Search Command> stats, eventstats and streamstats
Tips & Tricks SplunkGetting started with stats, eventstats and streamstats
When I first joined Splunk, like many newbies I needed direction on where to start. Someone gave me some excellent advice:
“Learn the stats and eval commands.”
Putting eval aside for another blog post, let’s examine the stats command. It never ceases to amaze me how many Splunkers are stuck in the “super grep” stage. They just use Splunk to search (happily I might add) for keywords and phrases over many sources of machine data. Hopefully this will help advance some folks beyond “super grep” as well as assist those who may be new to Splunk.
When you dive into Splunk’s excellent documentation, you will find that the stats command has a couple of siblings — eventstats and streamstats. In this blog post, I will attempt, by means of a simple web log example, to illustrate how the variations on the stats command work, and how they are different. Stats typically gets a lot of use, but I’ll use it to set the stage for eventstats and streamstats which don’t get as much use. Reference documentation links are included at the end of the post. I will take a very basic, step-by-step approach by going through what is happening with the stats command, and then expand on that example to show how stats differs from eventstats and streamstats. In an effort to keep it simple, I’ll limit the data of interest to five (5) events with the head command. (If you’re cool with stats, scroll on down to eventstats or streamstats.)
As the name implies, stats is for statistics. Per the Splunk documentation:
Description:
