
Digital Resilience Pays Off
Download this e-book to learn about the role of Digital Resilience across enterprises.
Have you always wanted to paint pictures with your data? Do you strive to accelerate your data science cycles and rapidly iterate by running your analytics on GPUs? Or do you just like Spark and want to work with your favorite MLlib algorithms? Lucky for you, we have each of these bases covered in the latest version of Deep Learning Toolkit for Splunk (DLTK). Let’s dive straight into the new content and features available to use for your data challenges today!
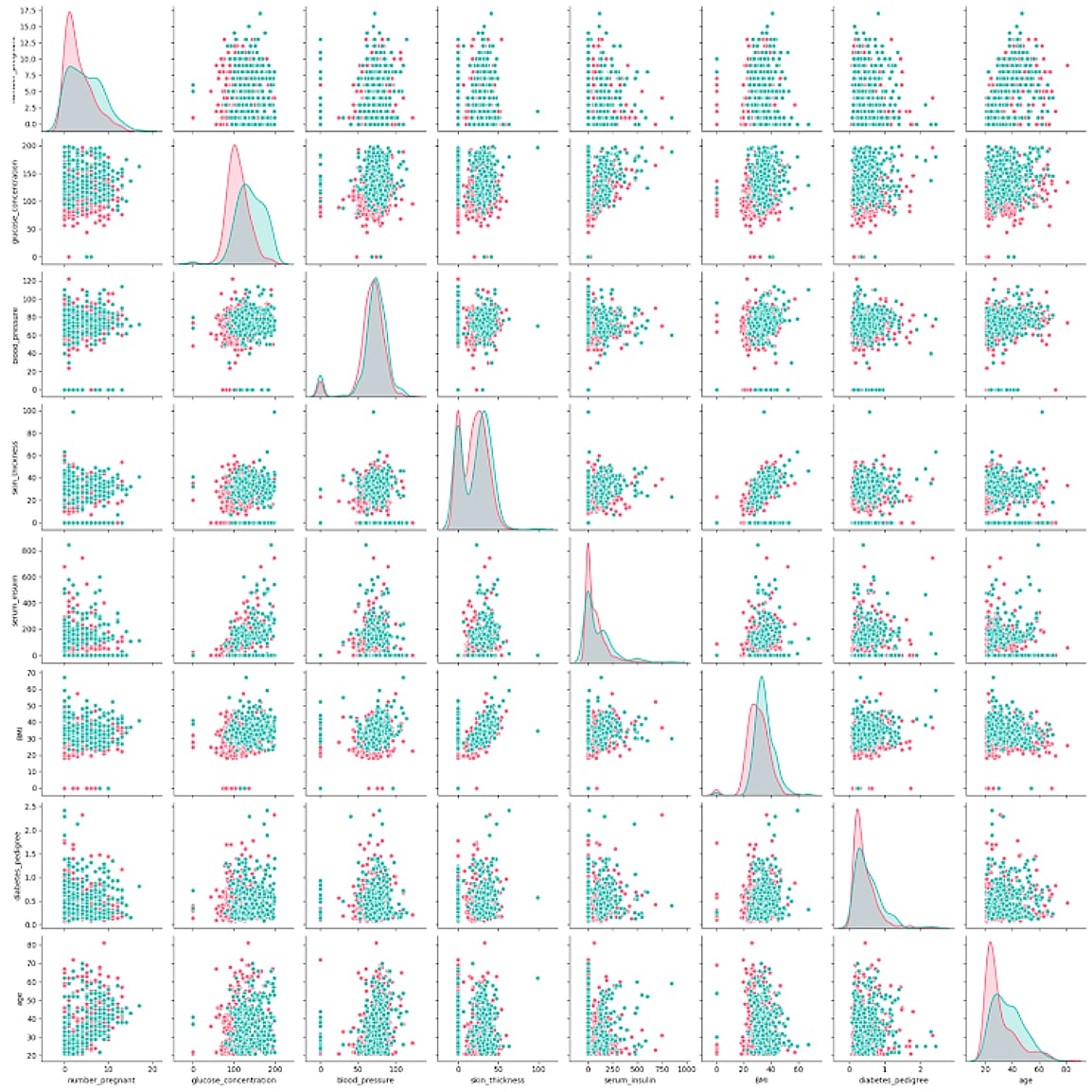
We all like Splunk dashboards and their visualizations. When trying to visualize larger datasets, I’m pretty sure some of you may have run into the infamous display limit of 10.000. For many use cases, especially for exploratory data analysis, it can be very helpful to plot many more data points. Here is where frameworks such as seaborn or datashader can be useful. Also, you most likely want to start with a simple correlation matrix or pair plot and integrate it on a Splunk dashboard:
Every container model in DLTK can provide a graphics summary that enables you to display useful information about your specific model back on a dashboard. But wait, that’s still just a few hundred points plotted. Let’s do a bit more.
