
Digital Resilience Pays Off
Download this e-book to learn about the role of Digital Resilience across enterprises.
Splunk is committed to using inclusive and unbiased language. This blog post might contain terminology that we no longer use. For more information on our updated terminology and our stance on biased language, please visit our blog post. We appreciate your understanding as we work towards making our community more inclusive for everyone.
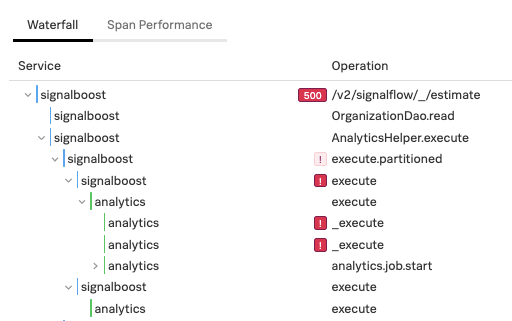
The promise of NoSample™ full-fidelity distributed tracing with unlimited cardinality exploration is that no application performance degradation will be sampled away. This ensures that executions, which exemplify problems related to latency and/or errors will be retained for further inspection and analysis. Additional value can be extracted from trace data by determining when such investigations should occur, in other words, by identifying spikes and anomalies in endpoint latency or error rate. This is now possible with Splunk APM with the release of μAPM Alerts.

From Spike to Trace
In this post we will explain the inner workings of μAPM alerts, as well as some of the motivating statistical principles.