Calculate aggregate statistics over the dataset, similar to SQL aggregation. If called without a by clause, one row is produced, which represents the aggregation over the entire incoming result set. If called with a by-clause, one row is produced for each distinct value of the by-clause.
There are also a number of statistical functions at your disposal, avg() , count() , distinct_count() , median() , perc<int>() , stdev() , sum() , sumsq() , etc. just to name a few.
So let’s look at a simple search command that sums up the number of bytes per IP address from some web logs.
To begin, do a simple search of the web logs in Splunk and look at 5 events and the associated byte count related to two ip addresses in the field clientip.
sourcetype=access_combined* | head 5
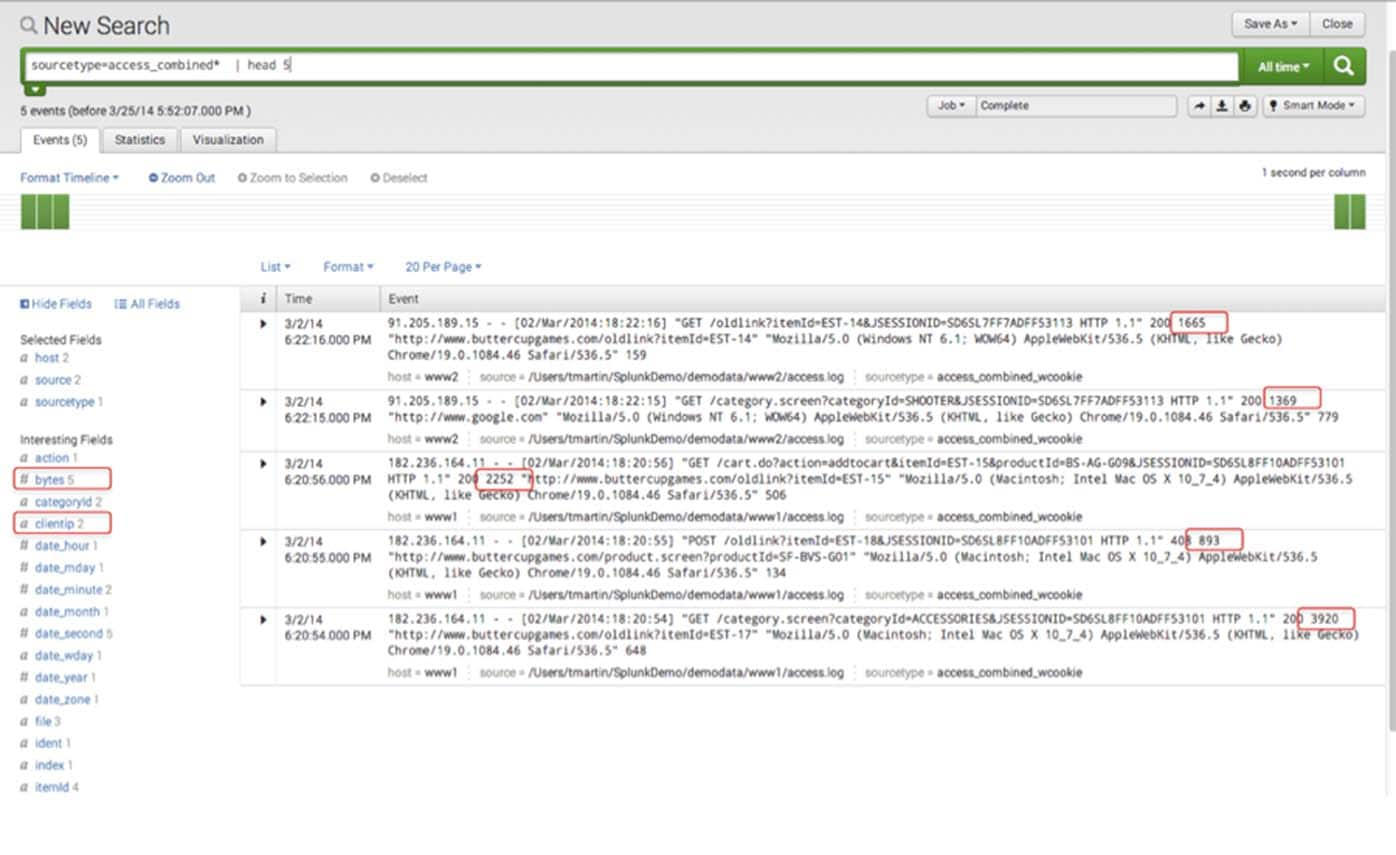
The fields (and values of those fields) of interest are as follows:
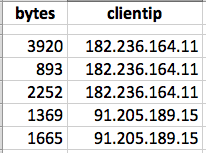
STATS
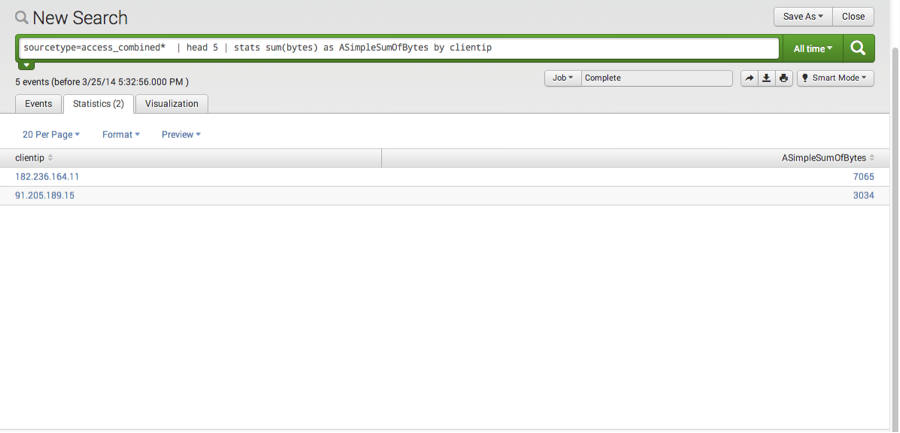
Splunk users will notice the raw log events in the results area, as well as a number of fields (in addition to bytes and clientip) listed in a column to the left on the screen shot above. Right now we are just interested in the number of bytes per clientip. Using the stats command and the sum function, I can compute the sum of the bytes for each clientip. I’ll also rename the result to be “ASimpleSumOfBytes” so that it stands out. In addition, I’ll make it easy to find alphabetically, I’ll prefix it with an “A”.
sourcetype=access_combined* | head 5 | stats sum(bytes) as ASimpleSumOfBytes by clientip
To understand what happened with the above search take a look at the “search pipeline” section of the Search Manual in the Splunk documentation and pay attention to intermediate tables, as well as the different types of search commands.
