
Digital Resilience Pays Off
Download this e-book to learn about the role of Digital Resilience across enterprises.
Starting with Linux Kernel 4.1, an interesting feature got merged: eBPF. For anyone playing with network, BPF should sound familiar: it is a filtering system available to user-space tools such as tcpdump or wireshark to filter and display only the wanted (filtered) packets. The e in eBPF means extended, to bring that out of just Network traffic and allowing to trace from the Kernel various things, syscall capture, kprobes, tracepoints etc.
eBPF will run a piece of C code compiled in bytecode which uses the Just-In-Time Compiler to the BPF interpreter. In short, eBPF uses the virtual machine which interprets code into the Linux Kernel. In the current git tree, BPF offers 89 instructions called from the bytecode buffer making the eBPF instructions.
It is an amazing tool for tracing, but in this post I would like to share how we can list TCP IPv4 connections and send them to Splunk using the HTTP Event Collector (HEC), all that kernel side!
$ git clone git://git.kernel.org/pub/scm/linux/kernel/git/torvalds/linux.git
$ sudo apt-get install kernel-package build-essential libncurses5-dev fakeroot
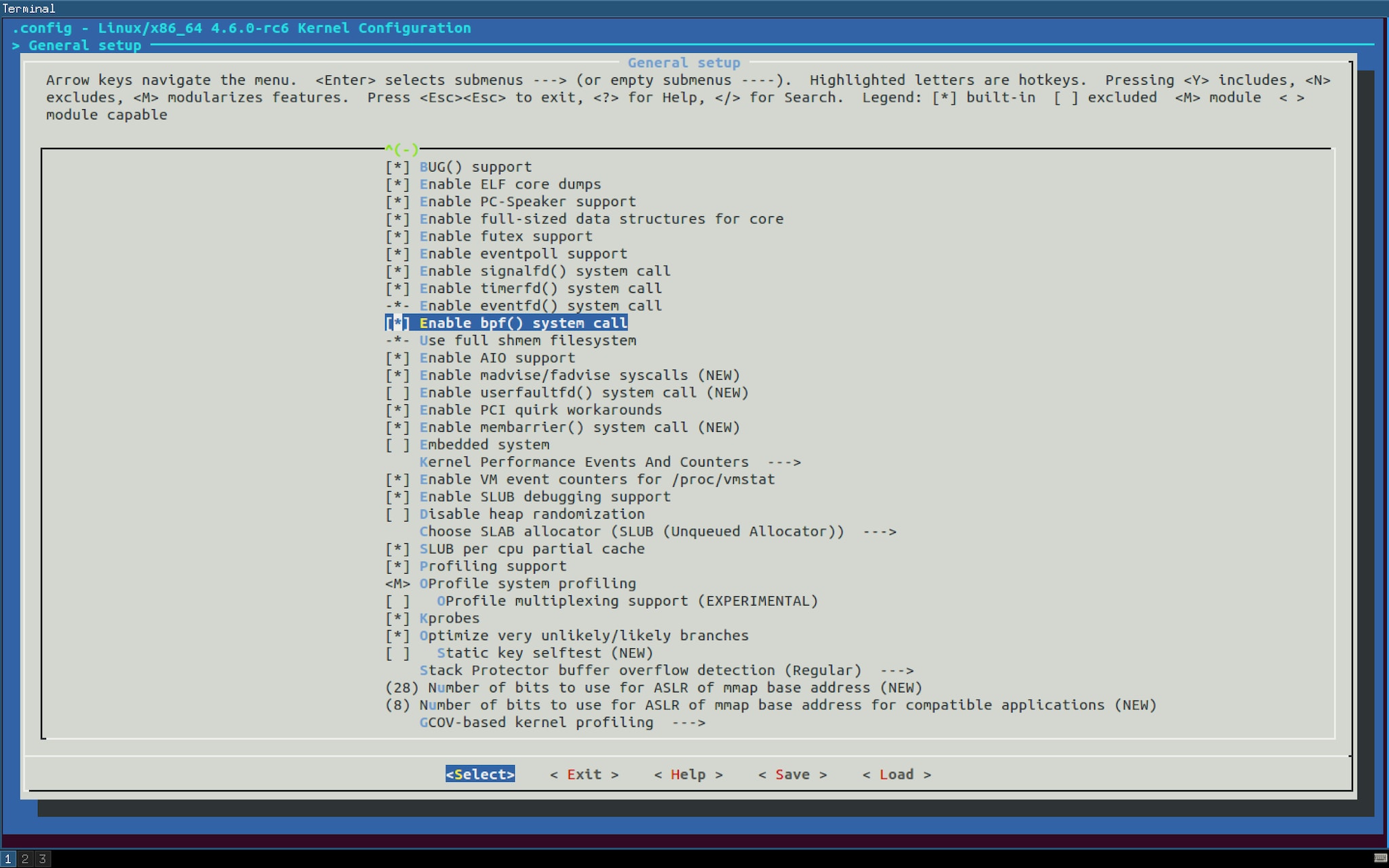
$ make ARCH=x86_64 menuconfig

$ grep BPF .config CONFIG_BPF=y CONFIG_BPF_SYSCALL=y CONFIG_NETFILTER_XT_MATCH_BPF=m CONFIG_NET_CLS_BPF=m # CONFIG_NET_ACT_BPF is not set CONFIG_BPF_JIT=y CONFIG_HAVE_BPF_JIT=y CONFIG_BPF_EVENTS=y CONFIG_TEST_BPF=m