Plus:
Aside from the qualitative choice among the four dynamic thresholds, the sensitivity of the alert is influenced by the required discrepancy from the baseline, and the lengths of the time windows (durations appearing in the underlying program). The Sudden Change and Historical Anomaly alerts are qualitatively similar to the Infrastructure built-in alerts with the same names, but the implementation is somewhat different. See the next section for details.
For both latency and error rate, μAPM static threshold detectors allow for comparisons to distinct trigger and clear thresholds (and durations), to eliminate possibly flappy alerts. By contrast, clear conditions for Infrastructure static threshold detectors are supported via SignalFlow API, but are not yet supported in the Splunk UI. Motivation for clear conditions and a recipe for constructing them in the Plot Builder (no longer necessary since SignalFlow detect blocks accept an “off” condition) can be found here, the basic point being that when a signal hovers around the threshold value, a separate clear condition allows this to be treated as a single incident rather than several.
Anomaly detection typically involves comparing distributions (e.g., the values of the last 5 minutes against the values of the preceding hour). When histograms are available, this can be accomplished by quantile comparison, or by using robust measures of center and spread, often the median and interquartile range (the difference between the 75th and 25th percentiles, often written IQR).
For Sudden Change and Historical Anomaly latency alerts, our definition of “deviations from the norm” is non-standard (and differs from that used in the Infrastructure built-in conditions) and deserves some discussion. A “deviation” in this context is the difference between the 90th and 50th percentiles, and is adapted to the characteristics of latency distributions.
For concreteness, we describe the distribution for executions of a typical well-trafficked endpoint, over a period of several hours. The IQR is 62 ms, but it is asymmetrically situated around the median: the 75th percentile is 68ms, while the 25th percentile is 6ms. Furthermore, the 90th percentile for this endpoint is about 2 IQR’s above the median; for the normal distribution, by contrast, the 90th percentile is less than 1 IQR above the median. The 99th percentile for this endpoint is about 29 IQR’s above the median; for the normal distribution, the 99th percentile is less than 2 IQR’s above the median.
The phenomenon of positive skew is fairly typical in latency distributions: the bulk of the distribution consists of relatively quick and uneventful executions. The lower percentiles are thus clumped together, whereas the higher percentiles are much more spread out. The skew motivates us to express the dispersion of the distribution with an emphasis on the data in the right tail, rather than with a statistic which is symmetric about the median.
Note also that the current P50 is larger than the historical P90 exactly when the current P50 is more than one historical (P90 - P50) above the historical P50. Thus alerting on the number of (P90 - P50)’s away from the P50 is a natural generalization of comparing the current P50 to the historical P90 (quantile comparison method of change detection).
Analysis of percentiles provides an important but incomplete picture of the health of an endpoint, and alerts based purely on the calculations described so far can be somewhat noisy. To this end, μAPM detectors make use of SignalFlow support for compound alert conditions (configuring an alert to trigger on a condition of the form “A and B,” for example) and make it possible to easily incorporate also the volume of traffic an endpoint receives in determining when an alert should trigger. As a consequence, alerts for sparse data can be suppressed.
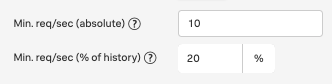
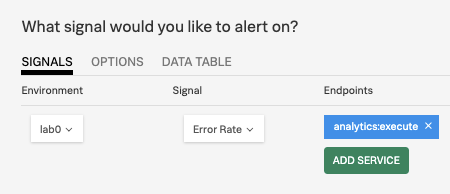
A request volume condition for error rate detectors is also exposed. This can be used to ensure, for example, that an endpoint that receives just a few requests, one of which is an error, does not trigger an alert.
The alerting patterns are applicable to other scenarios (the approach to latency may be applied more generally when distribution and count data are available, and the approach to error rate may be applied to other rates), but they are substantially more specialized than the strategies that power the Infrastructure built-in alerts.
The apm module of the SignalFlow Library lies underneath the μAPM alert conditions. As with other SignalFlow modules, apm contains some intermediate calculations which may provide useful visualizations or ingredients for other alerting schemes (e.g., combining built-in conditions with custom thresholds). For example, the error_rate function calculates the error rate for a specified set of operations over a specified duration.
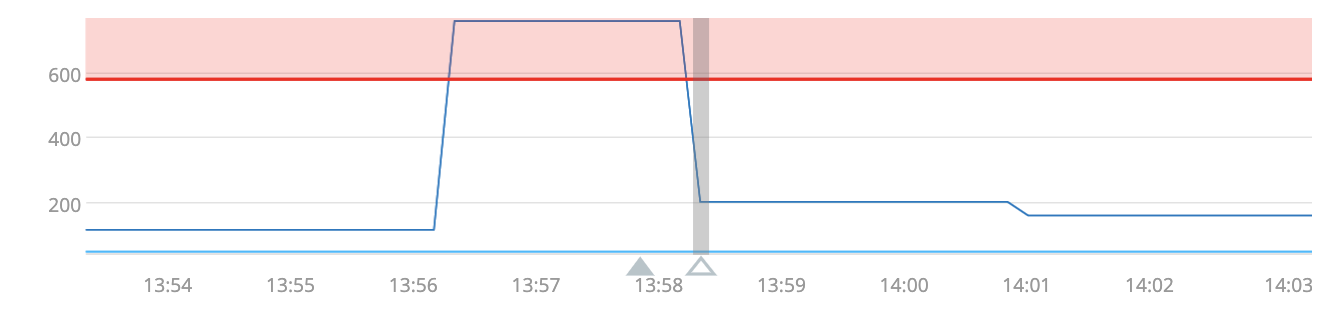
For μAPM detectors, we have implemented some enhancements to the data visualized in the incident modal. Here is an example.
The current latency, which increases just after 13:56, is shown in dark blue, the historical baseline (in this case, the historical median) is shown in light blue, and the threshold (here, the historical median plus five historical deviations) is shown in red. As usual, the filled triangle marks the beginning of the incident, and the open triangle marks its end. The depiction of the historical baseline is new (compared to the Infrastructure built-in conditions, which are based on qualitatively similar statistical methodology) and provides additional context to facilitate rapid evaluation of an alert.
Using Splunk's real-time streaming analytics engine and NoSample™ full-fidelity distributed tracing as a foundation, Splunk APM alerts allow for rapid problem detection and discovery of relevant execution traces.

The Splunk platform removes the barriers between data and action, empowering observability, IT and security teams to ensure their organizations are secure, resilient and innovative.
Founded in 2003, Splunk is a global company — with over 7,500 employees, Splunkers have received over 1,020 patents to date and availability in 21 regions around the world — and offers an open, extensible data platform that supports shared data across any environment so that all teams in an organization can get end-to-end visibility, with context, for every interaction and business process. Build a strong data foundation with Splunk.

Get the latest articles from Splunk straight to your inbox.
© 2005 - 2024 Splunk Inc. All rights reserved.