Splunk computes the statistics, in this case “sum” and puts them in a table along with the relevant client IP addresses. This is wonderful and easy, but what if one wishes to build on this and is interested in aggregating the original byte count (or any other related field) in a table such as this:
sourcetype=access_combined* | head 5 | stats sum(bytes) as ASimpleSumOfBytes by clientip | table bytes, ASimpleSumOfBytes, clientip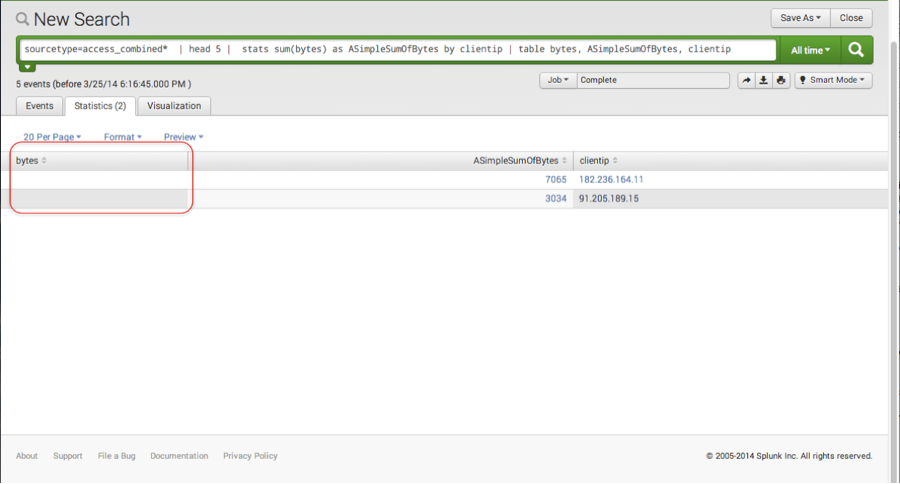
Hmmm. What happened to my bytes field? Also explained in the documentation is the anatomy of a search. With each Splunk command or term, an intermediate table is produced without the user having to issue any command to allocate the tables. If we wish to add any of the original fields (like bytes) or perform additional calculations on original fields, they would have to be placed before the stats command. See what happens in the screen shot above when we try to add the bytes field to the end of the search command string. This will make the use case for eventstats.