$ make-kpkg --initrd --rootcmd fakeroot kernel_image exec make kpkg_version=12.036+nmu3 -f /usr/share/kernel-package/ruleset/minimal.mk debian ROOT_CMD=fakeroot ====== making target debian/stamp/conf/minimal_debian [new prereqs: ]====== ... dpkg —build ~/git/linux/debian/linux-image-4.6.0-rc6+ .. dpkg-deb: building package `linux-image-4.6.0-rc6+' in `../linux-image-4.6.0-rc6+_4.6.0-rc6+-10.00.Custom_amd64.deb'. make[1]: Leaving directory ‘~/git/linux'
$ sudo dpkg -i ../linux-image-4.6.0-rc6+_4.6.0-rc6+-10.00.Custom_amd64.deb
$ uname -a | grep 4.6.0-rc6 4.6.0-rc6 $ echo $? 0
$ git clone http://github.com/iovisor/bcc
$ sudo apt-get install iperf netperf
sudo python /usr/share/bcc/examples/hello_world.py tpvmlp-1636 [000] d... 2633.342396: : Hello, World! tpvmlp-1636 [000] d... 2648.547213: : Hello, World!
$ sudo python /usr/share/bcc/examples/tracing/trace_fields.py PID MESSAGE 1636 Hello, World! 1636 Hello, World! 3182 Hello, World! 3182 Hello, World! 1636 Hello, World!
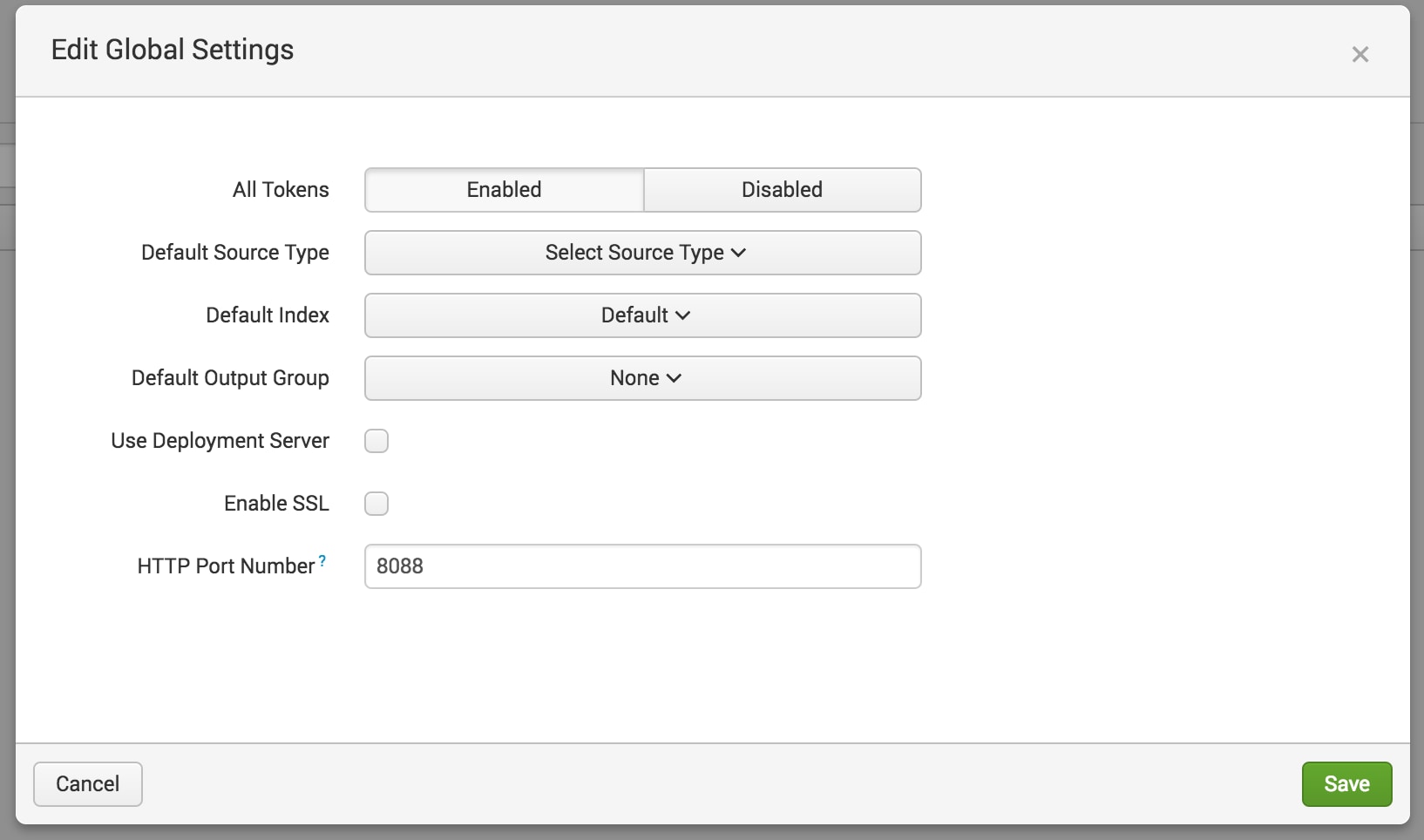
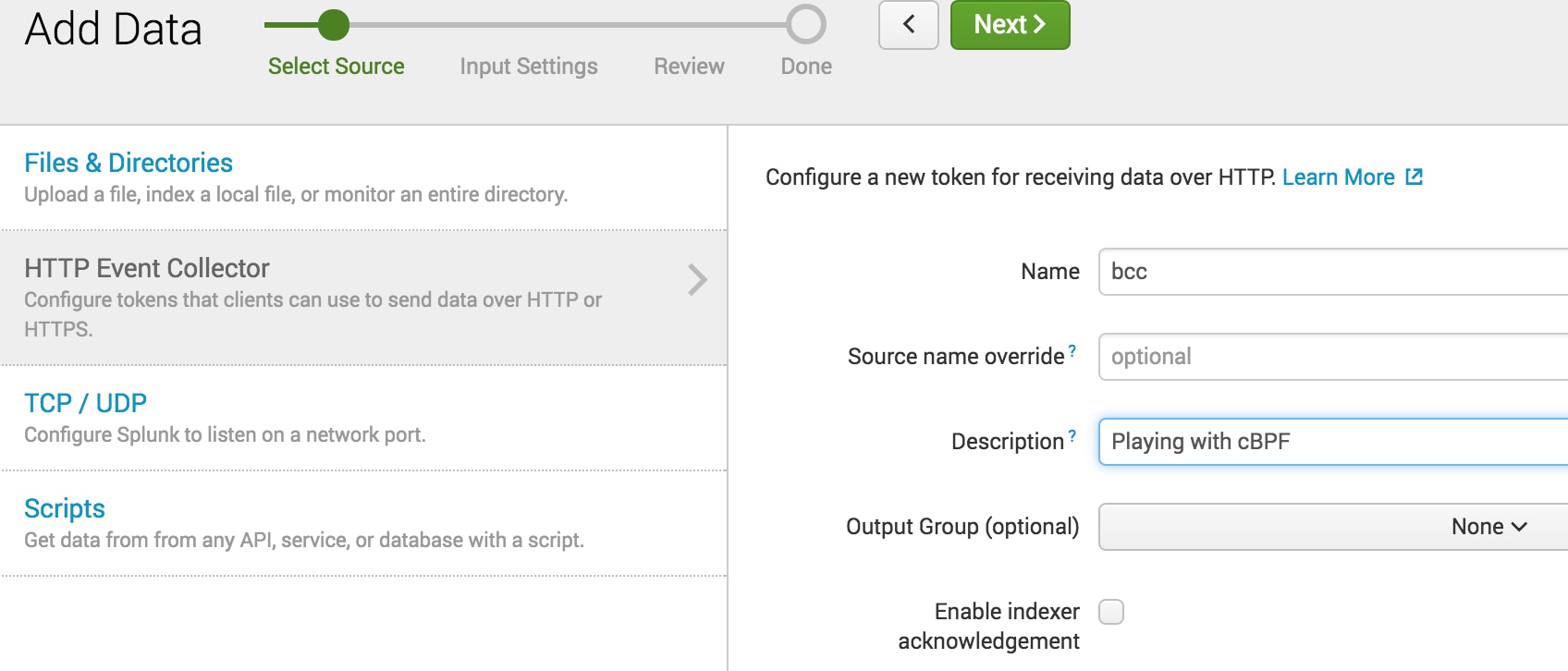
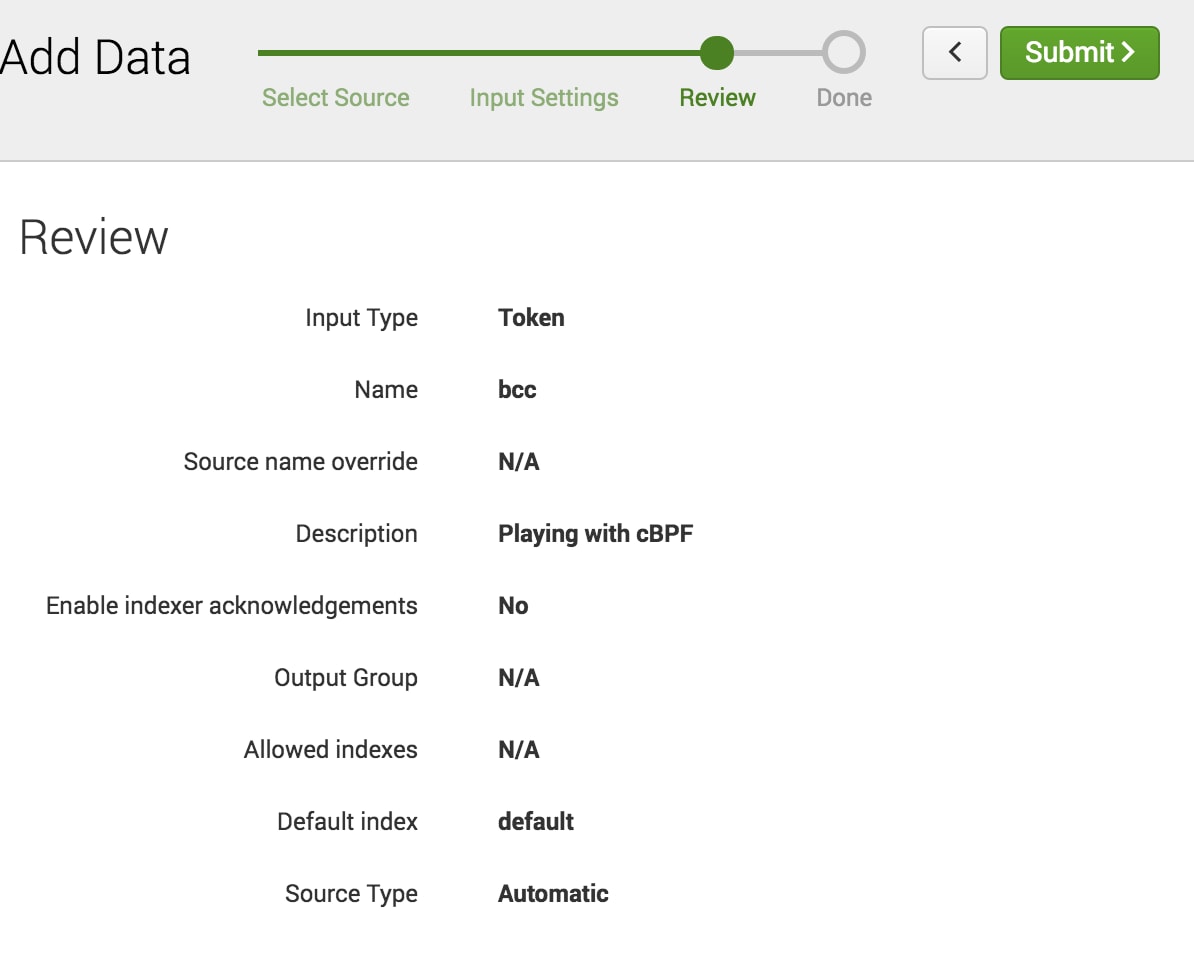
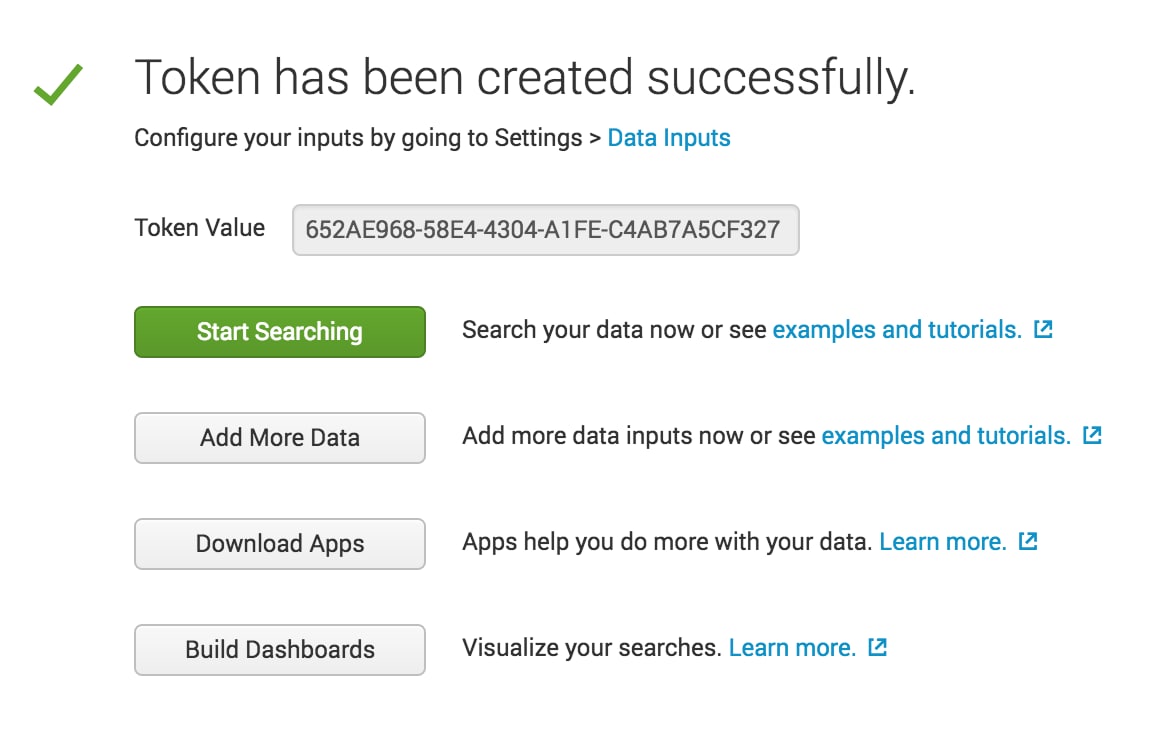
$ curl -k http://localhost:8088/services/collector/event -H "Authorization: Splunk 652AE968-58E4-4304-A1FE-C4AB7A5CF327" -d '{"event": "hello world"}'
{"text":"Success","code":0}
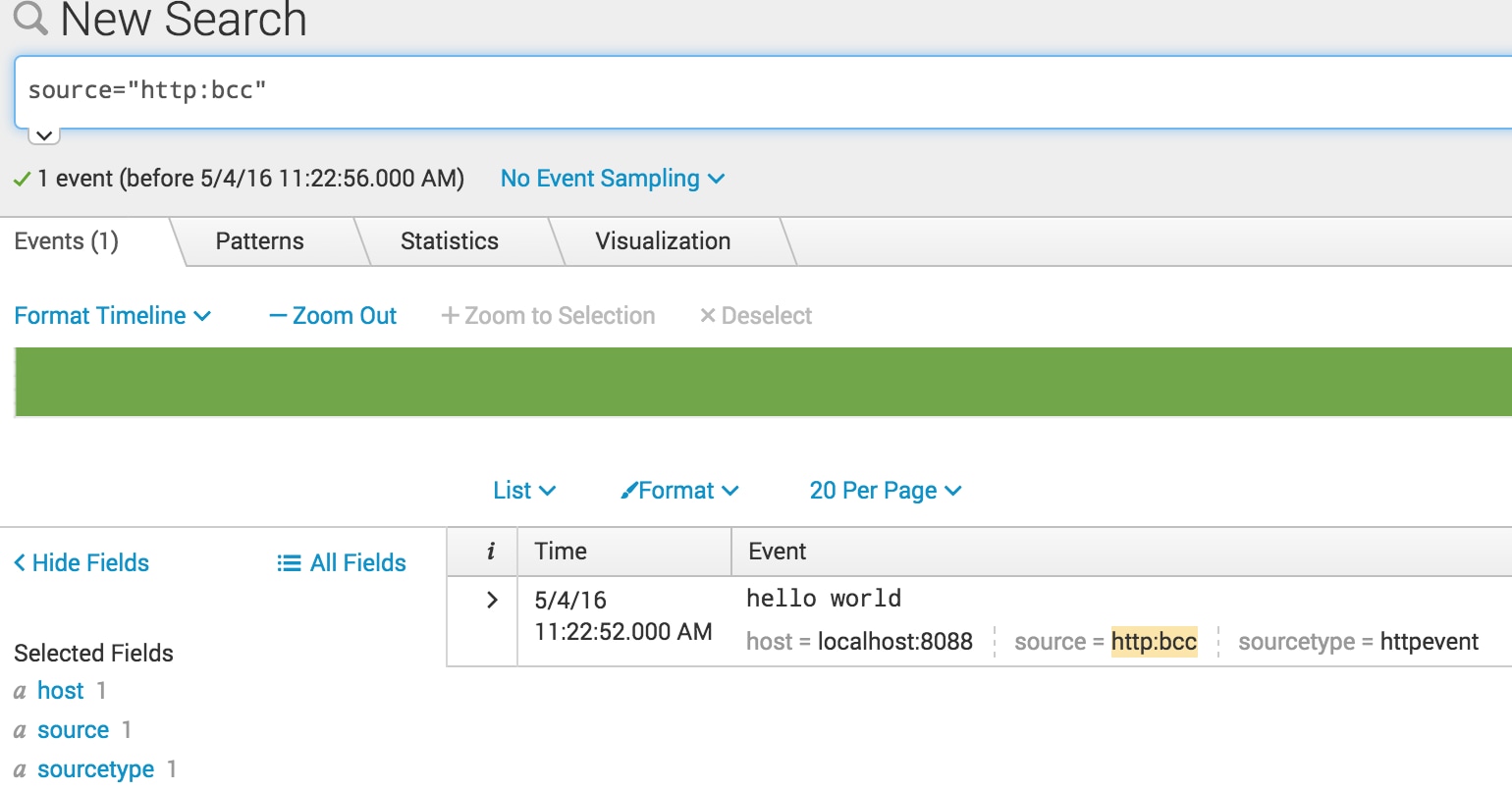
$ wget https://raw.githubusercontent.com/iovisor/bcc/master/examples/tracing/tcpv4connect.py
$ sudo python tcpv4connect.py PID COMM SADDR DADDR DPORT
$ wget google.com/index.html
