
Digital Resilience Pays Off
Download this e-book to learn about the role of Digital Resilience across enterprises.

In the previous blog post in this SmartStore series, "Splunk SmartStore: Disrupting Existing Large Scale Data Management Paradigms," we focused on how the ever-growing data volumes render the prevalent model of distributed scale out ineffective. Storage demand outpacing the compute demand renders the current deployment model unsustainable for large data volumes. Existing large-scale data management models fall short and a new disruptive model is needed that is both cost-efficient and performant at scale.
Splunk SmartStore is the latest evolution of the distributed scale out model that provides a data management model which brings in data closer to the compute on-demand, provides a high degree of compute/storage elasticity and makes it incredibly cost efficient to achieve longer data retention at scale. SmartStore dynamically places data either in local storage or in remote storage or in both, depending on access patterns, data age and data/index priority. SmartStore uses AWS S3 API to plug into the remote storage tier. Remote storage options are AWS S3 and S3 API compliant object stores, including Dell/EMC ECS, NetApp StorageGrid, Pure Storage Flash Blade and SwiftStack.
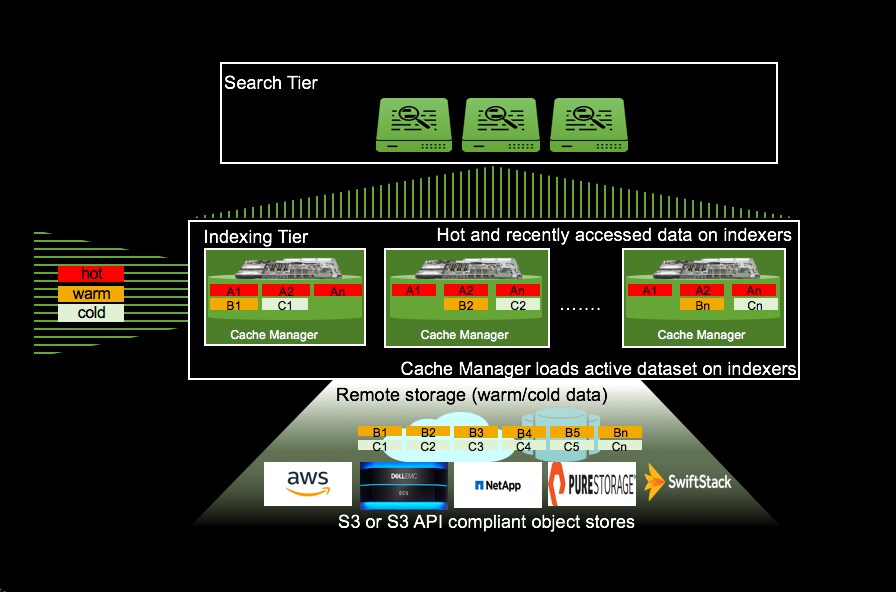
By bringing data closer to compute on-demand based on access patterns, data age and priority, Splunk SmartStore provides a seamless search experience. The dynamic placement of data is driven by an application aware cache that automatically evaluates data age, priority and users’ data access patterns to determine which data needs to remain accessible for real-time analytics and which data can be moved to remote storage (using S3 API). The application aware cache optimizes data placement on local storage in combination with user configurable data priority. Data corresponding to selective indexes can be retained in the cache longer than non-critical indexes.
SmartStore effectively reduces the storage requirements for aged data (warm/cold). By placing a single full copy on the local indexer (along with RF-1 metadata copies) and relying on the intrinsic HA capabilities provided by the remote storage, it effectively reduces the storage requirement for aged data. This allows growing volumes of data to be retained at lower cost economies while keeping the data searchable. By keeping the data searchable and allowing for longer retention at lower cost, SmartStore also obviates the need to freeze the data unless required to meet much longer (>1 year) security and compliance requirements.
This change in the deployment model effectively renders the indexers stateless for warm and cold data, making the indexer highly elastic and simplifying the management of the Splunk deployment. Node failures only mandate metadata replication to meet RF and SF which is extremely faster than full data replication. Indexer recovery and data rebalance are now metadata only replication operations accelerating the time to recover from hardware failures or data imbalance.
By decoupling compute and storage, Splunk SmartStore also provides a high degree of elasticity. As more data is ingested and retained, SmartStore storage can be scaled independently. As search volume increases or more users are added to the deployment, performance can be scaled by adding in more compute. The entire set of indexers in the cluster can also be shutdown/replaced and later revived by bootstrapping the data from the remote storage, providing a high degree of flexibility and control to manage infrastructure costs.
Splunk SmartStore is ushering in a new wave of innovation in data management by decoupling compute and storage and bringing in data closer to compute on demand. It lays the foundation for the Splunk machine data platform to deliver business outcomes both through value addition at the top with accelerated insights, and improving the bottom line by making it cost effective to retain data long enough to unravel those insights.
----------------------------------------------------
Thanks!
Bharath Aleti

The Splunk platform removes the barriers between data and action, empowering observability, IT and security teams to ensure their organizations are secure, resilient and innovative.
Founded in 2003, Splunk is a global company — with over 7,500 employees, Splunkers have received over 1,020 patents to date and availability in 21 regions around the world — and offers an open, extensible data platform that supports shared data across any environment so that all teams in an organization can get end-to-end visibility, with context, for every interaction and business process. Build a strong data foundation with Splunk.

Get the latest articles from Splunk straight to your inbox.
© 2005 - 2024 Splunk Inc. All rights reserved.