EVENTSTATS
Notice that the bytes column is empty above, because once the table is created by the stats command, Splunk now knows nothing about the original bytes field earlier in the pipeline. This is where eventstats can be helpful. The Splunk command, eventstats, computes the requested statistics like stats, but aggregates them to the original raw data as shown below:
sourcetype=access_combined* | head 5 | eventstats sum(bytes) as ASimpleSumOfBytes by clientip
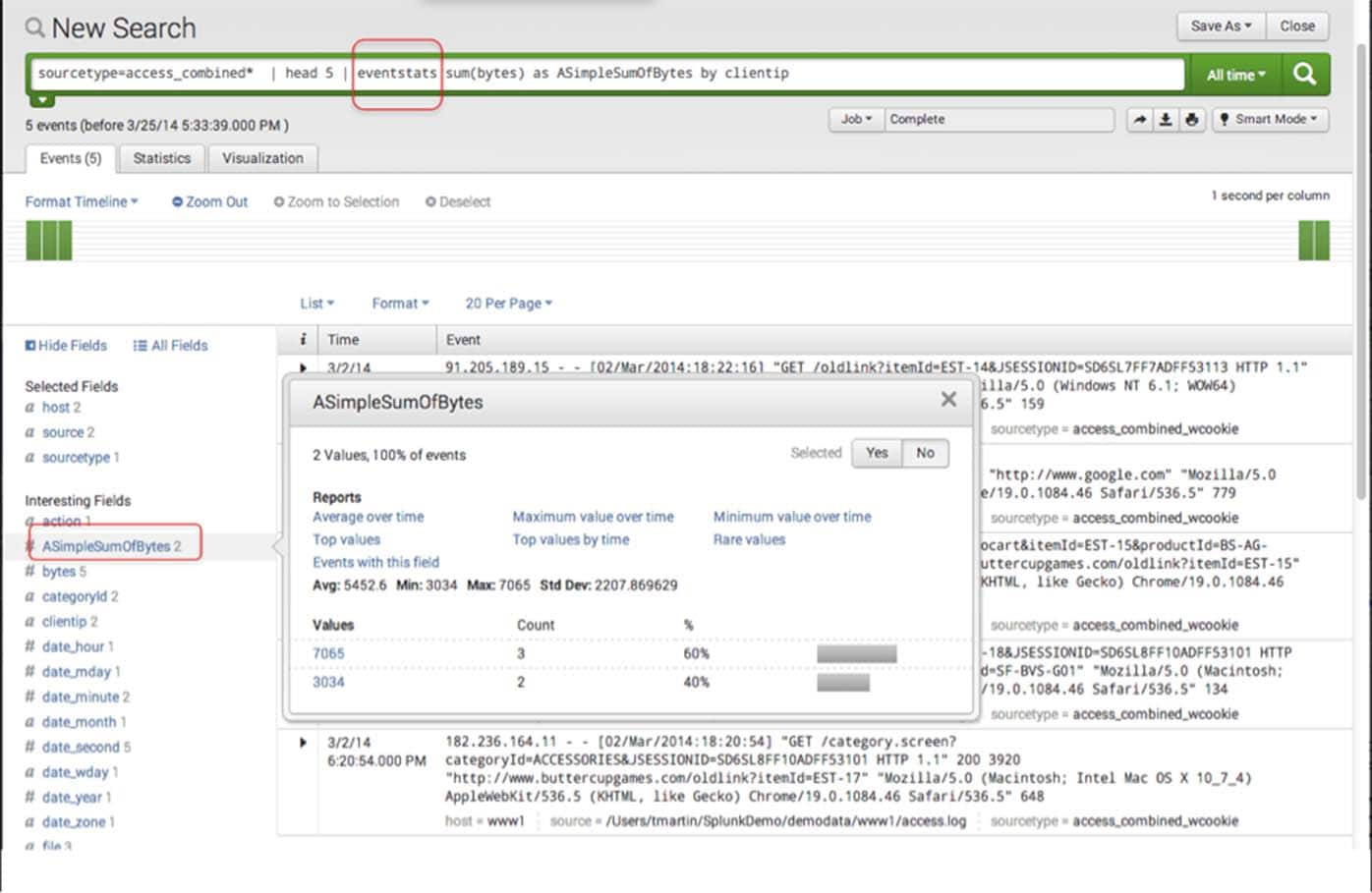
Now just like stats there are two values ( one for each clientip ) for ASimpleSumOfBytes, but they are aggregated to the raw events and can be used for later calculation. Just a note, your raw data is untouched. The aggregation is just a presentation feature that you get with eventstats.
