
Digital Resilience Pays Off
Download this e-book to learn about the role of Digital Resilience across enterprises.
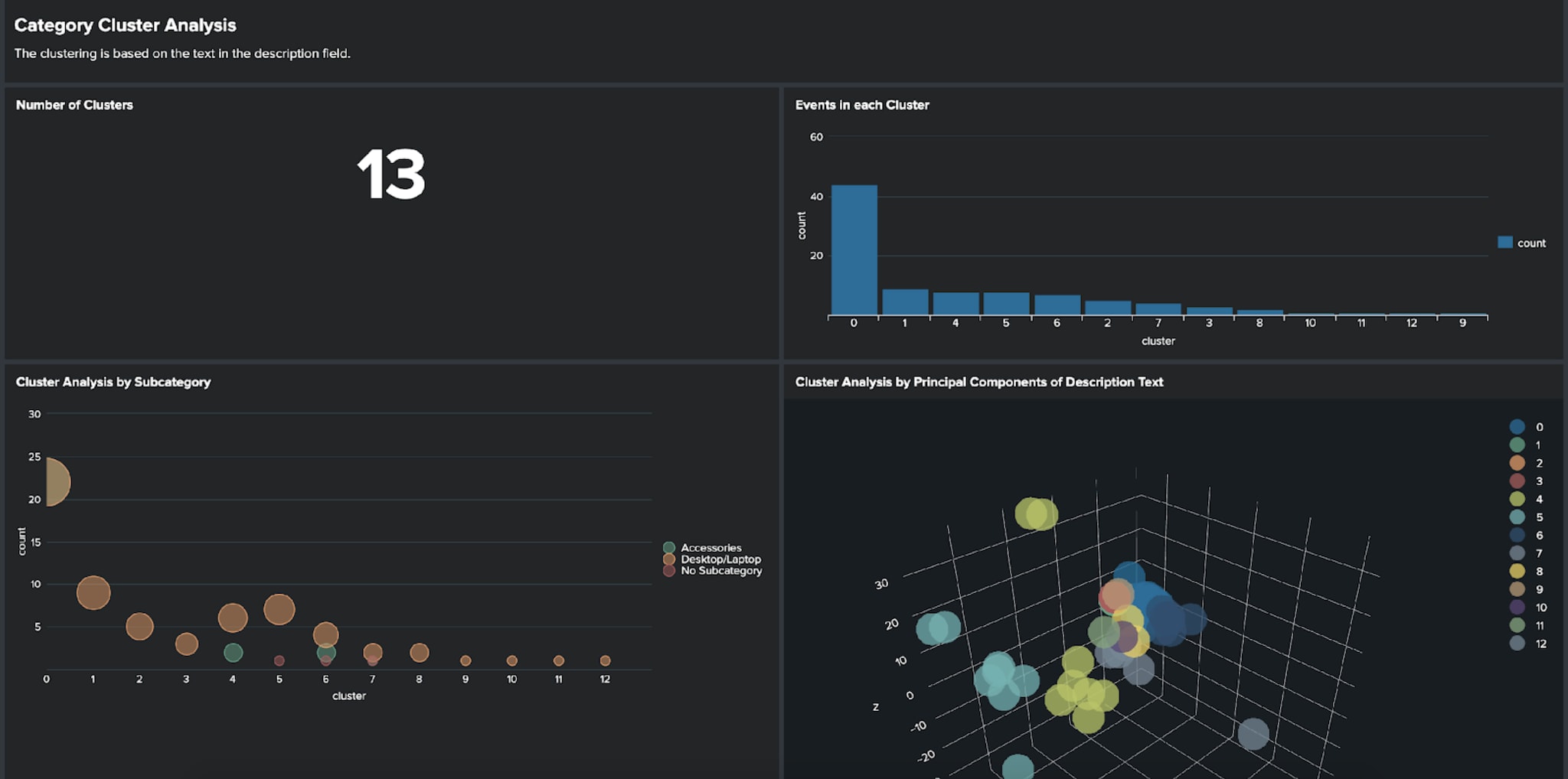
I’m excited to announce the launch of a new series of apps on Splunkbase: MLTK Smart Workflows. These apps are domain-specific workflows, built around specific use cases, that can be used to help you develop a set of machine learning models with your data. In this blog post, I’d like to take you through the process we adopted for developing the workflows.