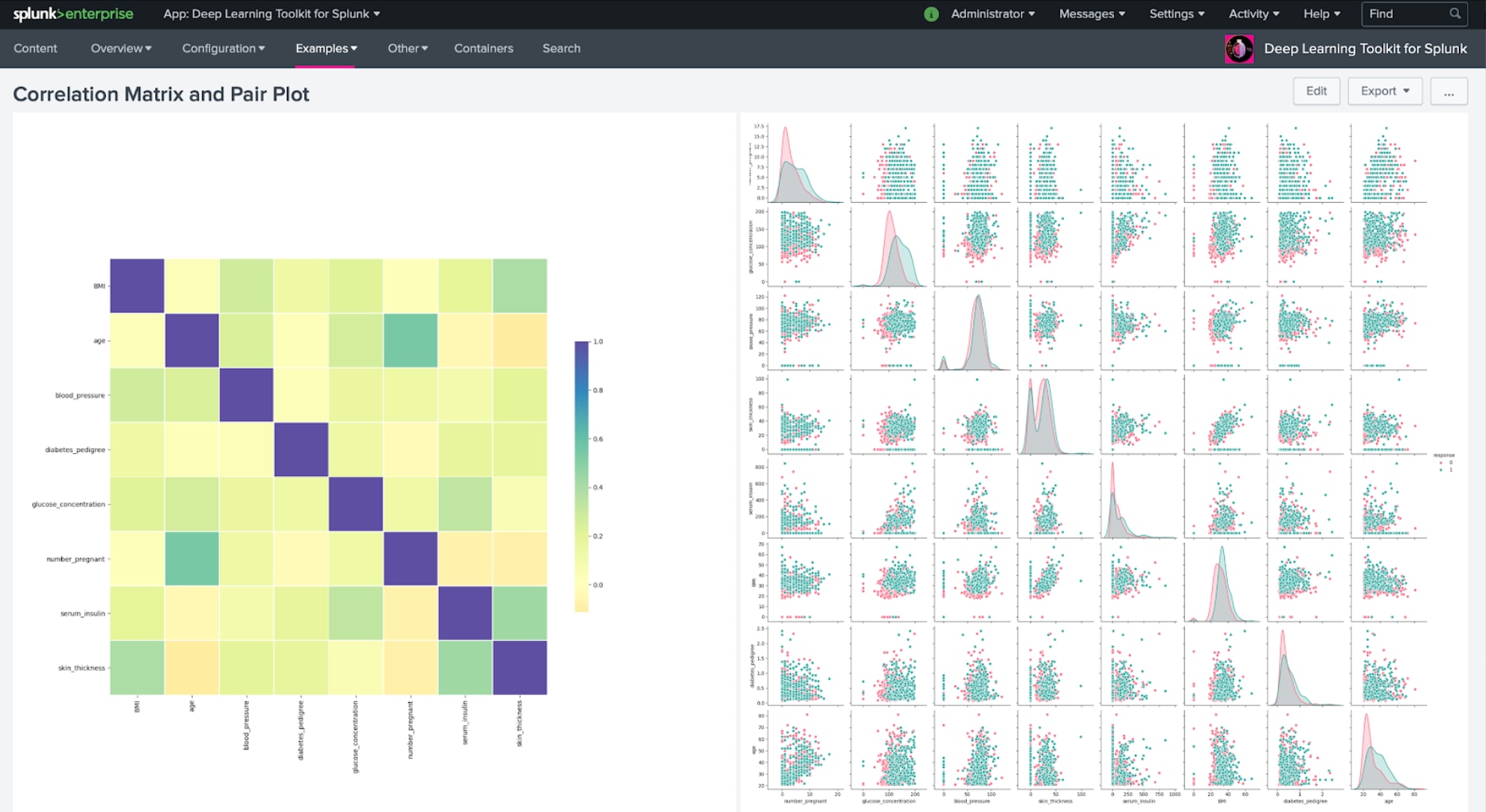
How about applying a dimensionality reduction technique like UMAP on a 1.7M dataset and rendering a data shader-based visualization from it? This is where GPU accelerated frameworks like Rapids can provide a big advantage. The following example shows the dataset from the DGA App being analyzed on a Rapids GPU container, off-screen rendered with Datashader, and displayed back into Splunk. You can experience 15x speedups for the UMAP calculation part alone, comparing Rapids to a CPU based implementation.