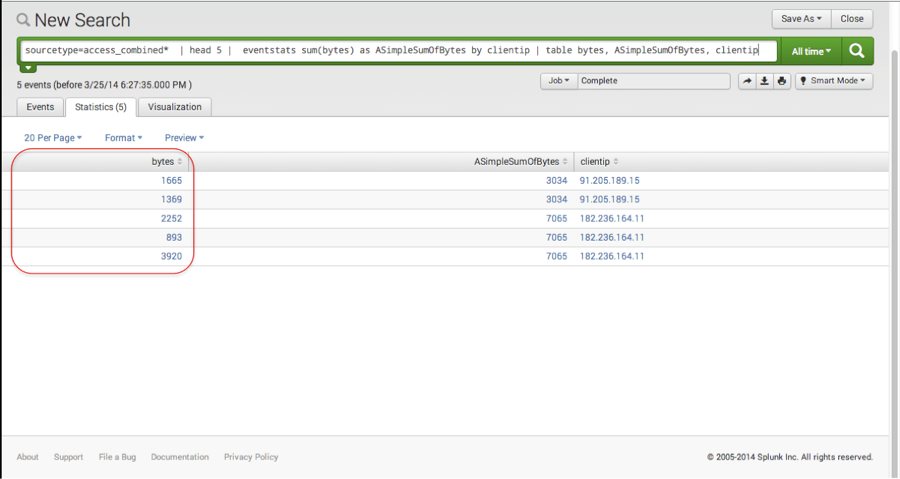
If I want to add the bytes field for each of the event along with the summation and the clientip, I can easily create the table that failed with stats. Note that the sum of all the bytes per clientip is included along side each of the original bytes value. As the following search illustrates:
sourcetype=access_combined* | head 5 |sort _time | eventstats sum(bytes) as ASimpleSumOfBytes by clientip | table bytes, ASimpleSumOfBytes, clientip
STREAMSTATS
Having the statistics aggregated onto the original events is great, but what if one is interested in what is happening in a streaming manner, or as Splunk sees the events in time. Streamstats is your command. To help visualize this, I’m sorting time in ascending order. I’ll use the “_time” internal field, and then try out streamstats:
sourcetype=access_combined* | head 5 | sort _time | streamstats sum(bytes) as ASimpleSumOfBytes by clientip
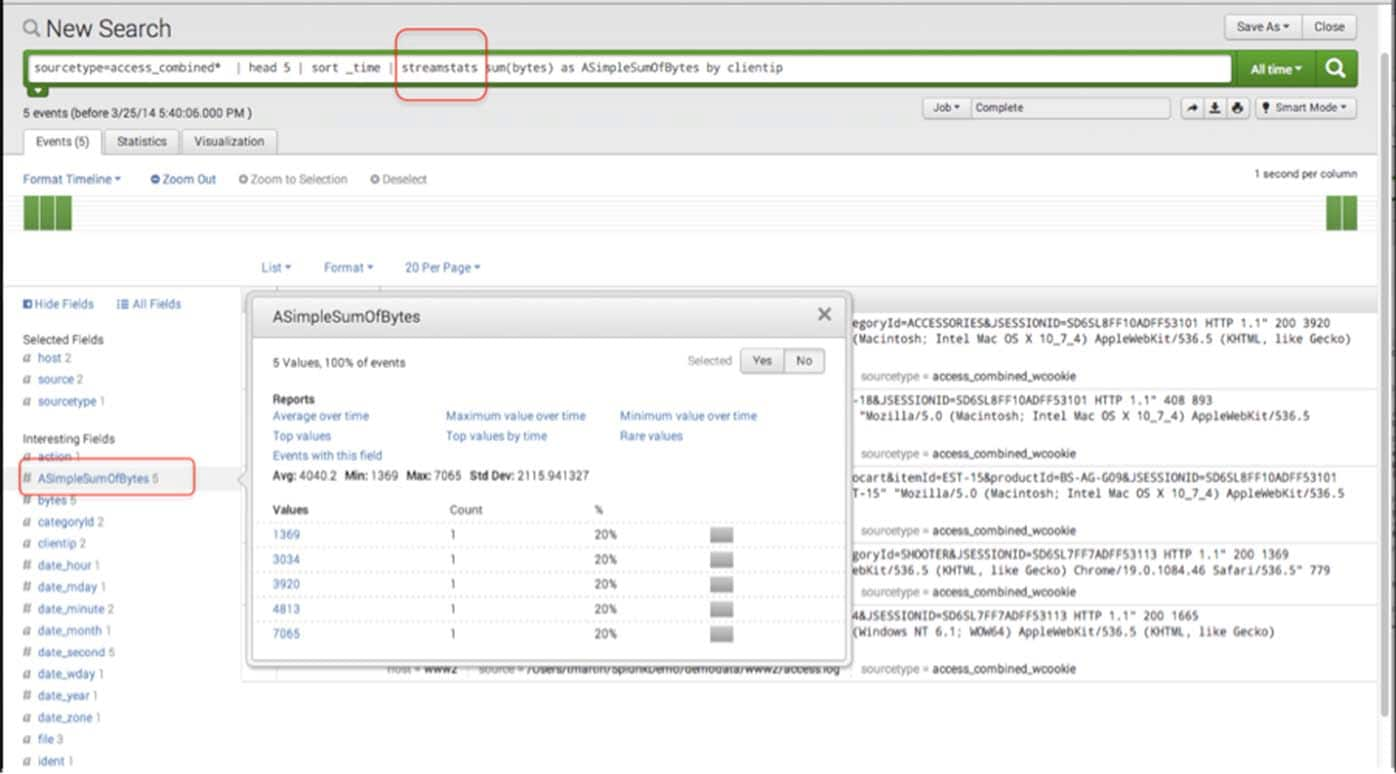
Like eventstats, streamstats aggregates the statistics to the original data, so all of the original data is accessible for further calculations, should we wish. By including time and the original byte count in the table below, we can better see what is going on with the streamstats command.
