
Digital Resilience Pays Off
Download this e-book to learn about the role of Digital Resilience across enterprises.

Splunk @ Splunk highlights stories of how we utilize our own technologies to drive real value and insights to fuel the growth of our rapidly expanding global organization.
In my current role at Splunk, I manage Global Data Center Operations mostly focused on Server, Virtualization, and Storage Infrastructure. My team is made up of DevOps and Software Engineers—located in San Francisco, San Jose, Seattle, Dublin and London—and we provision, manage, and monitor VM storage/compute resources for internal teams providing various levels of support.
For some of our teams we are the service owners, doing everything including application deployment and maintenance. For other teams we simply provide the raw storage/compute and they manage the instances themselves.
Today my team uses Splunk internally for typical break/fix alerting and monitoring, but we’ve been expanding our internal Splunk footprint to more Business Intelligence and non-conventional use cases.
One case-in-point was our VM Footprint Reduction Project; our overall VMware footprint was growing and our capacity was trending toward exceeding our contract constraints. We utilized Splunk to identify the specific resources that were deployed, who was using these resources, and how heavily the resources were actually being utilized. The data was then analyzed to identify:
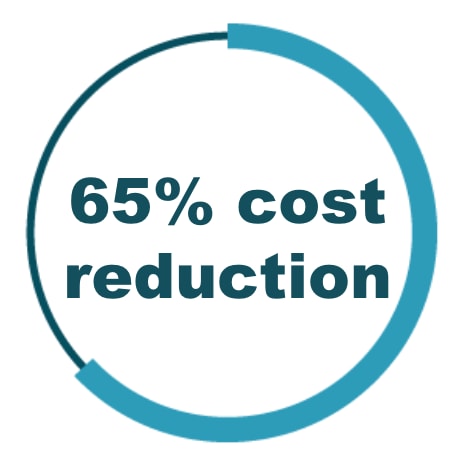 |
The results from this project were dramatic. Beyond our goal of simply remaining within our licensing limits, we expected some cost savings as well. The reality was a 65% reduction in immediate VM licensing costs in the first year alone. Not only will we continue to realize this licensing cost savings in coming years, but with the improved monitoring and analysis tools, we expect to see increasing savings over time.
We’re also using Splunk to improve our VM capacity planning process. Our old VM capacity planning methodology was largely a manual process that we performed quarterly. About three weeks before the end of the quarter, leadership would aggregate all reports from the various data sources. Sitting down with IT staff for close to two weeks, we would normalize the data and condense it down to a PowerPoint slide for executive staff. This process required 30+ hours each quarter with many people involved. At the end of this process, we looked at everything and then made a gut decision about what our customers might need in the coming months.
Splunk helped evolve this process from the older “gut-check” methodology to a more efficient metrics-based approach with better prediction and far fewer manual touch-points. Metrics are always the key to more qualified, better quality decisions.
All the reports that went into capacity planning were fed into Splunk, resulting in customized dashboards with far better forecasting. Current data was compared against expected data (utilizing known-good data models) to identify outliers that might indicate issues like improper configurations or possibly deployments to an incorrect location. Historic trends are turned into continuous performance capacity metrics and used to architect new hardware, add capacity based on requests in the pipeline, or analyze utilization in order to move capacity among environments, keeping things balanced and efficient. Splunk gives us the ability to make decisions based on data and metrics instead of gut feelings.
This allows us to:
 |
How does this all translate in the real world? We significantly reduced the amount of time, data processing, and human resources required to do VM capacity planning each quarter by 70-85%. More importantly, by making data-based decisions, we are proactively aligning resources with business needs and rebalancing on the fly as needed.
Now that we’ve gotten a great handle on our VMs, we’re looking at becoming more innovative in our Splunk usage for load balancing, life-cycle management, and capacity management. We’re moving from the purely reactionary posture of the past to one where we actually begin to predict and prevent issues before they occur.
Using Splunk, we can stay ahead of the curve while minimizing our costs and providing the best possible services to our customers.
----------------------------------------------------
Thanks!
Sean Jacobs

The Splunk platform removes the barriers between data and action, empowering observability, IT and security teams to ensure their organizations are secure, resilient and innovative.
Founded in 2003, Splunk is a global company — with over 7,500 employees, Splunkers have received over 1,020 patents to date and availability in 21 regions around the world — and offers an open, extensible data platform that supports shared data across any environment so that all teams in an organization can get end-to-end visibility, with context, for every interaction and business process. Build a strong data foundation with Splunk.

Get the latest articles from Splunk straight to your inbox.
© 2005 - 2024 Splunk Inc. All rights reserved.