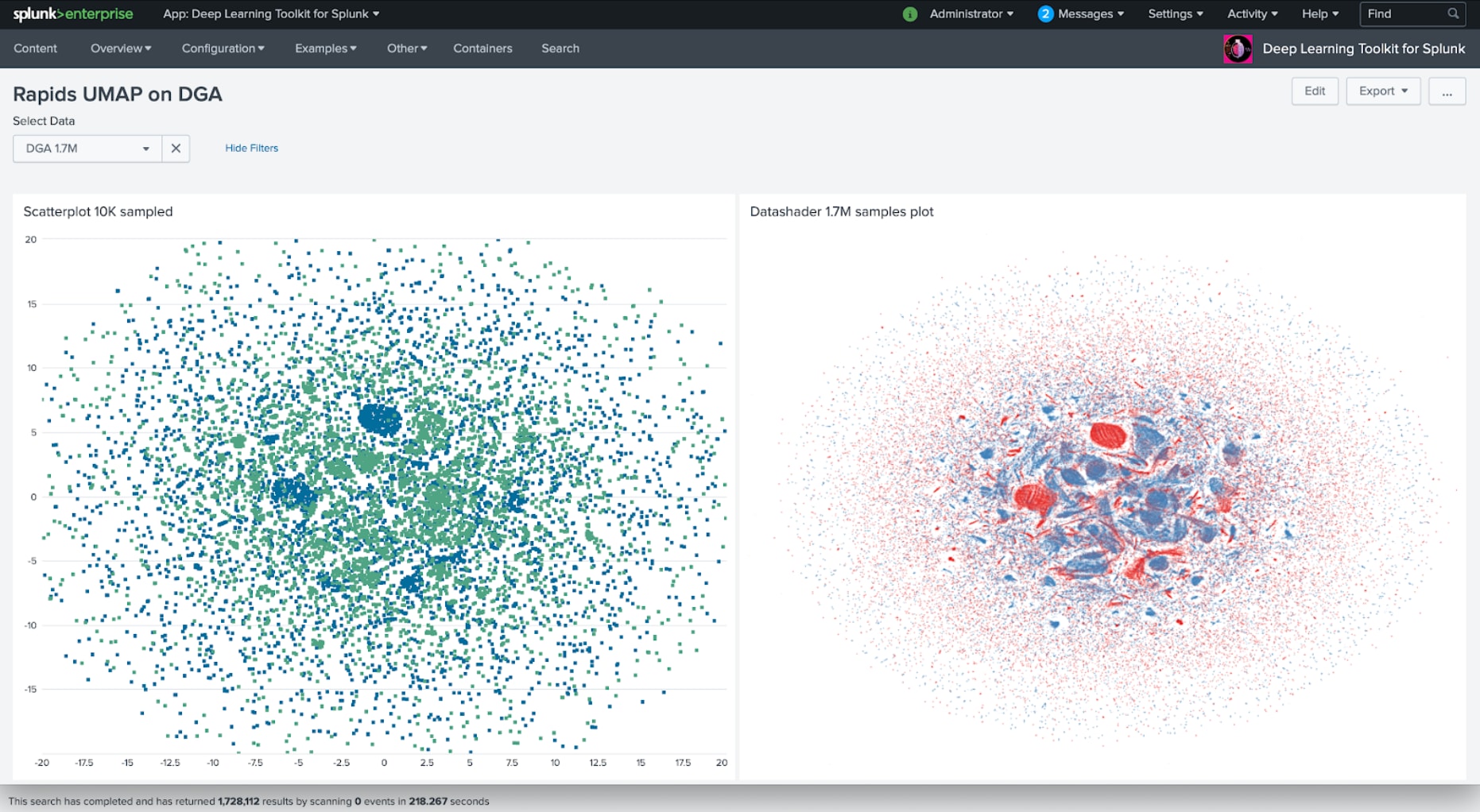
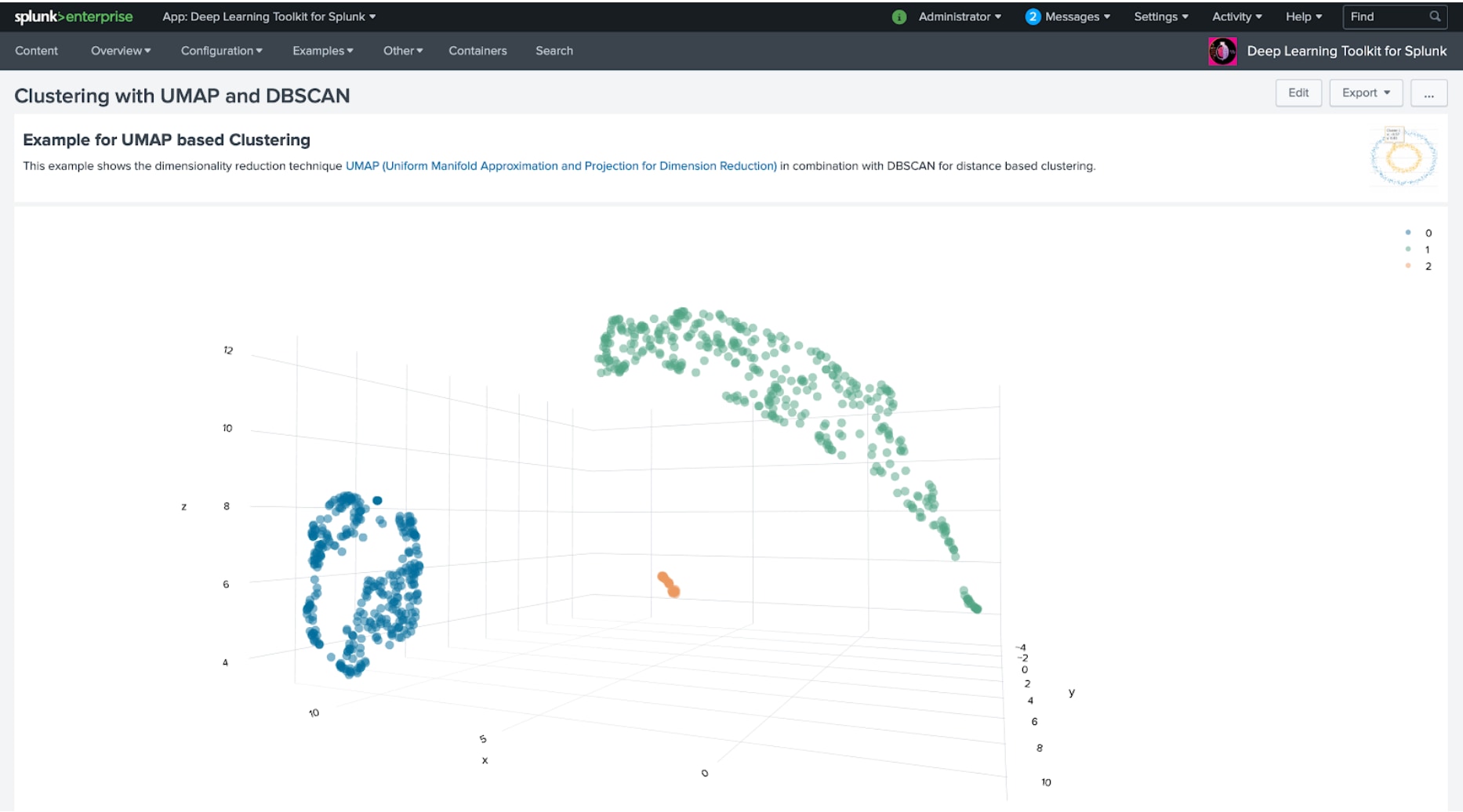
The results of UMAP can easily be combined with clustering techniques to detect structures in a dataset. Of course, you would need to be careful and avoid misinterpreting such structures and evaluate them within the context of your analysis. Due to this, the ability to quickly iterate over the results of such workflow is saving the precious time needed to produce high-quality results. The following dashboard shows the results of such a combined analysis with UMAP and MLTK’s DBSCAN:
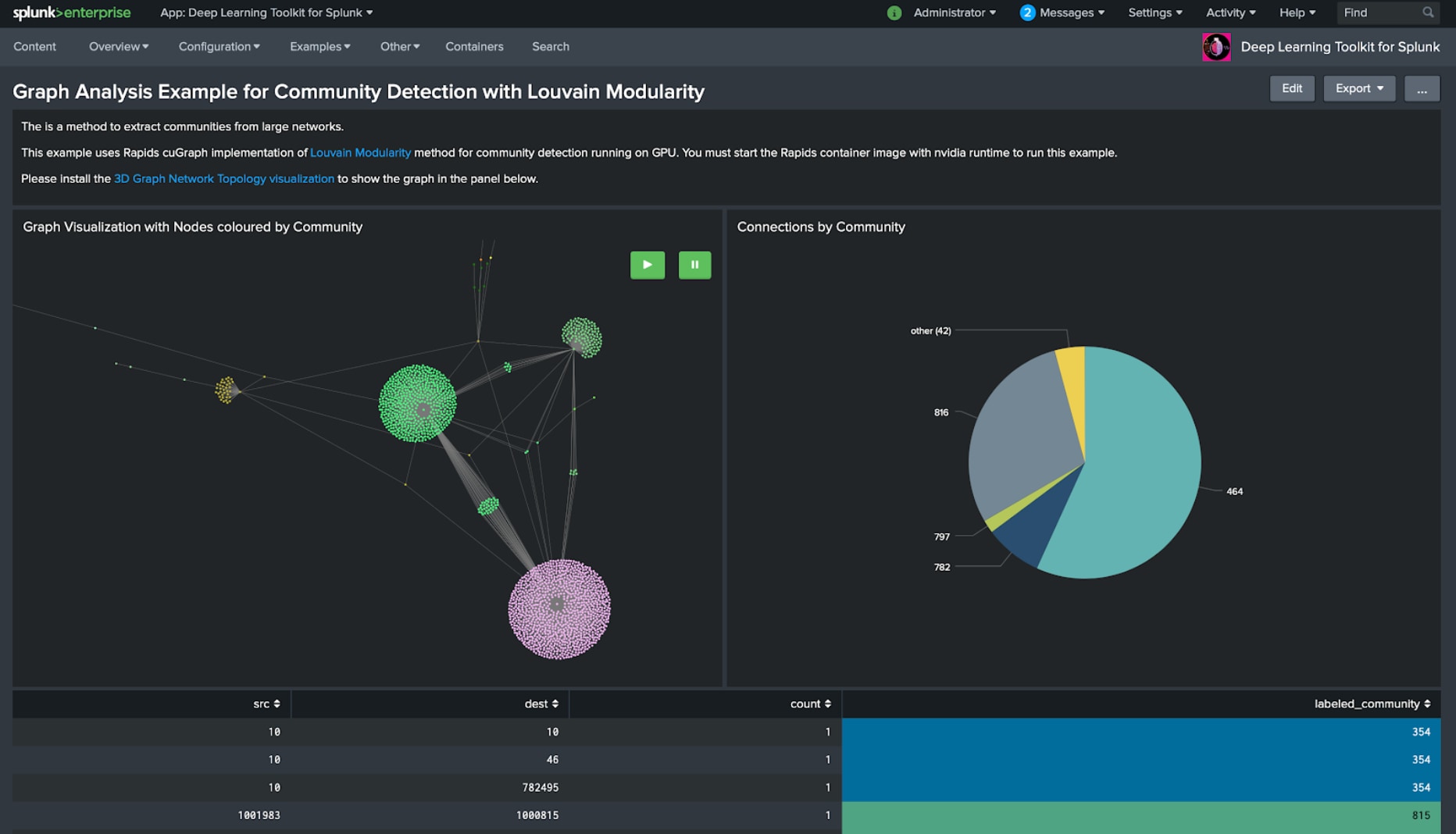
