
Digital Resilience Pays Off
Download this e-book to learn about the role of Digital Resilience across enterprises.
Readers of some of my previous blogs will realise that using Splunk in higher education is a passion of mine – I’ve written previously about how Splunk can be used for social good in higher education and also described one of our projects in the #EUvsVirus hackathon where we built a machine learning pipeline for predicting student outcomes.
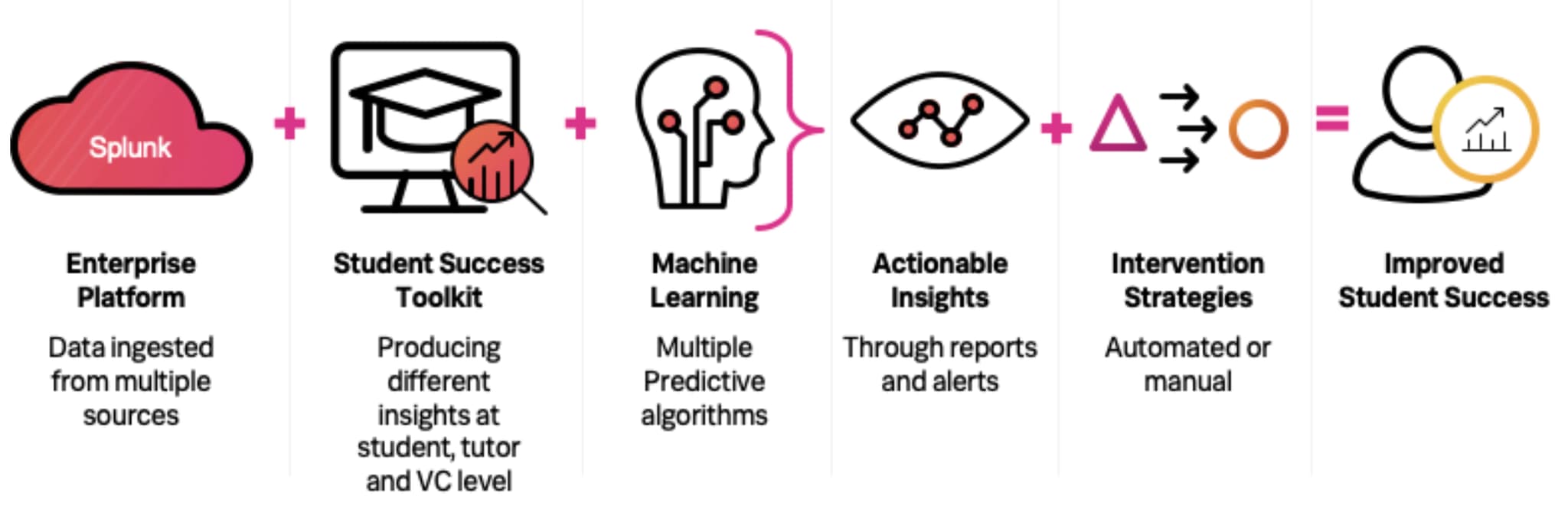
This blog outlines how we have turned our #EUvsVirus project into reality with the new Smart Education Insights App for Splunk. Leveraging the work we have already done on the Student Success Toolkit, this app is a Smart Workflow that is built on top of the Machine Learning Toolkit (MLTK) and provides a guided workflow to help users gain insight using machine learning into student performance and engagement.
As many of you will already know, Splunk is used extensively in the higher education sector across a range of use cases, but predominantly for cybersecurity (where we have been named a leader by Gartner for the past seven years) and IT Operations (again, as we are well recognised as a market leader for AIOps by Gartner).
