
Digital Resilience Pays Off
Download this e-book to learn about the role of Digital Resilience across enterprises.

This summer, the Splunk4Good and the Splunk University Recruiting team hosted their second annual Splunktern classes, educating interns on our product and applying Splunk to open data sources. Participating Splunkterns formed teams, identified social issues and then used Splunk to promote change for social good. Final projects were presented to a panel of executives and the winning team was awarded a $1,000 charitable donation for their project’s cause.
In this series, we’ll hear how Splunkterns selected their project topics and how this impacted their intern experience at Splunk. Congratulations to Karthik and Rinita as their team’s project was selected as the winner! As a reward for their creativity and Splunk skills, Splunk4Good provided a $1,000 donation for their nonprofit of choice, Kiva.


Guest authors (left to right): Karthik Bharathala, Software Engineer Intern, and Rinita Datta, Technical Marketing MBA Intern.
Working for Splunk as an intern has many perks, one being that there are various opportunities we can take to challenge ourselves and expand our skill sets. So when presented with the opportunity to work on a project for Splunk4Good, we couldn’t wait to team up and create a Splunk app for social change. However there was just one problem—we couldn’t decide on a topic. After pondering over countless ideas, one of us brought up Kiva, a nonprofit crowdfunded micro-lending platform which provides loans to people around the world. We realized that doing a project on Kiva would allow us to indirectly help small business owners who are tackling critical issues, ranging from poverty alleviation to climate change. When discussing this idea, we noticed that we were curious about the factors that determine whether a Kiva loan is fully funded or not. And from there, we decided use Splunk to see if we could find data-driven trends about Kiva’s funding decisions.
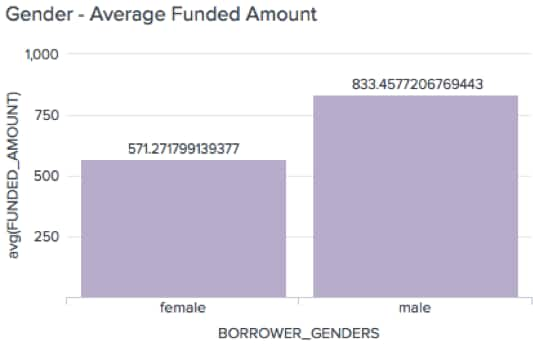
Our first step was finding reliable data for our research. We found data from Kiva’s website which included information from more than 1.4 million loan applications. These loans had attributes such as "loan amount," "activity name," "number of lenders" and more. To identify trends, we ingested this data into Splunk and created a dashboard with a few visualizations, including the number of loans by country, gender and activity. From there, we also created a visualization of the amount of money requested by gender. Interestingly, we found out that on average, men ask for about $250 more than women when applying for a loan on Kiva, even though women apply for more loans than men.