And of course, there is still so much more you can do with Rapids, for example GPU accelerated graph analytics with cuGraph. You might have read my last blog post about graph analysis and installed the 3D Graph Network Topology Visualization. However, you can easily reach computational limits when running on larger graphs. But you’re in luck when your graph fits in GPU memory: The following example applies the Louvain Modularity method to detect communities in a graph with 100000 edges and gets computed within 66.6ms (excluding data transfers).
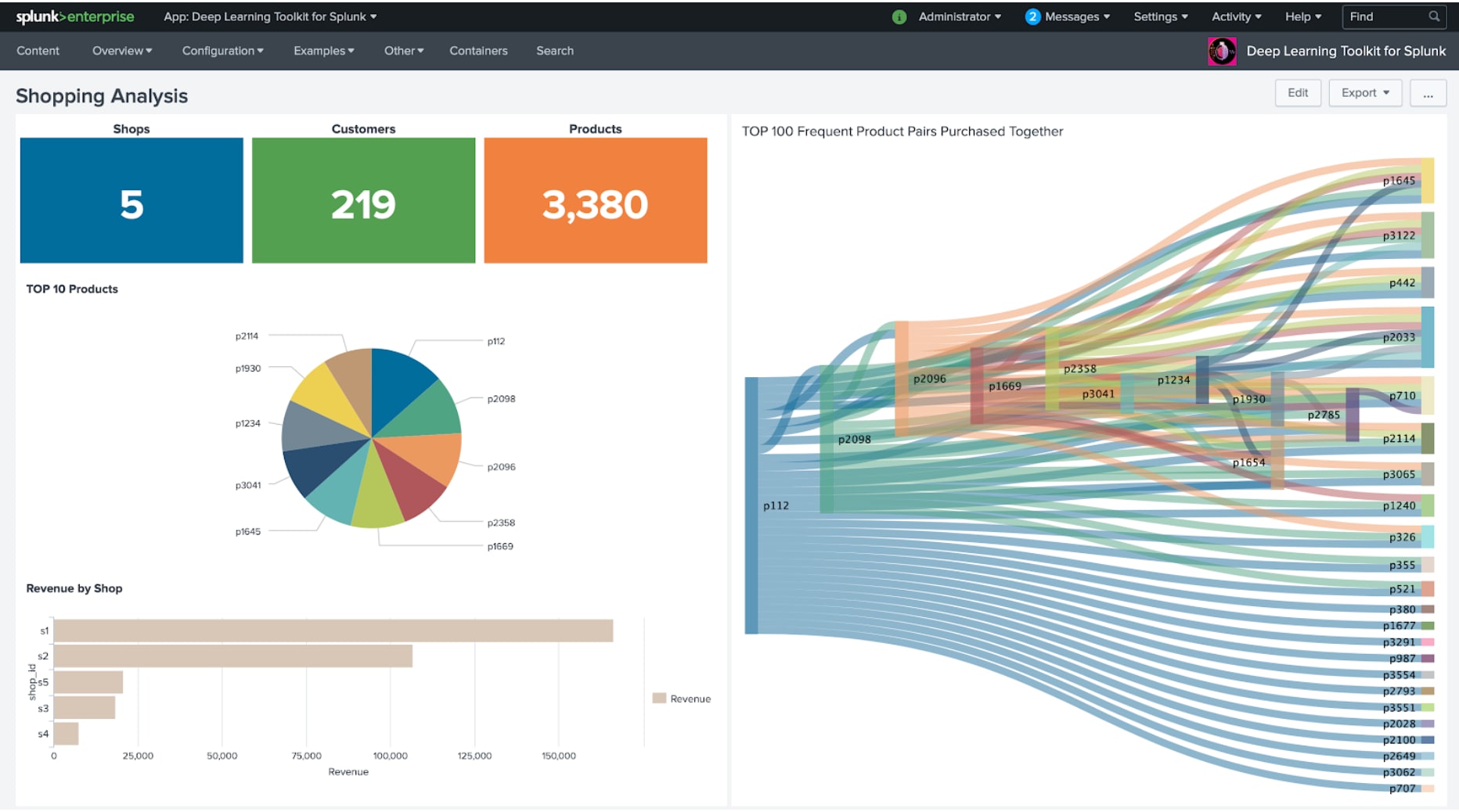