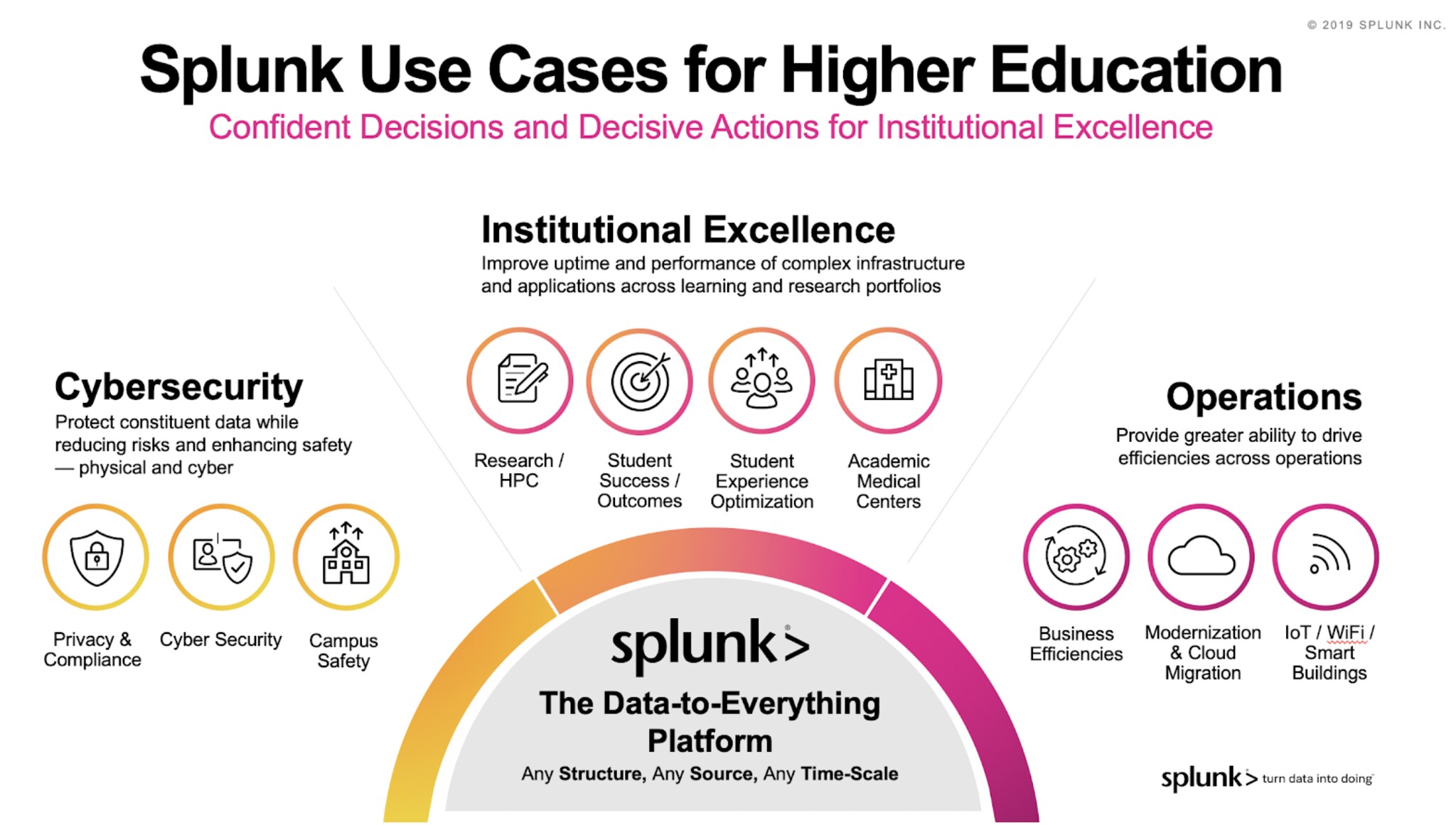
One additional area where we have seen increasing interest from our customers recently is using Splunk to improve student success. Here we are talking about monitoring performance and engagement of students to ensure that they are being provided with the best support possible from the university.
The Smart Education Insights App for Splunk allows universities to apply predictive models to the data they are collecting and estimate the likely outcomes for each student. These types of insights can help inform appropriate intervention strategies, potentially improving student success as we have done previously at UNLV, for example.
Although the app is designed to be better with the Student Success Toolkit, it can also be used independently.
