
Splunk ITSI for AIOps
Discover our industry-leading approach to AIOps & monitoring.
This document describes the steps to ingest Nagios Core 4.x alarms into Splunk IT Service Intelligence (ITSI) Notable Events Review. There are two different onboarding scenarios based on the scope of the Nagios deployment.
Option 1: Nagios is being used for alert management (very common).
Option 2: Nagios is also pulling in performance data from the various hosts (not a common Nagios deployment approach).
---------------------------------------------------------------------------------------------------------------------------------------------
Configuration time: 30 minutes
Requirements: Universal forwarder on the Nagios server
1. Install a universal forwarder on the Nagios server.
2. Ensure that your Splunk server is configured for receiving data.
3. Configure your Splunk forwarder. Run the following CLI command:
./splunk add forward-server <splunk server>:<forwarding port>
4. Forward Nagios alerts into Splunk. Run the following CLI command:
./splunk add monitor /usr/local/nagios/var/nagios.log
For more information, see How to forward data to Splunk Enterprise.
5. Import the Nagios correlation search and aggregation policy into Splunk.
a. Download the backup zip file (nagiospackage.zip).
b. Restore the aggregation policy and the Nagios correlation search on the ITSI server via the kvstore_to_json.py command line utility.
6. Test the correlation search and aggregation policy.
a. Create several “node down” alerts in Nagios (shut down the host or select failed check from the Nagios UI).
b. Open the Notable Events Review in ITSI and click the “node down” event group.
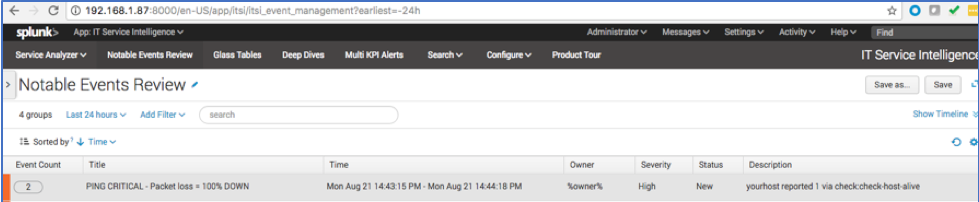
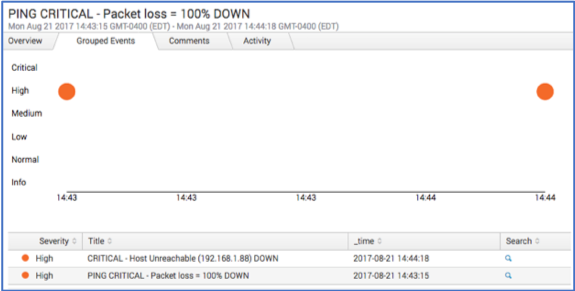
c. Go to the Grouped Events tab and ensure that all "node down" alerts are grouped by host.
---------------------------------------------------------------------------------------------------------------------------------------------
Configuration time: 90 minutes
Requirements: Splunk Add-on for Nagios Core
Note: Only use this option if you have performance data (CPU, memory, SNMP metrics, etc.) collected in Nagios. Performance data is not active by default and requires you to restart the Nagios environment. However, it does provide good metrics and field extractions that you can leverage directly in ITSI.
Here’s an example of Nagios performance data:
1. Install a universal forwarder on the Nagios server.
2. Ensure that your Splunk server is configured for receiving data.
3. Install the Splunk Add-on for Nagios Core on the universal forwarder and the search head.
4. Configure your Nagios Core instance for the Splunk Add-on for Nagios Core.
Note: You do not need to configure Splunk DB Connect. All Nagios performance data for ITSI is kept in text files that are configured as part of these setup steps.
5. (Optional) Build KPIs for metric data. All Nagios performance data is sourcetyped as sourcetype=nagios:core:serviceperf or sourcetype=nagios:core:hostperf.
Note: The metrics you can use depend on the Nagios checks. For example, if the “check_load” utility is reporting back to Nagios, you can build CPU utilization KPIs. The typical check time is between 5 and 10 minutes, so data availability must be considered.
6. Import the Nagios correlation search and aggregation policy into Splunk.
a. Download the backup zip file (nagiospackage.zip).
b. Restore the aggregation policy and the Nagios correlation search on the ITSI server via the kvstore_to_json.py command line utility.
7. Change the Nagios AlertLog correlation search:
From: index=* sourcetype="nagios:core" Alert|rex field=_raw….
To: index=* sourcetype="nagios:core" STATE|rex field=_raw…
8. Test the correlation search and the aggregation policy.
a. Create several “node down” alerts in Nagios (shut down the host or select failed check from the Nagios UI).
b. Open the Notable Events Review in ITSI and click the “node down” event group.
c. Go to the Grouped Events tab and ensure that all “node down” alerts are grouped by host.
For questions or issues, contact Martin Wiser at mwiser@splunk.com.
----------------------------------------------------
Thanks!
Liz Snyder

The world’s leading organizations rely on Splunk, a Cisco company, to continuously strengthen digital resilience with our unified security and observability platform, powered by industry-leading AI.
Our customers trust Splunk’s award-winning security and observability solutions to secure and improve the reliability of their complex digital environments, at any scale.

Get the latest articles from Splunk straight to your inbox.
© 2005 - 2025 Splunk LLC All rights reserved.