sourcetype=access_combined* | head 5 |sort _time | streamstats sum(bytes) as ASimpleSumOfBytes by clientip | table _time, clientip, bytes, ASimpleSumOfBytes
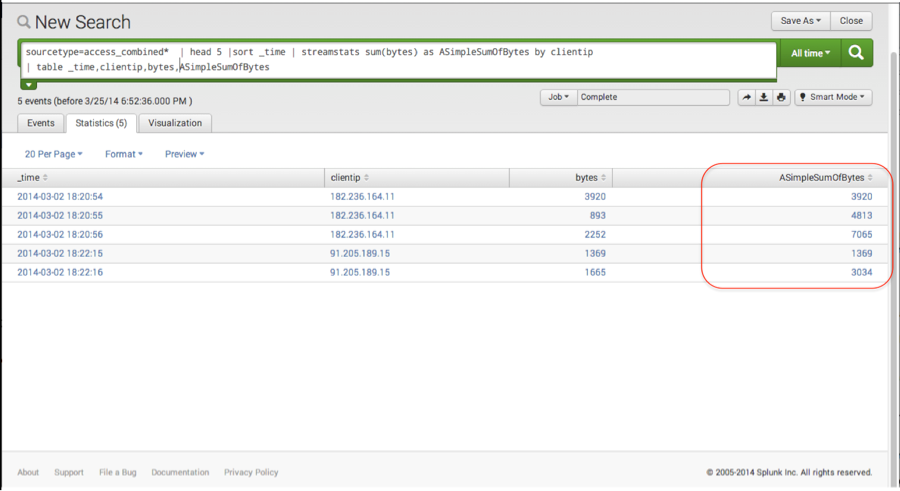
As shown in the screen shot above, instead of a total sum for each clientip (as in stats and eventstats), there is a sum for each event as it is seen in time, each one building on the other. Also note that two of these match the total sum calculated in stats and eventstats for each clientip.
The difference here is that the value of the calculated field “ASimpleSumOfBytes ” varies depending on the time that Splunk sees the event at a specific moment. Where is this helpful? As it turns out, lots of questions that folks have about their data concerns what is going on at a specific moment or range in time. Streamstats is extremely useful for this kind of searching and reporting.
Below I have included some links to the Splunk Documentation and Answers communities. Check them out. I hope this has been helpful.
Happy Splunking
References:
About the Splunk search language
http://docs.splunk.com/Documentation/Splunk/latest/Search/Aboutthesearchlanguage
Anatomy of a Splunk search
http://docs.splunk.com/Documentation/Splunk/latest/Search/Aboutthesearchpipeline#The_anatomy_of_a_search
Answers post to help understand visualizing time in Splunk, related to streamstats
http://answers.splunk.com/answers/105733/streamstats-is-reversed
Splunker finds a cool use for streamstats
http://blogs.splunk.com/2013/10/31/streamstats-example
The stats page in the Splunk docs
http://docs.splunk.com/Documentation/Splunk/latest/SearchReference/Stats
Functions that work with Stats
http://docs.splunk.com/Documentation/Splunk/latest/SearchReference/CommonStatsFunctions