When it comes to distributed computing and machine learning, Spark is a well-known framework for many data scientists out there. Spark’s MLlib offers a rich set of algorithms that can bring lots of value to various business questions. The first example below shows a simple shopping analysis dashboard. It offloads the typical basket analysis problem to a Spark container that computes frequent itemsets with FP Growth and displays the results back on the dashboard in a Sankey chart:
A second interesting use case is around recommendation systems. The typical question here is: “Based on other people’s preferences, what would be a good fit for you, based on the items you like?” The following dashboard example shows in its upper part how a collaborative filtering model is trained in Spark and in the bottom result table how it can be interactively applied to a selected customer and get the top 10 recommended products. Of course, recommendations are not only useful in shopping or e-commerce but any other scenarios where the “wisdom of the crowd” may be learned and used to give smart new ideas.
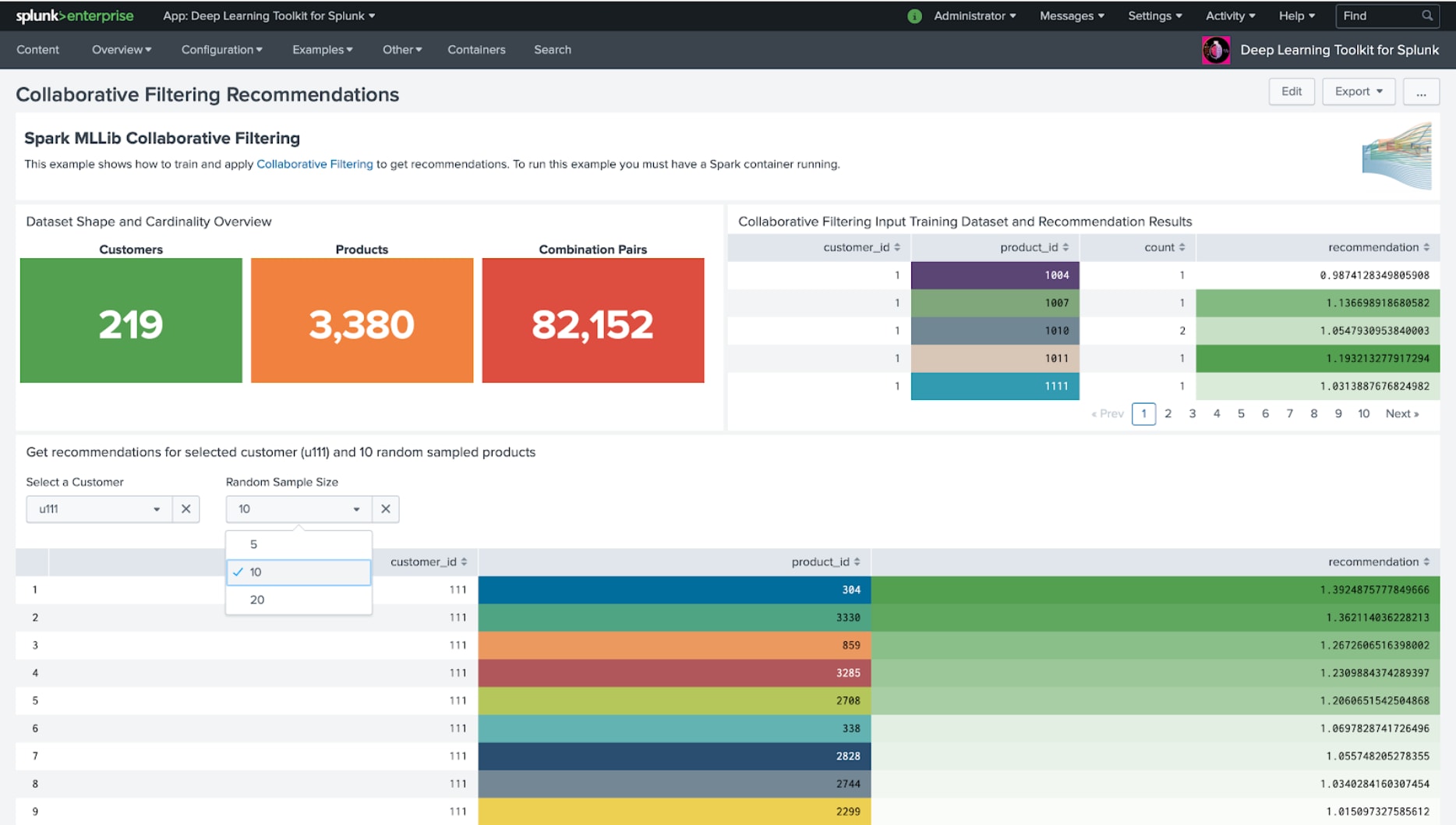
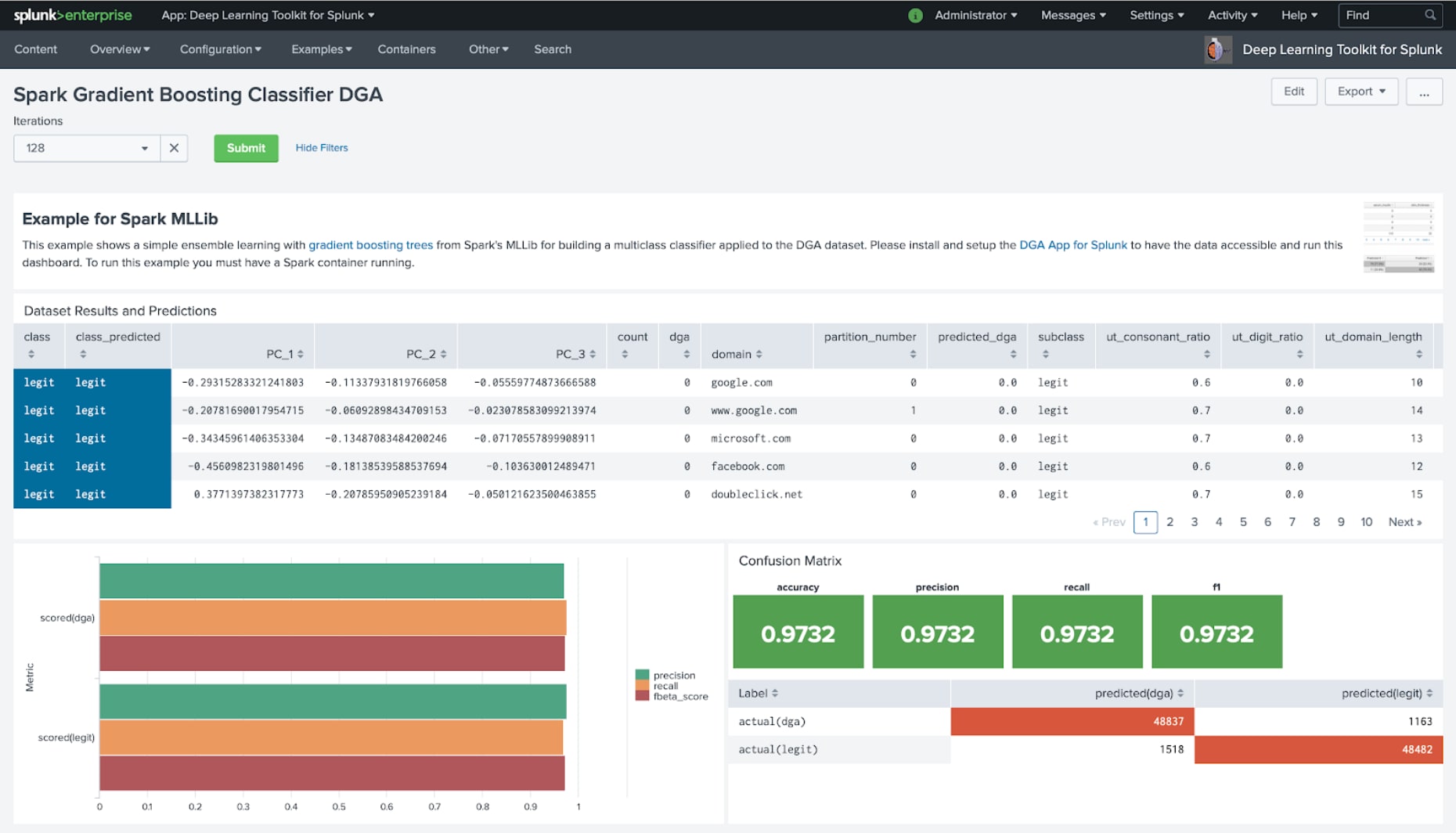
As you can see from this dashboard it is quite easy to set up a basic recommendation system that you can further modify and adapt to your use case. Another