
Digital Resilience Pays Off
Download this e-book to learn about the role of Digital Resilience across enterprises.
There are many 3rd party web analytics providers such as Google Analytics and Omniture SiteCatalyst. However, with the flexibility of Splunk as general purpose analytics tool, many site owners opt to build their own client-side analytics powered by Splunk. Last month we talked about how jQuery Foundation had their conference website leverage Splunk to collect & analyze all client-side events.
Compared to off-the-shelf web analytics tools, building your own client-side analytics gives you significant advantages:
To learn more about the difference between server-side and client-side data, check out the first part of this previous blog post.
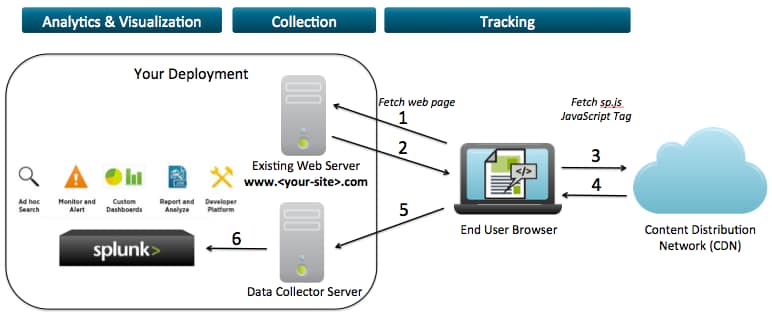
Going through the 3 blue stages from right to left in the above diagram, the first step, tracking, is achieved by pasting a JavaScript snippet to your page to load a small analytics library. To help you with that, we’re providing you with an easy-to-use analytics library sp.js that gives you:
Simply add this script tag before the closing </head> tag on your page. This will asynchronously fetch the JavaScript library sp.js from a global CDN without impacting the page load time:
<script type="text/javascript">
var sp=sp||[];(function(){var e=["init","identify","track","trackLink","pageview"],t=function(e){return function(){sp.push([e].concat(Array.prototype.slice.call(arguments,0)))}};for(var n=0;n<e.length;n++)sp[e[n]]=t(e[n])})(),sp.load=function(e,o){sp._endpoint=e;if(o){sp.init(o)};var t=document.createElement("script");t.type="text/javascript",t.async=!0,t.src=("https:"===document.location.protocol?"https://":"http://")+"d21ey8j28ejz92.cloudfront.net/analytics/v1/sp.min.js";var n=document.getElementsByTagName("script")[0];n.parentNode.insertBefore(t,n)};
sp.load("https://www.example.com"); // Replace with your own collector URL
</script>
In the last line of above script, make sure to replace https://www.example.com with the address of your data collector discussed in the following section.
To use sp.js, you must specify an endpoint where tracking calls get made to. Behind that endpoint, a single collection server (or distributed collection tier) can respond to these calls, and collect the tracked events into a log file, say events.log.
Again, to help you with this BYO project, we’re providing on github a sample code for a Node.js based backend collector server with instructions on how to run it.
Once deployed, copy the collector server address and use it in the last line of the script tag as mentioned above.
Finally, the file events.log can get be ingested into Splunk either by using a Splunk forwarder to send data to your existing Splunk deployment, or running a local Splunk instance that continuously monitors that file.
Once data in Splunk, the sky is the limit: set up Splunk monitoring & alerts, analyze with Splunk dashboards, or build your custom visualizations for traffic segmentation, A/B testing, funnel analysis, etc.
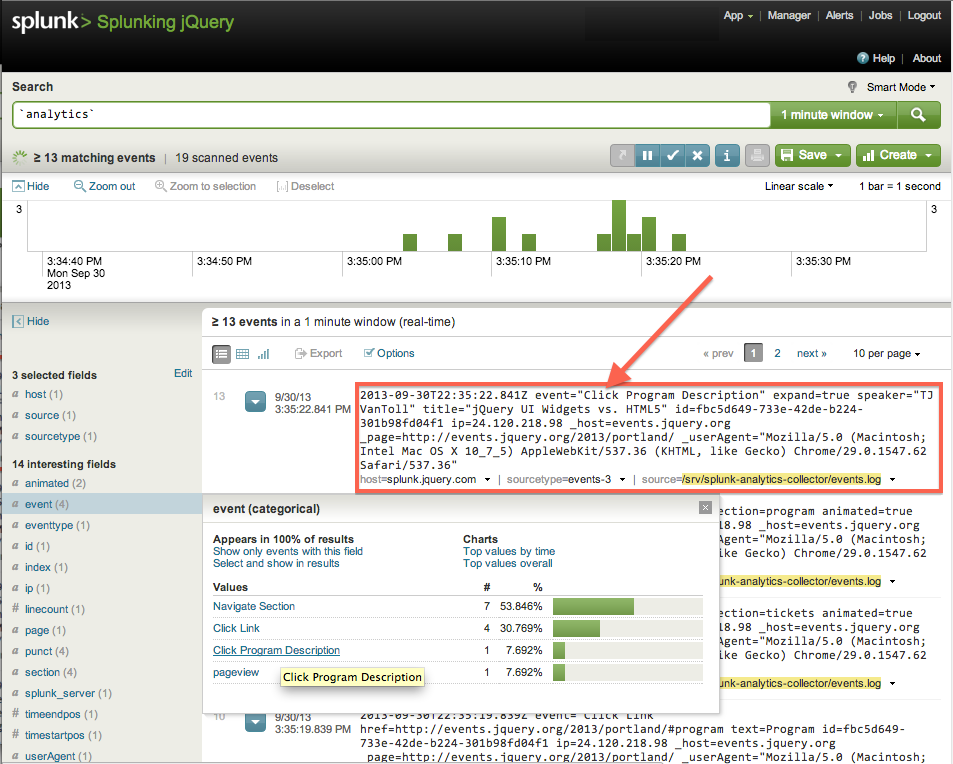
Consider the following website showing a program schedule that consists of sessions. In this particular case, a call was made by sp.js to track a user’s mouse click that’s expanding a session description. Note that, as with many client-side interactions, this mouse click cannot be tracked from web server logs as it doesn’t trigger a web server request.
![]()
Notice the tracked data consists of:
Finally, the following snapshot shows how this tracked event is monitored in real-time in Splunk as it gets collected and logged:
Publicly available sp.js JavaScript Library for Tracking:
https://github.com/splunk/splunk-demo-collector-for-analyticsjs#setup
Sample Node.js based Backend Server for Collection:
https://github.com/splunk/splunk-demo-collector-for-analyticsjs
----------------------------------------------------
Thanks!
Roy Arsan

The Splunk platform removes the barriers between data and action, empowering observability, IT and security teams to ensure their organizations are secure, resilient and innovative.
Founded in 2003, Splunk is a global company — with over 7,500 employees, Splunkers have received over 1,020 patents to date and availability in 21 regions around the world — and offers an open, extensible data platform that supports shared data across any environment so that all teams in an organization can get end-to-end visibility, with context, for every interaction and business process. Build a strong data foundation with Splunk.

Get the latest articles from Splunk straight to your inbox.
© 2005 - 2024 Splunk Inc. All rights reserved.

{kind=link}