 Built on top of the Splunk Machine Learning Toolkit (MLTK), Smart Workflows are designed to easily guide you through the process of developing a machine learning model with a few click-and-select options - regardless of your prior experience with model building. All of the details of the techniques being used in the Smart Workflows, as well as additional sources of information, will be available to users if they are interested in learning more about data science.
Built on top of the Splunk Machine Learning Toolkit (MLTK), Smart Workflows are designed to easily guide you through the process of developing a machine learning model with a few click-and-select options - regardless of your prior experience with model building. All of the details of the techniques being used in the Smart Workflows, as well as additional sources of information, will be available to users if they are interested in learning more about data science.
We are releasing two Smart Workflows apps as part of the initial launch: the Smart Ticket Insights app for Splunk and the Smart Education Insights app for Splunk. You can read more about these apps in their respective blog posts, which describe the use cases they are solving and how to use the app.
I hope that many of you will be familiar with the Experiment Assistants and Smart Assistants that exist in the MLTK today. Smart Workflows are similar to Smart Assistants in that they provide guided assistance, which helps users generate analyses and insight from their data. Users get help building models in a step-by-step process so they can still benefit from machine learning without being formally trained in data science.
This type of process is often described as automated machine learning (autoML) as it allows you to generate insight from your data by selecting a few options and clicking a few buttons – rather than having to build a model from scratch.
It is worth noting that Smart Workflows perform pre- and post-processing of the data on behalf of the user and can also apply multiple algorithms to the data in a single pipeline. This differs from the smart assistants, which have limited pre-processing options, and the experiments, which rely on users to determine what pre-processing to apply to the data. Neither smart assistants nor experiments allow users to apply multiple algorithms in a single pipeline either.
The starting point for building both of the Smart Workflows apps came from customers approaching us with a problem. In both cases, there were a couple of aspects that we identified which made these problems suitable for a Smart Workflow solution:
Once we were confident that we ticked both of these boxes, we began testing hypotheses that we could prove (or disprove) as we sought to solve these problems.
Without going too much into the details, a good hypothesis should be simple and testable – identifying the subjects, variables and effects that you will be measuring. In our two examples we had the following hypotheses:
For those interested, I recommend this cool blog here, that can take you through some of the mistakes to avoid when coming up with a hypothesis.
Like everything in Splunk, we really need to start with some data. Critical to any data science project is having an understanding of the data that you are going to be using and the features (or fields) and their relationships. There is comprehensive documentation on how to prepare your data for machine learning here, and I’d also recommend the Analytics and Data Science course we run for some helpful tips and techniques, too!
