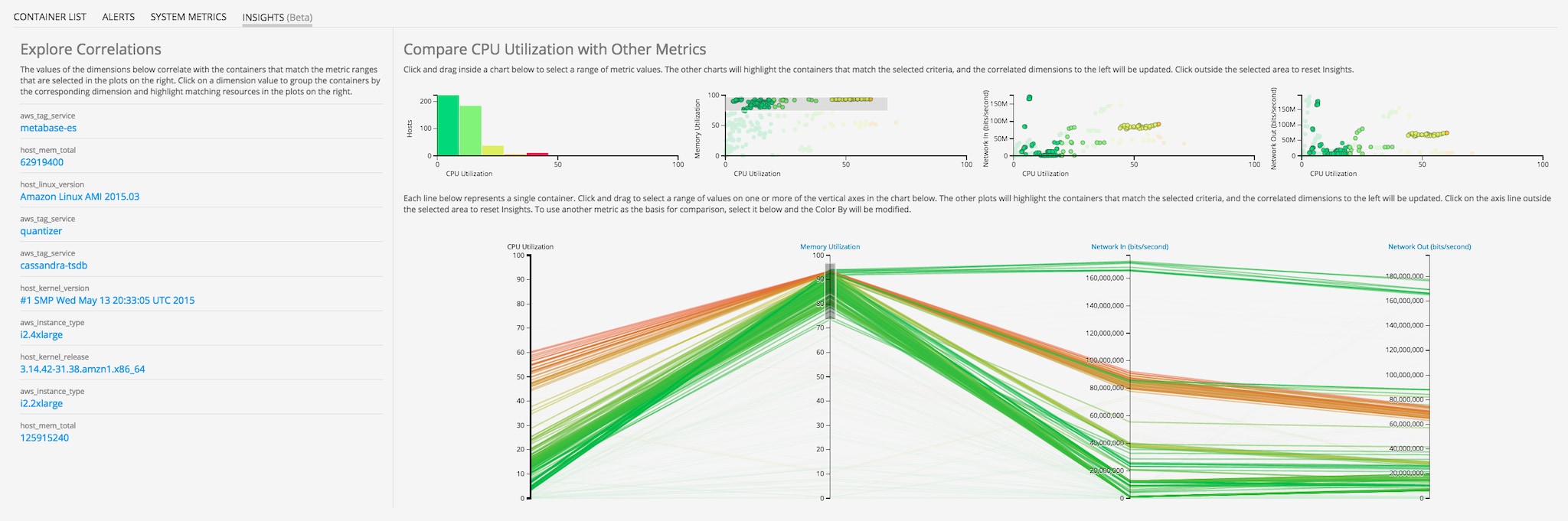
Finally, the recent release of the SignalFx Insights feature allows us to explore correlations between metrics and dimensions of all the system- and application-level data flowing out of our system. We can hone in on one infrastructure metric, such as high memory utilization, and see whether there are more common dimensions related to that group of select containers.
As I discussed in my previous blog, monitoring the applications that you run inside your Docker containers is where it gets more complex and where the confusion around monitoring Docker comes from. Monitoring the metrics coming from the applications running inside your containers typically paints a more relevant picture of the health of your application, more so than simple container metrics. These application metrics are the primary and clearest source of information.
However, it is often useful to also monitor a handful of system-level metrics. Especially when you pack multiple containers onto the same host, having those system-level metrics by each container becomes important. Having container metrics reported by the docker-collectd-plugin helps you setup meaningful alerting and anomaly detectors to complement your application-level anomaly detection.
From our experience, CPU and network utilization are key indicators that something is amiss in a container. We keep an eye on these metrics as they approach 100%. By using alerts to identify problematic containers and applications, we can proactively take action on these issues before an application fails. Memory utilization is also an interesting indicator, of course. However, when running VM-based applications, and Java in particular, heap usage is a much better metric to monitor compared to system memory usage.
For more insight on how to set up efficient and noise-free detectors for all metrics across an entire population of containers, I highly recommend the blog series Reducing Alert Noise by my colleague Joe Ross.
We are extremely happy with our early adoption of Docker as a key technology in our deployment infrastructure and orchestration systems. Along the way, we continue to contribute bug fixes and feedback to the Docker project and engage with the broader community. We’re even showing demos of some of the features I described here at DockerCon today, so please drop by the SignalFx booth!
In this post, I’ve shared how we at SignalFx capture container and application metrics that run inside Docker containers and how we use that data to monitor application performance and alert on anomalies. Every infrastructure and each use case is unique, and you may find yourself in a different scenario depending on your technology decisions.
To learn more, our webinar with Zenefits on operationalizing Docker and orchestrating microservices. We shared lessons from running Docker at scale during the past three years, including what metrics matter for monitoring, how to assign data dimensions for troubleshooting, and strategies for alerting on microservices running in Docker containers. Watch now!

The Splunk platform removes the barriers between data and action, empowering observability, IT and security teams to ensure their organizations are secure, resilient and innovative.
Founded in 2003, Splunk is a global company — with over 7,500 employees, Splunkers have received over 1,020 patents to date and availability in 21 regions around the world — and offers an open, extensible data platform that supports shared data across any environment so that all teams in an organization can get end-to-end visibility, with context, for every interaction and business process. Build a strong data foundation with Splunk.

Get the latest articles from Splunk straight to your inbox.
© 2005 - 2024 Splunk Inc. All rights reserved.