$ sudo python tcpv4connect.py PID COMM SADDR DADDR DPORT 4367 wget 172.16.99.163 216.58.194.73 80 4367 wget 172.16.99.163 74.125.21.105 80
$ cp tcpv4connect.py tcp2splunk.py
from bcc import BPF import os import httplib import json # define BPF program
headers = {"Authorization": "Splunk 652AE968-58E4-4304-A1FE-C4AB7A5CF327", "Content-Type": "application/json"}
conn = httplib.HTTPConnection("172.16.99.1:8088")
# filter and format output
while 1:
# Ignore messages from other tracers
if _tag != "trace_tcp4connect":
continue
if os.getpid() != pid:
message = {"event": {"pid": pid, "task": task, "saddr": inet_ntoa(int(saddr_hs, 16)),
"daadr": inet_ntoa(int(daddr_hs, 16)), "dport": dport_s}}
conn.request("POST", "/services/collector/event", json.dumps(message), headers)
res = conn.getresponse()

----------------------------------------------------
Thanks!
Sebastien Tricaud

The Splunk platform removes the barriers between data and action, empowering observability, IT and security teams to ensure their organizations are secure, resilient and innovative.
Founded in 2003, Splunk is a global company — with over 7,500 employees, Splunkers have received over 1,020 patents to date and availability in 21 regions around the world — and offers an open, extensible data platform that supports shared data across any environment so that all teams in an organization can get end-to-end visibility, with context, for every interaction and business process. Build a strong data foundation with Splunk.

Get the latest articles from Splunk straight to your inbox.
© 2005 - 2024 Splunk Inc. All rights reserved.