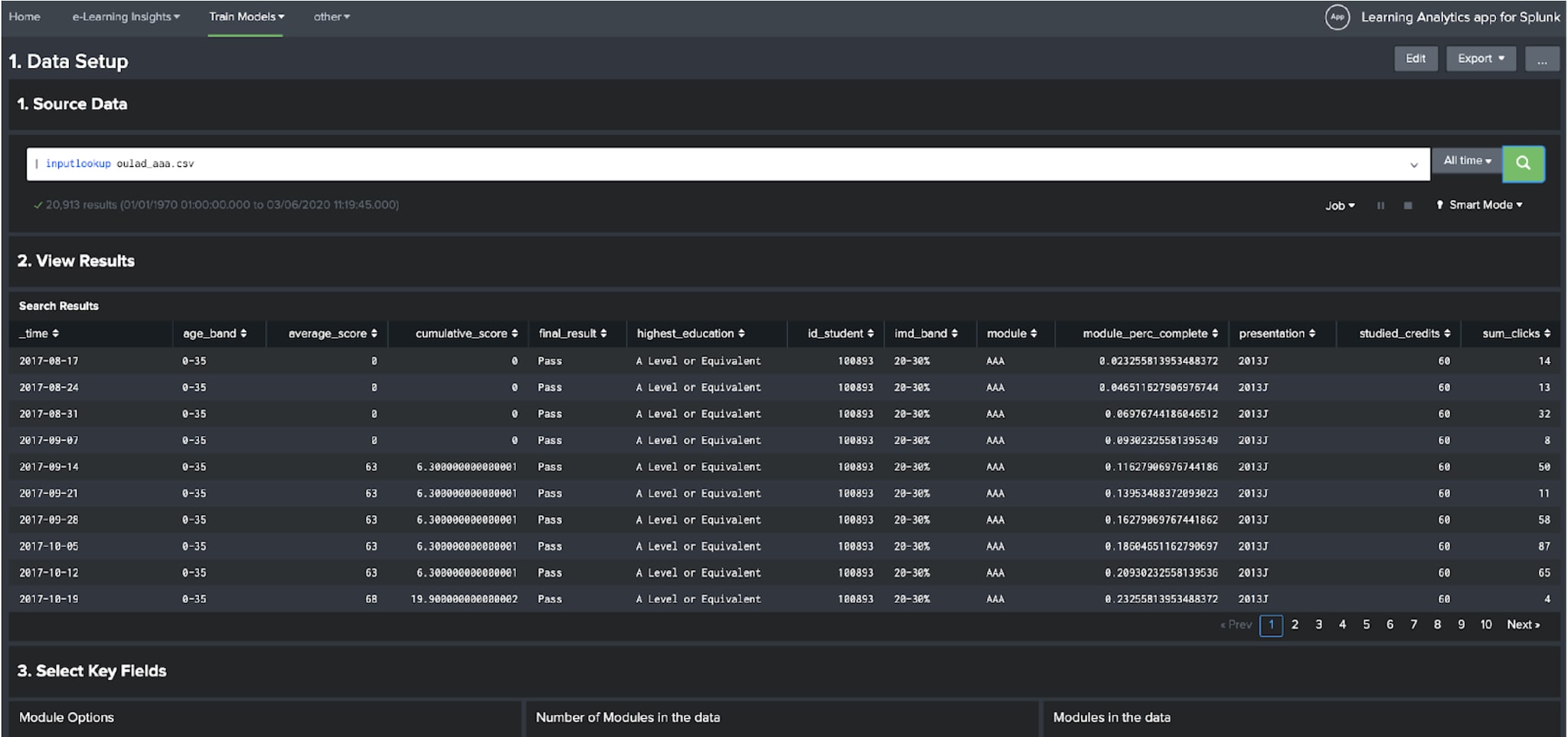
Once the app and its dependencies have been installed, it is a case of inputting a search that returns some historic data that describes for a single module or course:
We will describe in more detail how you can create this kind of dataset in part II of this blog series, but a few things that you will need to ensure with this data is that:
All of these data types are required by the app to train the models, but if you have additional information, feel free to include that as well. We’d recommend that you generate your dataset using the data models from the Student Success Toolkit, as these already contain a range of useful fields for this type of analysis and can also be accelerated to improve performance.
Note that you will also need to set up an index called learning_analytics_model_testing_metrics to use the app.
On this dashboard you need to input a search that returns the data you want to use for your predictive models. Once you input the data, select the field that represents the module or course from the dropdown.
If the module has been seen by the app before, a table will allow you to link to the management dashboard (more on this shortly), otherwise you will be asked to input: the student ID field, a demographic field (optional), a field that represents engagement, a grade field (optional), the result field and then finally the value in the result field that represents a student dropping out.
Once you have made your selections, they can be saved, which will then allow you to train the engagement and/or the predictive models.
On this dashboard, you should select the cycle that you want to calculate the engagement over; either a weekly or monthly period. It is recommended that you try to calculate the thresholds on a weekly basis as this will allow you to be more responsive to changes in student engagement – reacting on a weekly time scale rather than a monthly one. Note that the first search from the data input dashboard will determine the period that can be applied to the model too; if you only have records at monthly intervals, then weekly cycles will not be possible.
