
Digital Resilience Pays Off
Download this e-book to learn about the role of Digital Resilience across enterprises.
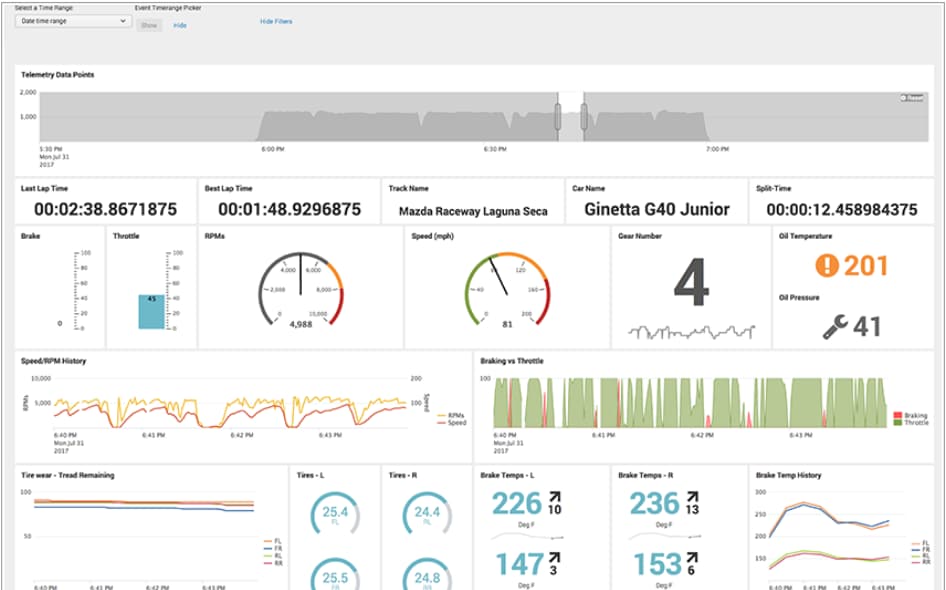
At .conf19 a couple weeks ago, we announced the General Availability of Splunk Cloud 8.0. In addition to highlighting the new capabilities of the 8.0 release, I also wanted to summarize some of the customer feedback I have received in this blog. Specifically, how Splunk Cloud administrators plan to take advantage of the new 8.0 features to make their lives easier managing their Splunk Cloud environment at scale.
Splunk Cloud 8.0 brings a host of new features including:
While there are many worthy features in Splunk Cloud 8.0, I’ve been repeatedly told one particular feature is a game changer for Splunk Cloud admins – Workload Management (WLM) – and why I’ll focus on it here.
Currently, one or more of the following scenarios are common but difficult for Splunk Cloud administrator to predict and police:
WLM addresses these scenarios by allocating CPU and memory resources in a logical container of resource groups called workload pools. This results in:
The Splunk Cloud team have worked hard to ensure WLM is a fully self-service feature that is easy to configure and use. Even without performing any WLM configuration in Splunk Cloud 8.0, WLM is already working in the background—the ingest workload isolation rule is enabled by default to protect against data ingestion lag
When you are ready to create your workload rules, we’ve provided a simple framework for you to operate within. First, Splunk Cloud comes with pre-configured workload pools for you to utilize—this takes the guesswork out of WLM and allow you to quickly utilize the feature. There are three workload pools that take effect when there is search contention:
Next, you create workload rules to assign specific searches against the pre-configured pools. You name of the rule, specify the search criteria and the corresponding action. For example, if your use case is to protect against users running a search across all available indexes or against all time, you can set the action to send these types of searches to the limited_perf pool. This ensures the search continues to run but consumes a much smaller percentage of the available Splunk Cloud resources. And that’s it—you’ve just created your first WLM rule.
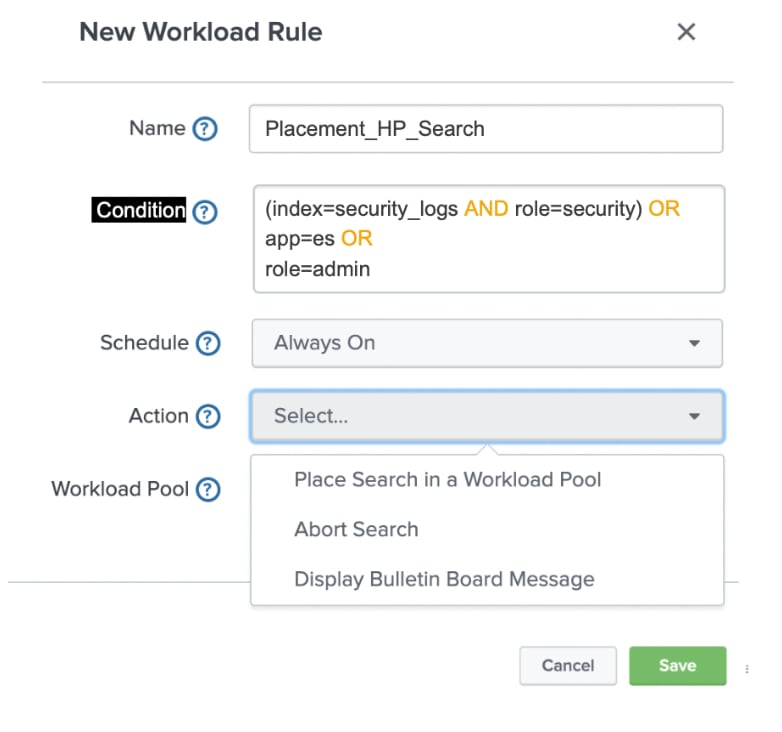
WLM is built for scale so you can have up to 100 workload rules for your Splunk Cloud. Some customers may already have a backlog of scenarios that they are prepared to create rules to mitigate against immediately and others are still mulling how best to utilize WLM. No matter which end of the WLM adoption spectrum you reside on, every customer whom I have spoken to have consistently indicated they will start with a primary scenario, create the appropriate workload rule and measure results. There may be multiple iterations in the first use case to fine tune the parameters. Once they are comfortable that the primary use case, then they can proceed to the next one.This iterative approach to adopting WLM is definitely a best practice for all customers since you can ensure predictable feature behavior and outcomes that meets the needs of your teams. You can learn more about WLM on the Splunk Cloud documentation site.
----------------------------------------------------
Thanks!
Azmir Mohamed

The Splunk platform removes the barriers between data and action, empowering observability, IT and security teams to ensure their organizations are secure, resilient and innovative.
Founded in 2003, Splunk is a global company — with over 7,500 employees, Splunkers have received over 1,020 patents to date and availability in 21 regions around the world — and offers an open, extensible data platform that supports shared data across any environment so that all teams in an organization can get end-to-end visibility, with context, for every interaction and business process. Build a strong data foundation with Splunk.

Get the latest articles from Splunk straight to your inbox.
© 2005 - 2024 Splunk Inc. All rights reserved.