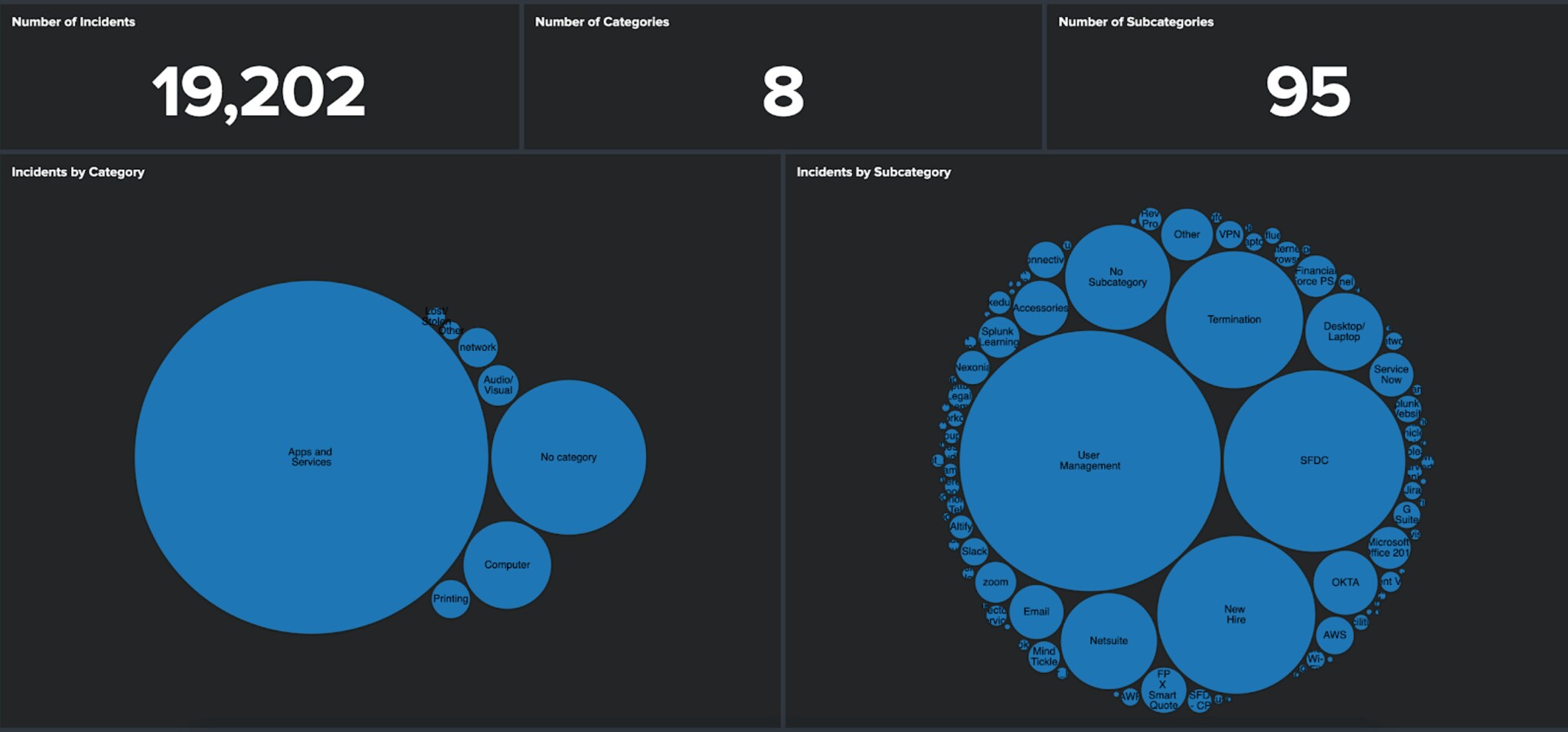
Once you understand a bit about your data, then you can apply some methods and analytics to the data to see if you can prove your theory. This is fairly easy to achieve in the MLTK experiments, which will also provide you with the SPL needed for the model development. You may want to refer to this blog about techniques for pre-processing your data, which contains lots of useful hints about preparing data for processing by a model-generating algorithm.