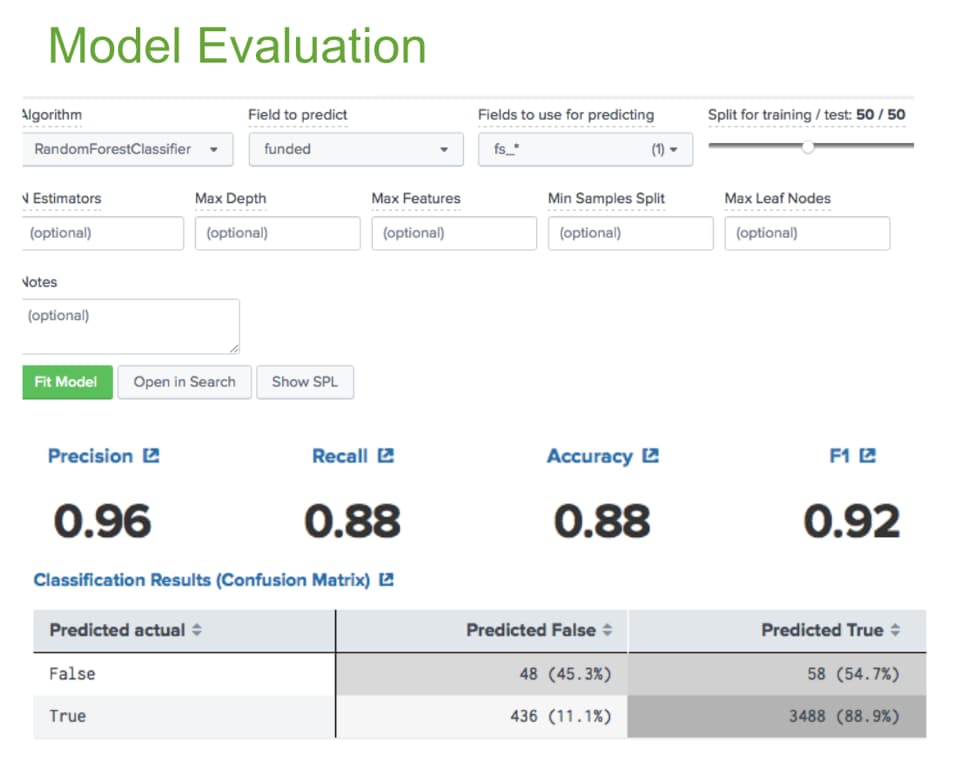
From our dashboard visualizations, we picked out the attributes that seemed to correlate with a loan request being fully funded. Our shortlisted attributes included "loan amount," "loan term," "sector name," "country name," "borrower gender" and "loan use." Using these attributes, we wished to fit a classification model with our data that could predict whether a loan application would get fully funded or not. We extracted all events with "loan status" as "funded" (1) or "expired" (0) for our model training and testing using Splunk Machine Learning Toolkit experiments. As part of data pre-processing, we used the readily available TFIDF and FieldSelector methods to convert text attributes into numerical predictors and reduce the number of false positives. We kept iterating through different algorithms to optimize the prediction accuracy, and obtained a 0.96 precision using a Random Forest Classifier. This model was published to our Splunk Kiva app and we applied it on all the loan applications in the "fundRaising" status to get a prediction on whether they will be funded or not. According to our model, 30% of new loan applications were predicted to expire.
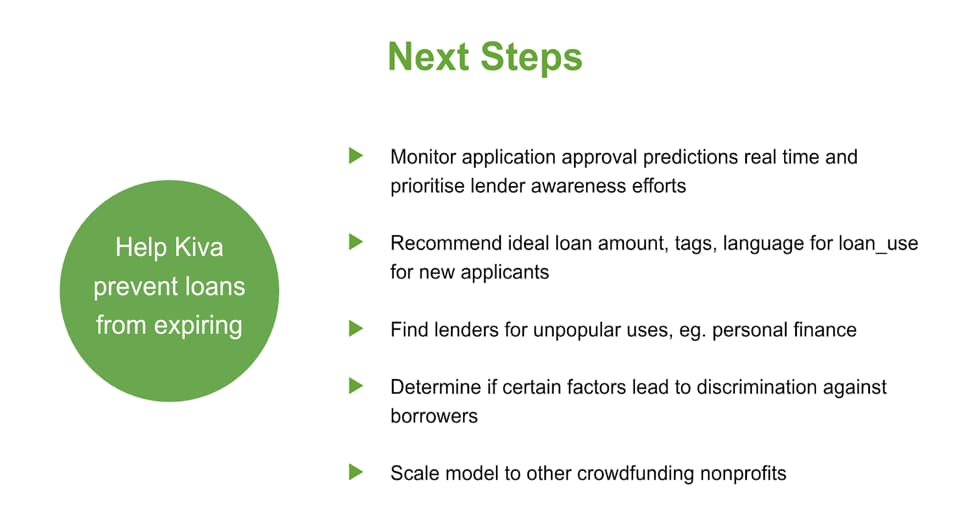
The published machine learning model can be readily applied to real-time loan application data on the Kiva website. From there, Kiva can monitor the predictions and do targeted partner marketing for applications that have a significant probability of being expired. Splunk is very powerful in correlating data from different sources, and the targeted marketing use case can be used by correlating "loan use" from loan application data with "partner intent" data. From our visualization dashboard, some readily available recommendations for Kiva loan applications include having a 8 to 14-month loan term, raising awareness for personal finance needs and requesting a low starting value (around $250), and from there use the results to raise more funds.
For the future, we hope that this model is scaled to other crowdfunding nonprofit organizations around the world, and that the NLP text analytics app on Splunkbase could be incorporated to determine if there is any discrimination happening against the borrowers.
Overall, we really enjoyed working on this project outside our internship deliverables, and learned a lot about Splunk-ing. The key takeaway we had was that we can always find time to give back to our communities, and Splunk4Good’s various programs help us do that in a sustainable manner.

The Splunk platform removes the barriers between data and action, empowering observability, IT and security teams to ensure their organizations are secure, resilient and innovative.
Founded in 2003, Splunk is a global company — with over 7,500 employees, Splunkers have received over 1,020 patents to date and availability in 21 regions around the world — and offers an open, extensible data platform that supports shared data across any environment so that all teams in an organization can get end-to-end visibility, with context, for every interaction and business process. Build a strong data foundation with Splunk.

Get the latest articles from Splunk straight to your inbox.
© 2005 - 2024 Splunk Inc. All rights reserved.
