
Digital Resilience Pays Off
Download this e-book to learn about the role of Digital Resilience across enterprises.
I have written a lot about customer experience (CX) recently, as it has become a growing area in which Splunk’s own customers are looking for support. Reflecting this increased interest, a number of the presentations at the Splunk annual user conference, taking place later this month, will be focussed on improving customer experience. Sessions of particular interest will be:
We will be showcasing the latest iteration of our CX demo at the event, but in the meantime, you can learn more about the demo in my blog ‘Linking operational data with customer feedback to drive improved customer experience’. Its new feature is the ability to bring data from Enterprise Feedback Management (EFM) platforms into Splunk. We have built an EFM integration with the Maritz CX platform, which we will be demonstrating for the first time at .conf2017.
From a technical perspective, we have done this by setting up a TA using Maritz CX’s API to bring survey data into Splunk. Via this, we can ingest data from any survey, including both open and closed responses. Our demo now includes dummy data created by Maritz CX for a fictional airline, an extract from which is shown below.
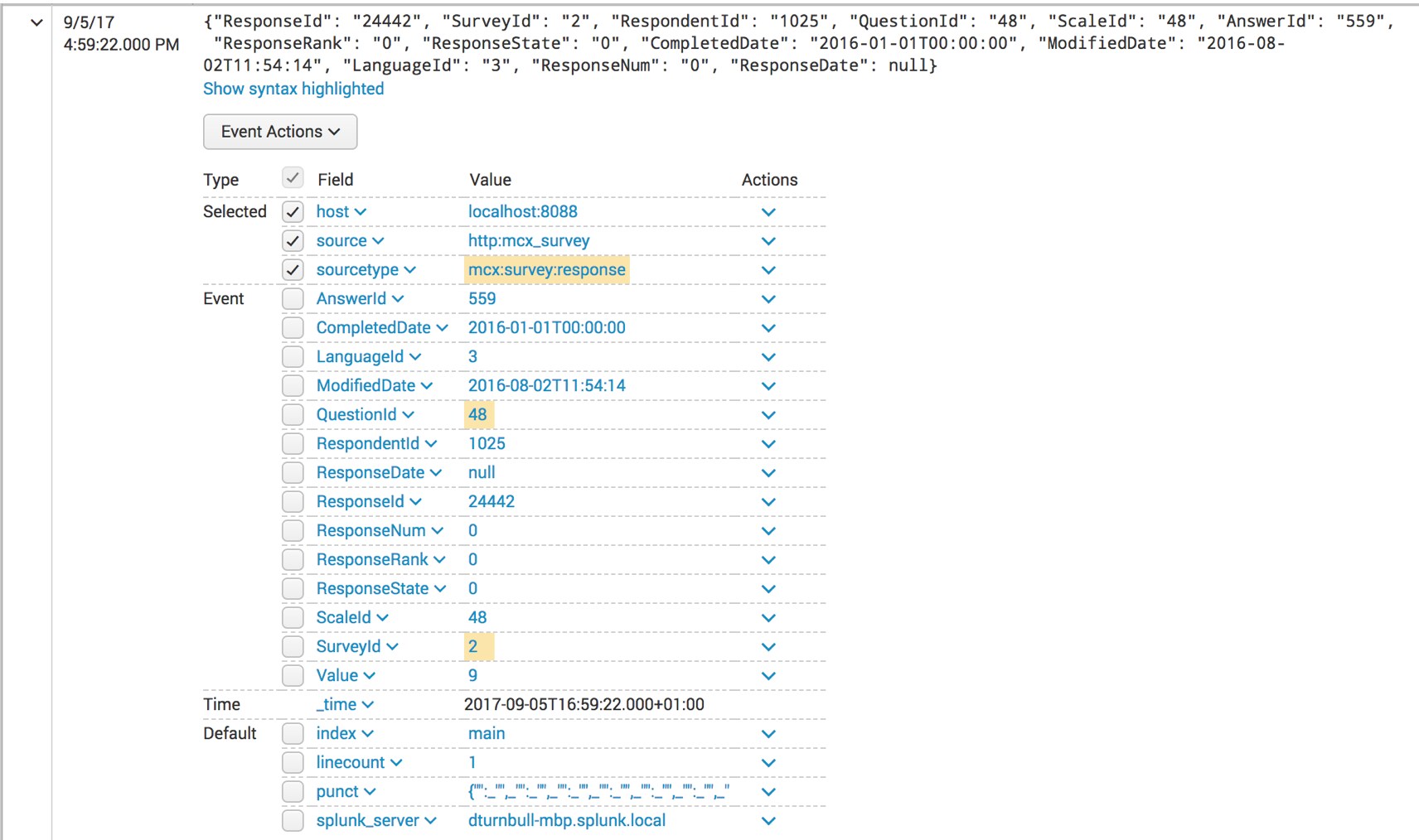
Those familiar with customer feedback will recognize the structure of this data, although the format in which it is presented here will be slightly different than you are used to. It still includes:
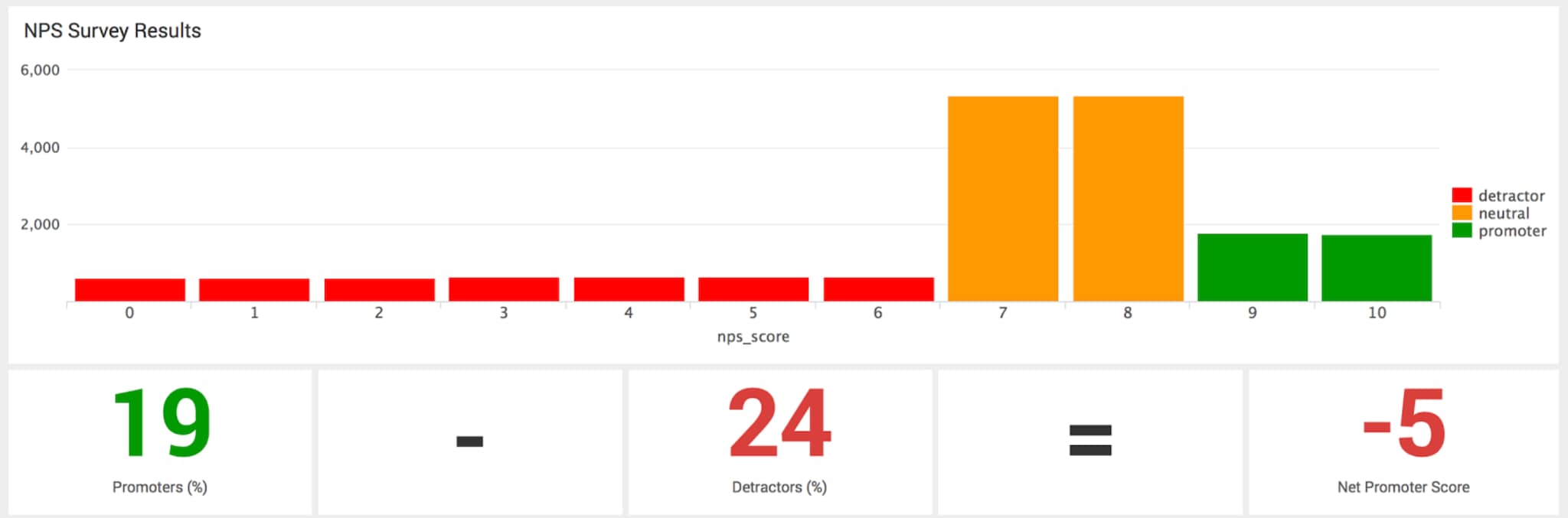
In this example, Splunk has indexed JSON data, which is our equivalent of storing data into rows and columns in a structured database. Although this data format may be slightly different to traditional market research, the analytics generated will be familiar. As an example, here is a dashboard showing survey NPS taken from our demo.
The key benefits of being able to import EFM data into Splunk are:
This has significant implications for the any company looking to identify CX improvements. Specifically, it will enable these companies to:
I think that the ability to analyse operational performance alongside customer feedback will allow our customers to make big strides in improving their customer experience. This will translate into a competitive advantage for those who can harness their data, the most effectively.

The Splunk platform removes the barriers between data and action, empowering observability, IT and security teams to ensure their organizations are secure, resilient and innovative.
Founded in 2003, Splunk is a global company — with over 7,500 employees, Splunkers have received over 1,020 patents to date and availability in 21 regions around the world — and offers an open, extensible data platform that supports shared data across any environment so that all teams in an organization can get end-to-end visibility, with context, for every interaction and business process. Build a strong data foundation with Splunk.

Get the latest articles from Splunk straight to your inbox.
© 2005 - 2024 Splunk Inc. All rights reserved.