Once you have selected the cycle, simply click the ‘train models’ button, and once the search has been completed, you should see the thresholds for very high, high, low and very low engagement that have been calculated over a calendar year.
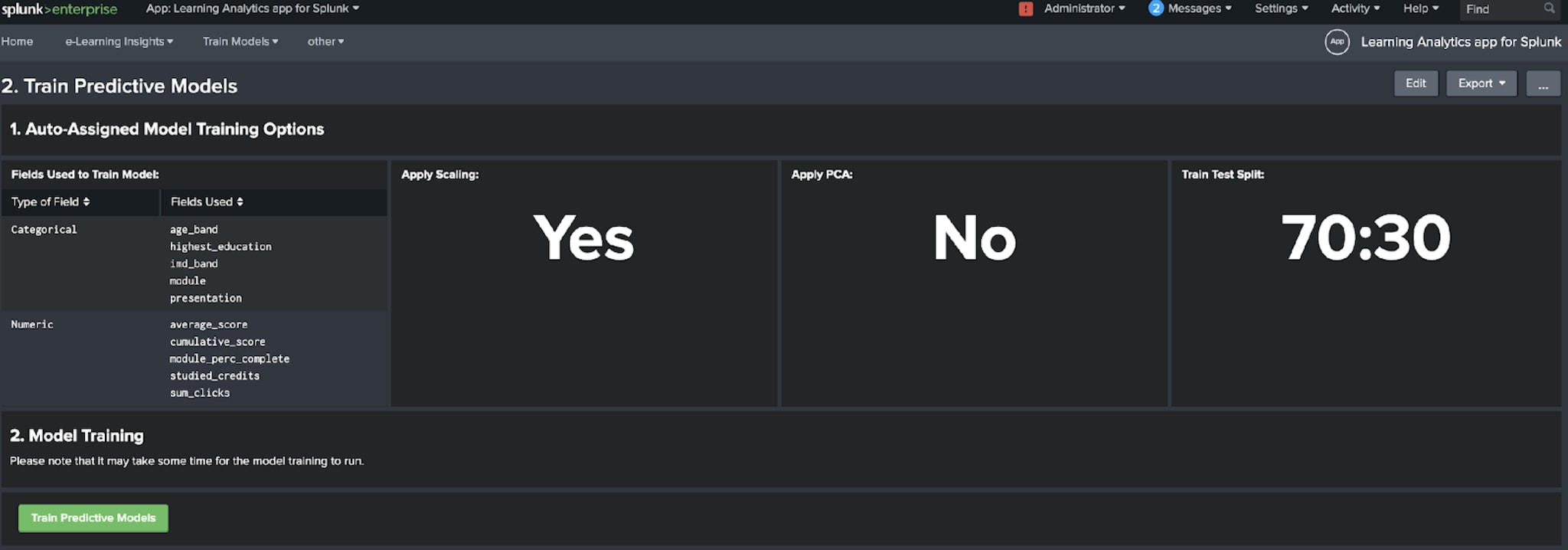
On this dashboard, you should be presented with a report that tells you a bit about your input data, whether fields are numerical or categorical. There will also be a set of panels that tell you if scaling or PCA is going to be applied and also what the train test split is going to be for the data. For more details about this type of pre-processing please refer to our blog here.
Provided you are happy with what the app recommends, hit the ‘train predictive models’ button, which will start to generate two predictive models using the training dataset: one to predict the outcomes for the students and one to predict if a student is likely to drop out. Once the searches to train these models have completed, it will report how many records were used for each, and a button to test the models will also appear on the dashboard.
Clicking on the ‘test predictive models’ button will then apply the newly trained models to the test dataset to generate some performance metrics. These metrics will be calculated for a range of algorithms and sent to the learning_analytics_model_testing_metrics index. The dashboard has a set of panels that will go to 100% when the testing is complete for each algorithm.
Once all algorithms have been tested, feel free to click on the button at the bottom of the to see the results on the test predictive models dashboard.
This dashboard presents two tabs, one for each type of predictive model. On each tab, you will be shown the algorithms that have been applied to your data, and a recommendation will be made as to which algorithm has the best performance (which is judged by the accuracy of each algorithm) as well as assessing the performance of the recommended algorithm as Very Good, Good, Acceptable or Poor.