Spark example shows how you can use MLlib’s Gradient Boosting Classifier and apply it to the classification use case of the DGA App for Splunk and its data to compare how this algorithm performs:
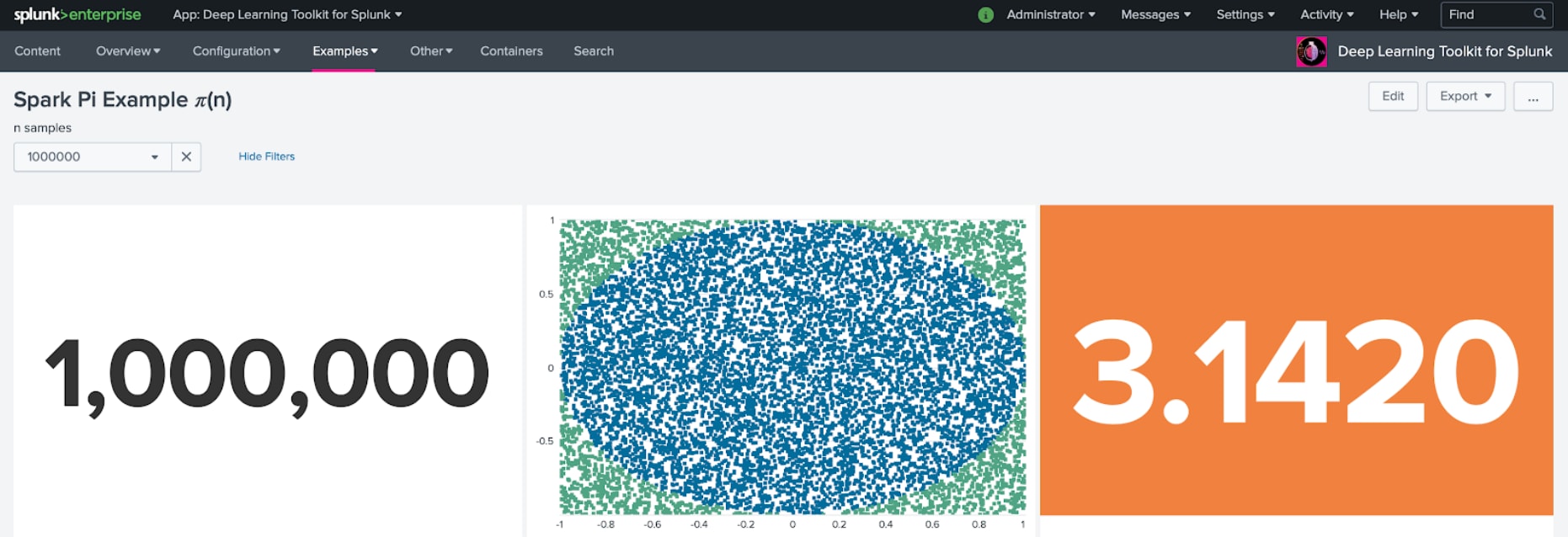
And lastly, of course, you can also try to compute Pi with Spark, which may be a well-known entry point for your “Hello World” in Spark. However, I still wonder why people would melt their CPU cores just for another digit behind the comma? But hey, who said computing can’t be fun?
Happy Splunking,
Philipp

The Splunk platform removes the barriers between data and action, empowering observability, IT and security teams to ensure their organizations are secure, resilient and innovative.
Founded in 2003, Splunk is a global company — with over 7,500 employees, Splunkers have received over 1,020 patents to date and availability in 21 regions around the world — and offers an open, extensible data platform that supports shared data across any environment so that all teams in an organization can get end-to-end visibility, with context, for every interaction and business process. Build a strong data foundation with Splunk.

Get the latest articles from Splunk straight to your inbox.
© 2005 - 2024 Splunk Inc. All rights reserved.
