

Digital Resilience Pays Off
Download this e-book to learn about the role of Digital Resilience across enterprises.

Maybe you’re interested in finding out more about deep learning? Maybe your current ML analytics are running too slowly or crushing your CPU and RAM? Or perhaps your boss has told you that they need an AI-based app so they can show off to their boss (who will then brag about it to their boss)?
As some of you will have seen we’ve recently launched the Deep Learning Toolkit (DLTK), which allows users to access external machine learning and deep learning libraries such as TensorFlow from Splunk whilst also offsetting the compute to a containerised environment. In this blog, I’d like to take you through an example of how to develop a natural language processing (NLP) use case using the Deep Learning Toolkit.
Specifically, we’re going to develop a named entity recognition use case. This is an awesome technique and has a number of interesting applications as described in this blog. Looking at Splunk’s favourite type of data (no prizes for guessing the answer is machine data) a good example for us would be automatic classification of support tickets based on the description of the issue the customer is experiencing.
For the purposes of this blog, however, I’m going to stay away from machine data and extract some key features from text copied from the Wikipedia article about one of my favourite bands… And yes there will be python code.
First of all, you will need an environment where you have installed Splunk with the following apps: python for scientific computing, the Machine Learning Toolkit (MLTK) and of course the DLTK. You should then set up Docker either in the same environment or in one that is accessible to your Splunk environment.
Follow the set-up steps in the DLTK if it is your first time using it, making sure that it can connect to Docker. You then want to launch a container from the DLTK – managing and viewing containers can be done from the Container dashboard within the toolkit. You also want to check the type of container that is running – the app comes with four pre-built container image options: TensorFlow CPU, TensorFlow GPU, PyTorch, and NLP. Ideally, you want an NLP container running, but don’t worry if that’s not the case as the instructions below will help you import the right libraries.
Note that if you are thinking of creating your own container with additional libraries Anthony’s blog here provides a great walkthrough for how to do this.
When I wrote the script for the entity extraction example here we didn’t have a pre-built NLP container image, so I ran the following from the command line to install the spaCy python library and associated NLP model:
docker exec -it <container_name> bash pip install spacy python -m spacy download en_core_web_sm
As mentioned though, you could use the NLP container in the DLTK if you want an easy button.
Next up we’re going to go through the process of developing and testing our code. Note that there is a model development guide within the DLTK under the overview tab that you can use for developing your own use cases.
To get our entity extraction algorithm working we’re going to use the Jupyter lab that is part of the DLTK architecture. If you have been using the default settings the lab can be browsed to by navigating to <host_ip>:8888, and look up the password in the model development guide in the app. Once in the lab environment, you will notice two folders:
If you navigate to the notebooks folder the first step is to take a copy of the barebones.ipynb file and rename it to something meaningful – I’ve gone for spacy_ner.ipynb.
The barebones notebook contains eight sections by default, all of which need to be completed and some of which will already have some code in. The stages are:
Next up we’re going to run through the different stages and write our code.
This is a pretty simple block of code, and we’re going to import spaCy, numpy and pandas as well as a few utility libraries and set a model directory in case we want to load sample data or save our trained model.
Import json Import datetime Import pandas as pd Import numpy as np Import spacy GLOBAL_DIRECTORY="/srv/app/model/data/"
Before writing the function sections of our code we’re going to create a small section that allows us to receive and access data within our container for development purposes. The code for this staging process is contained below:
def stage(name):
with open("data/"+name+".csv", 'r') as f:
df = pd.read_csv(f)
with open("data/"+name+".json", 'r') as f:
param = json.load(f)
return df, param
We’re going to flip back to Splunk briefly to run the search below:
| makeresults | eval text="This is some sample text about John Smith" | fit MLTKContainer mode=stage algo=spacy_ner epochs=100 text into app:spacy_entity_extraction_model as extracted
This search will send the data to the Docker container, but it won’t activate any of the stages to run code. A couple of options to note are:
Sending the data over at this point allows us to test the python code from the Jupyter lab during development, rather than having to switch between Splunk and our IDE.
The code we are going to use to initialise the model is:
def init(df,param):
import en_core_web_sm
model = en_core_web_sm.load()
return model
Effectively this code is just loading the pre-trained English tokenizer, tagger, parser, NER and word vectors that we downloaded into the container using spaCy in the environment set up.
This is a bit of an unnecessary step as we are loading the pre-trained en_core_web_sm model that can be downloaded from the spacy repos. That said, we need to include this stage to ensure compatibility with the DLTK, so we’ll add the following code:
def fit(model,df,param):
returns = {}
return returns
This section is a bit more fun, and we’re going to use the NER capabilities in spacy to extract our entity data. The code is super simple, and essentially we are breaking our input data into a list, applying the entity recognition model to each item in the list and then looping through the entities to return a string of named entities for each item in the list.
def apply(model,df,params):
X=df[param['feature_variables']].values.tolist()
returns = list()
# Loop through our list of values that we fed in from Splunk and apply the model to each item in the list
for i in range(len(X)):
doc = model(Str(X[i]))
entities = ''
# Extract individual items in the entity list find named entities, phrases and concepts
for entity in doc.ents:
if entities = '':
entities = entities + entity.text + ': ' + entity.label_
else:
entities = entities + '|' + entity.text + ': ' + entity.label_
returns.append(entities)
return returns
Given we are using the pre-trained en_core_web_sm model in this blog we’re not going to worry about saving, loading or summarising the model. I’ve included code snippets below for what the stages look like for completeness, but feel free to scroll past these to see some SPL goodness.
def save(model,name):
return model
def load(name):
return model
def summary(model=None):
returns = {"version": {"spacy": spacy.__version__}}
return returns
We’re now free to reference our spacy_ner code from Splunk using the DLTK! Clearly you can load whatever data you like (and the NLP example in the DLTK provide a text box for you to do this), but the key bit of SPL is:
| makeresults | eval text="This is some sample text about John Smith" | fit MLTKContainer algo=spacy_ner epochs=100 text into app:spacy_entity_extraction_model as extracted
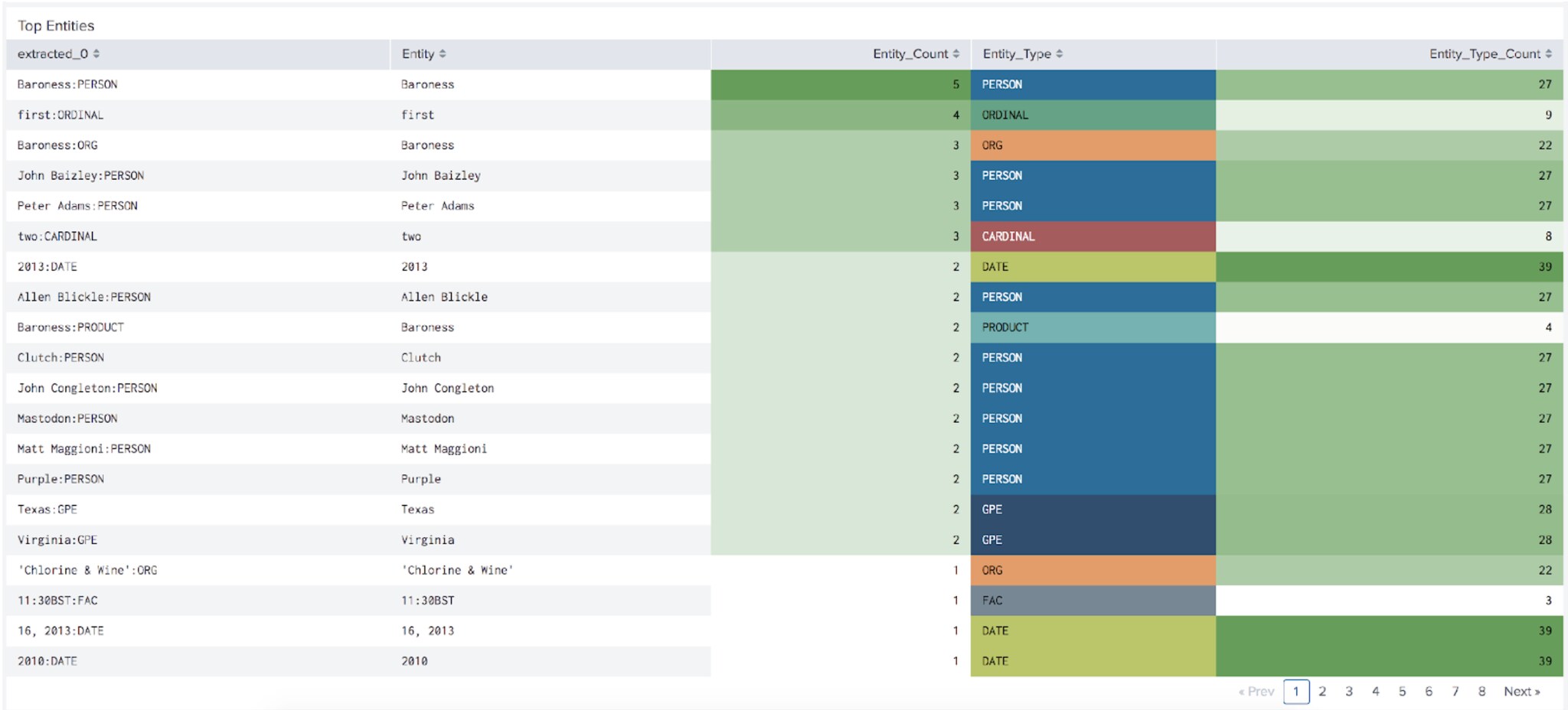
This fit command will provide a table like the one shown below, where you can see the extracted entities in the column on the right.
Once you have the extracted entity information, however, you can start to do some more interesting analysis with it – such as sorting by the entities with the highest counts to find the key attributes in the text by appending this to your search:
|makemv extracted_0 delim="|" | stats count as entity_count by extracted_0 | rex field=extracted_0 "(?<entity>.*)\:(?<entity_type>.*)" | eventstats count as entity_type_count by entity_type | sort – entity_count | table extracted_0 entity entity_count entity_type entity_type_count
Now it’s over to you to find some cool use cases like this one for the DLTK (oh yeah, and keep your boss happy with some AI-enabled innovation).
Happy Splunking,
Greg

The Splunk platform removes the barriers between data and action, empowering observability, IT and security teams to ensure their organizations are secure, resilient and innovative.
Founded in 2003, Splunk is a global company — with over 7,500 employees, Splunkers have received over 1,020 patents to date and availability in 21 regions around the world — and offers an open, extensible data platform that supports shared data across any environment so that all teams in an organization can get end-to-end visibility, with context, for every interaction and business process. Build a strong data foundation with Splunk.

Get the latest articles from Splunk straight to your inbox.
© 2005 - 2024 Splunk Inc. All rights reserved.