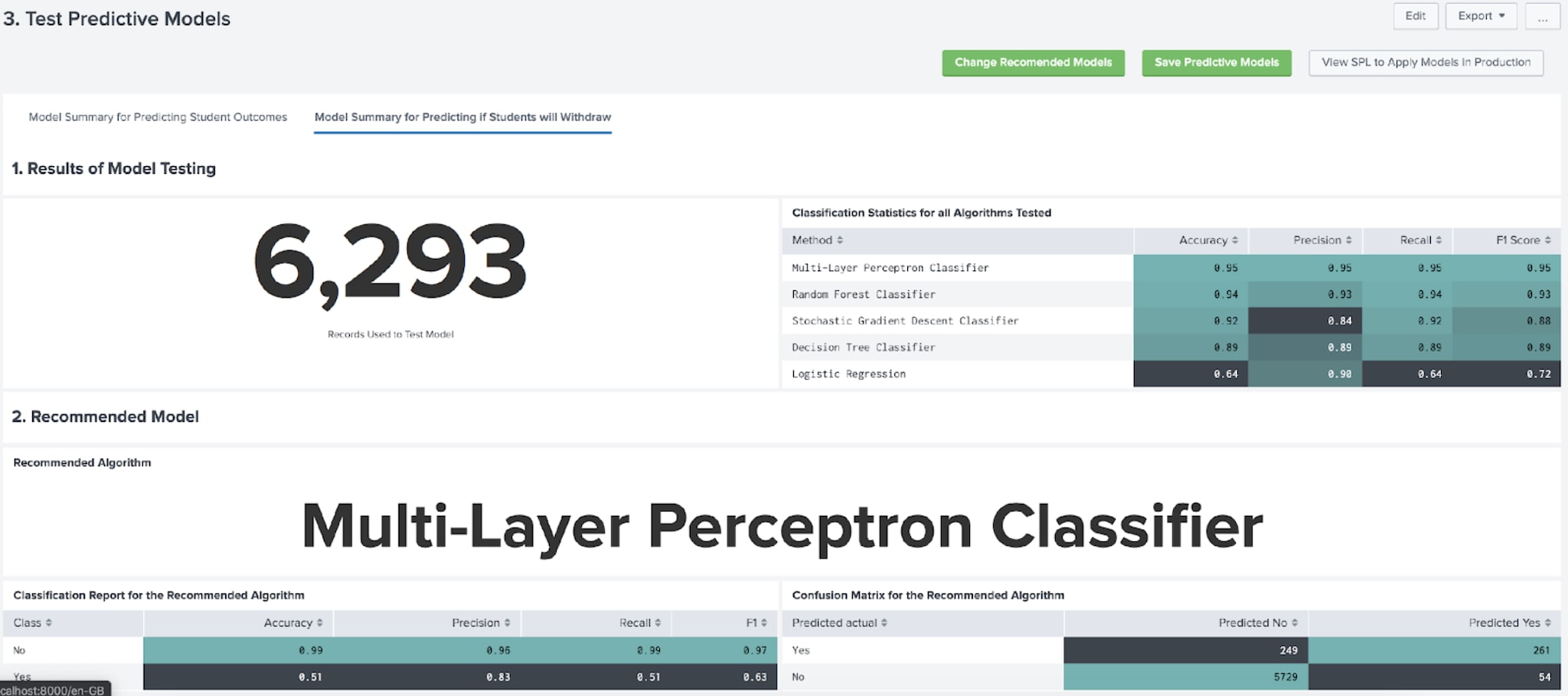
You can choose to change the recommended model if you like, and there are also options to view a search that would allow you to apply the recommended (or selected if you choose to change it) algorithm to your data.
Provided you are happy with the results and performance of the recommended or selected model, you can save it, which will then allow you to manage the model or to visualise some of the predictions on data as it is coming into Splunk.
This dashboard allows you to view all of the modules or courses that you have modelled in the app. For each module you can view if engagement or predictive models have been trained and choose to train them if they haven’t. There are also options to manage the permissions of the models generated in the app – by default they will only be visible to the user who trained them, but once satisfied that they are performing well it is recommended that you make them available to a wider group of users.