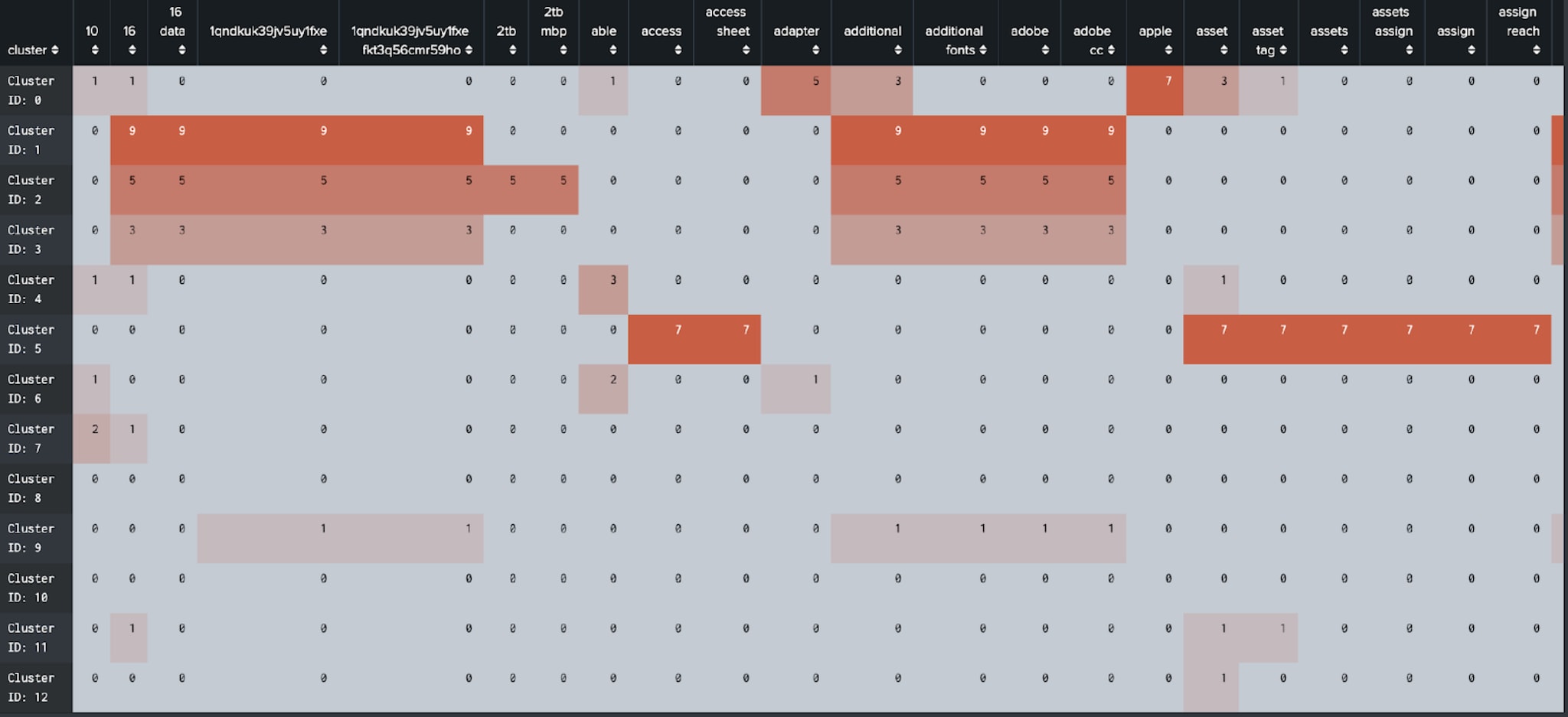
Provided you are able to prove your hypothesis, it’s then a case of considering what the process would look like for making the analytics repeatable for other users or data sources. Often this entails sourcing the data, moving to EDA, then pre-processing, then model development and testing before finishing with something that allows you to manage the models. (Disclaimer: you may need little bits of JavaScript to help users navigate between stages and manage some of the more complex searches…)

We will be announcing more details about these smart workflows and other enhancements we are making to ML at Splunk at .conf20 this year, so be sure to join us for that! Also, stay tuned for further smart workflows to be released, and read on to find out more details about the Smart Ticket Insights app for Splunk and the Smart Education Insights app for Splunk.

The Splunk platform removes the barriers between data and action, empowering observability, IT and security teams to ensure their organizations are secure, resilient and innovative.
Founded in 2003, Splunk is a global company — with over 7,500 employees, Splunkers have received over 1,020 patents to date and availability in 21 regions around the world — and offers an open, extensible data platform that supports shared data across any environment so that all teams in an organization can get end-to-end visibility, with context, for every interaction and business process. Build a strong data foundation with Splunk.

Get the latest articles from Splunk straight to your inbox.
© 2005 - 2024 Splunk Inc. All rights reserved.