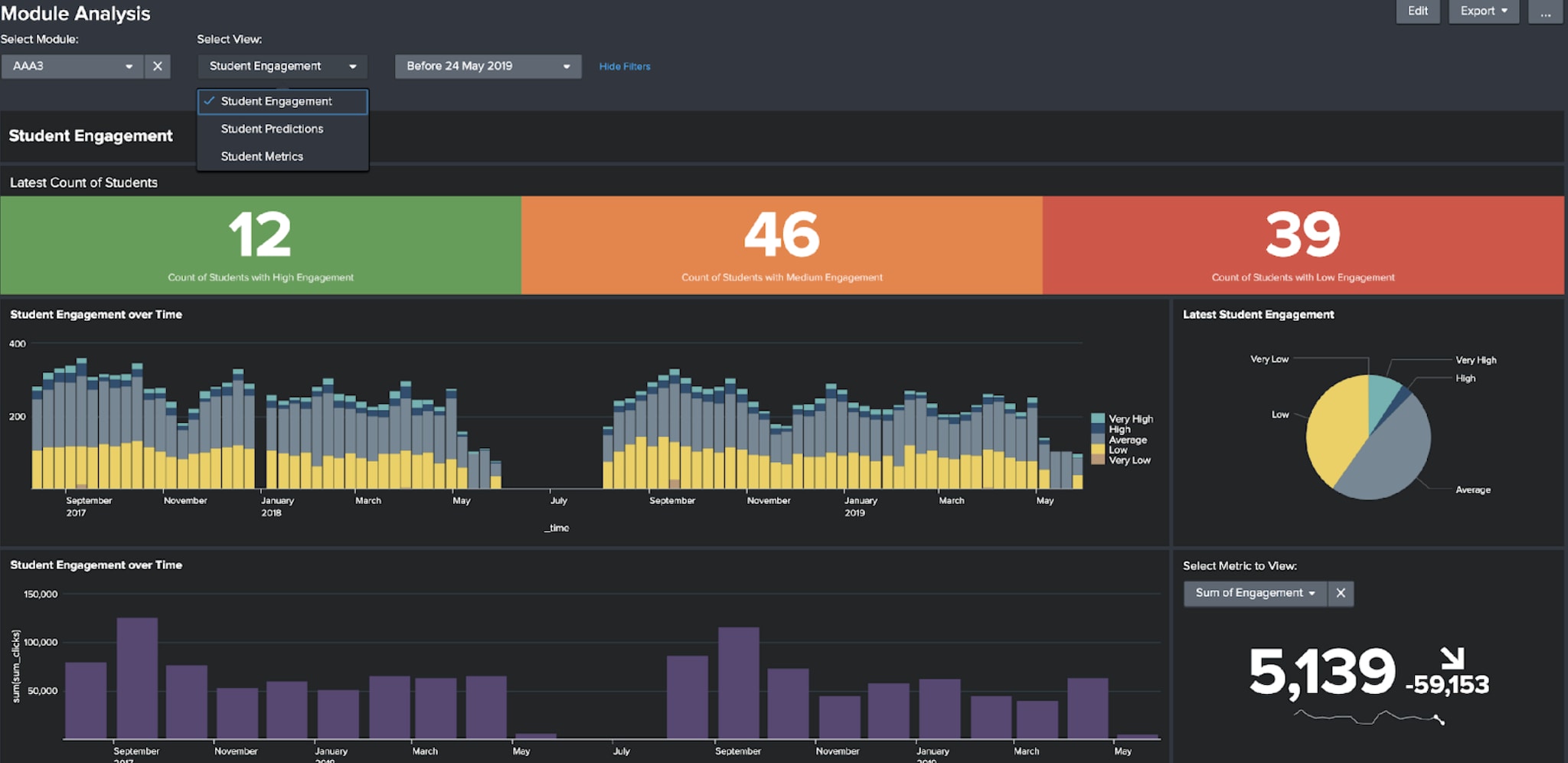
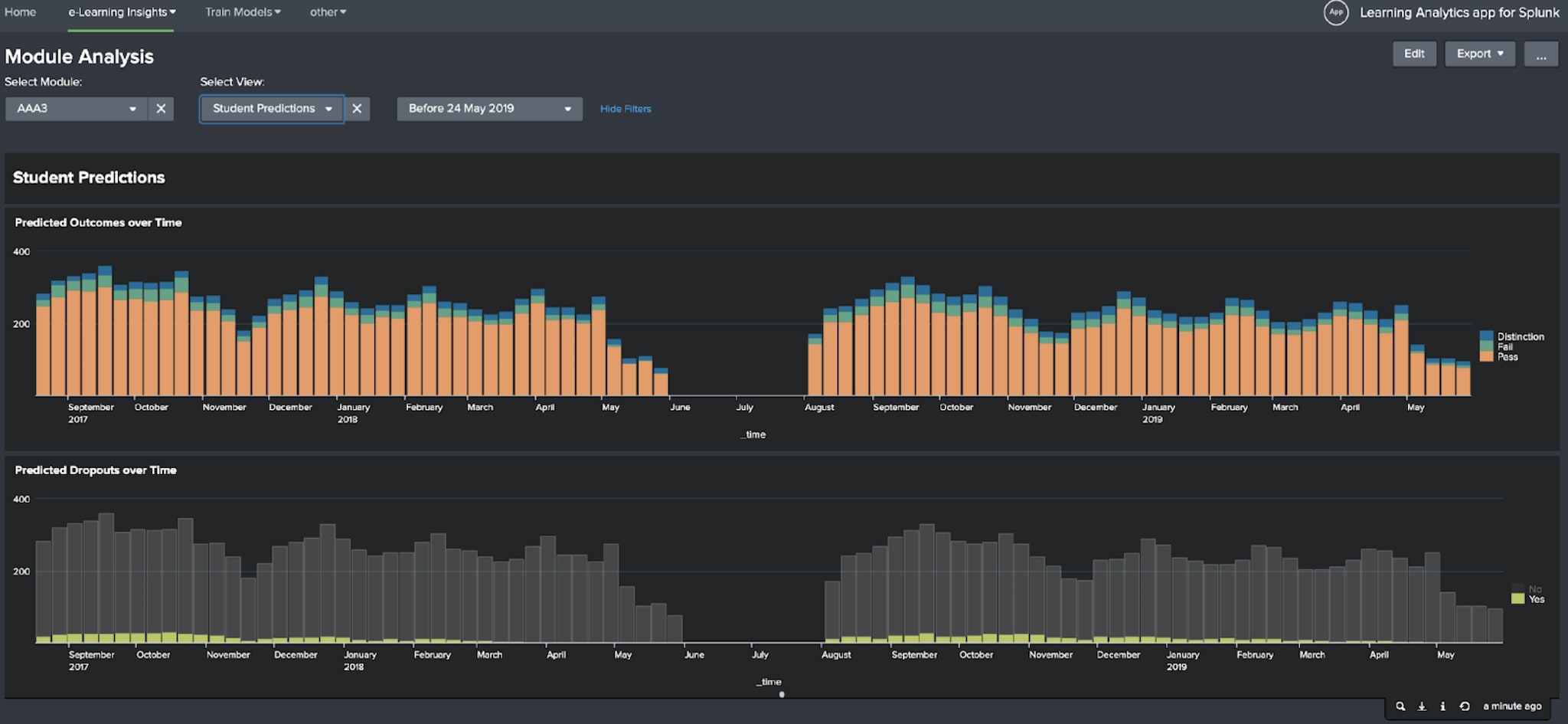
The app comes with a set of pre-built dashboards for analysing the insights that the predictive models provide. These are the Module Analysis, Analysis of At-Risk Students and Student Analysis dashboards. Some of the panels on each dashboard require the engagement and predictive models to have been trained in order to populate.
If you want to find out some useful pointers for preparing your data for the Smart Education Insights App for Splunk, please read the second instalment of this blog. Also stay tuned for further announcements of other Smart Workflows at .conf20, on our website and on our ML blog pages.
Special thanks to Mark Woods, Helen Baldwin, Rupert Truman, Kelly Kitagawa and Hans-Henning Gehrts for all their help in the #EUvsVirus hackathon - without which this app would not have been possible!

The Splunk platform removes the barriers between data and action, empowering observability, IT and security teams to ensure their organizations are secure, resilient and innovative.
Founded in 2003, Splunk is a global company — with over 7,500 employees, Splunkers have received over 1,020 patents to date and availability in 21 regions around the world — and offers an open, extensible data platform that supports shared data across any environment so that all teams in an organization can get end-to-end visibility, with context, for every interaction and business process. Build a strong data foundation with Splunk.

Get the latest articles from Splunk straight to your inbox.
© 2005 - 2024 Splunk Inc. All rights reserved.
