
Digital Resilience Pays Off
Download this e-book to learn about the role of Digital Resilience across enterprises.
In part 1 of this release blog series we introduced the latest version of the Deep Learning Toolkit 3.1 which enables you to connect to Kubernetes and OpenShift. On top of that a brand new “golden image” is available on docker hub to support even more interesting algorithms from the world of machine learning and deep learning! Over the past few months, our customers’ data scientists have asked for various new algorithms and use cases they wanted to tackle with DLTK. The four new examples below are a subset of those and should also be helpful starting points for others.
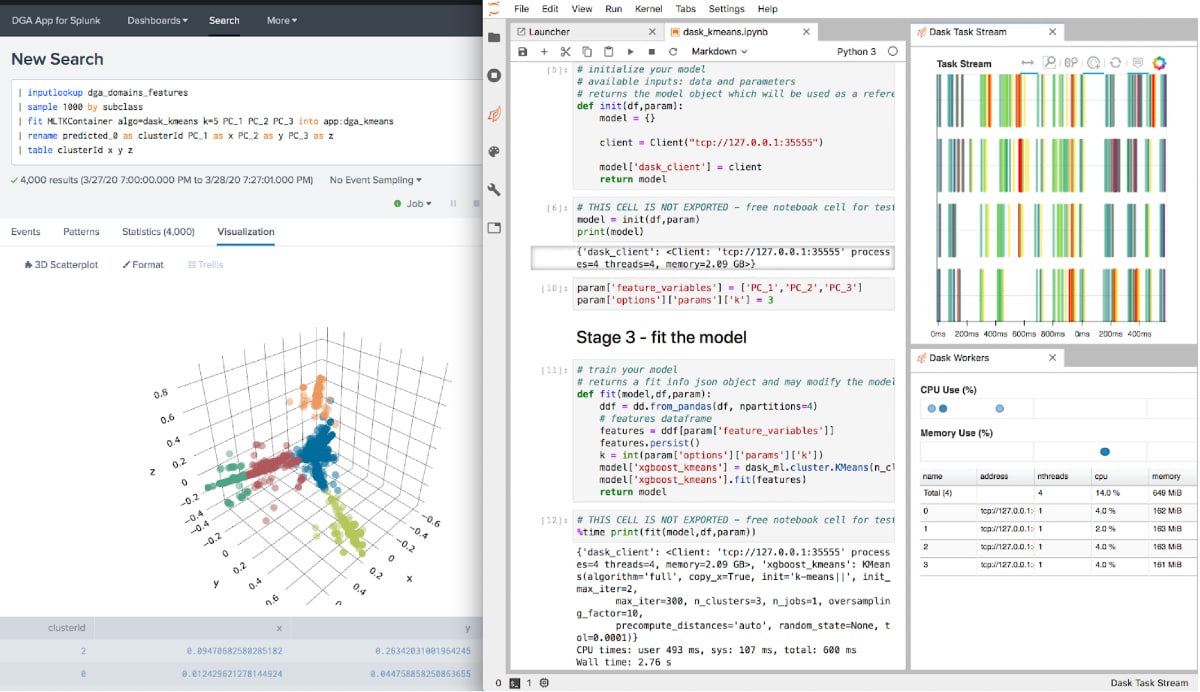
Machine learning workloads can easily consume more compute time, especially when it comes to larger or more complex datasets. It’s no secret that distributing such workloads helps speed up training times or tasks like hyperparameter search. In the Python ecosystem, DASK provides advanced parallelism for analytics, enabling performance at scale. Dask also provides some distributed machine learning algorithms via Dask-ML. The example below shows how a parallel implementation of K-Means can be easily integrated into Splunk using the Deep Learning Toolkit and developed and monitored in Jupyter Lab.
When you connect the Deep Learning Toolkit to a GPU enabled Docker or Kubernetes environment, you can accelerate model training significantly. Benchmarking the dataset from the DGA App for Splunk, we achieved a speedup of over 40x when we ran the example neural network classifier on a GPU compared to the CPU baseline. To put this into perspective: a training job that took over 30 minutes on CPU was cut down to a total of 45 seconds including data transfer overhead on a GPU. That’s pretty useful for much more agile data science iterations and accelerating model creations.
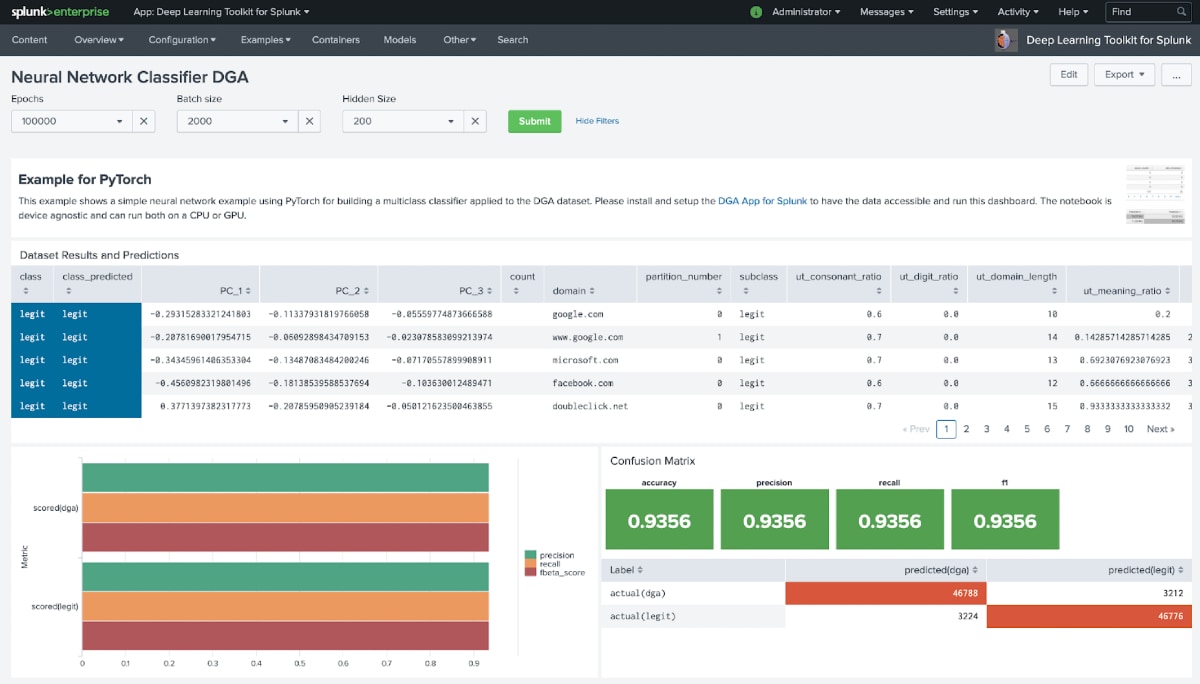
Luckily, PyTorch easily allows you to write device-agnostic code that runs both on CPU and GPU using the .to(device) magic with minimal impact on your model code. We have added examples that show this functionality for a simple multiclass neural network classifier to get you started quickly.
Built by Facebook’s Core Data Science team, Prophet is a library for forecasting time series data based on an additive model where non-linear trends are fit with annual, weekly, and daily seasonality, plus holiday effects. It works best with time series that have strong seasonal effects and several seasons of historical data. Prophet is robust to missing data and shifts in the trend and typically handles outliers well.
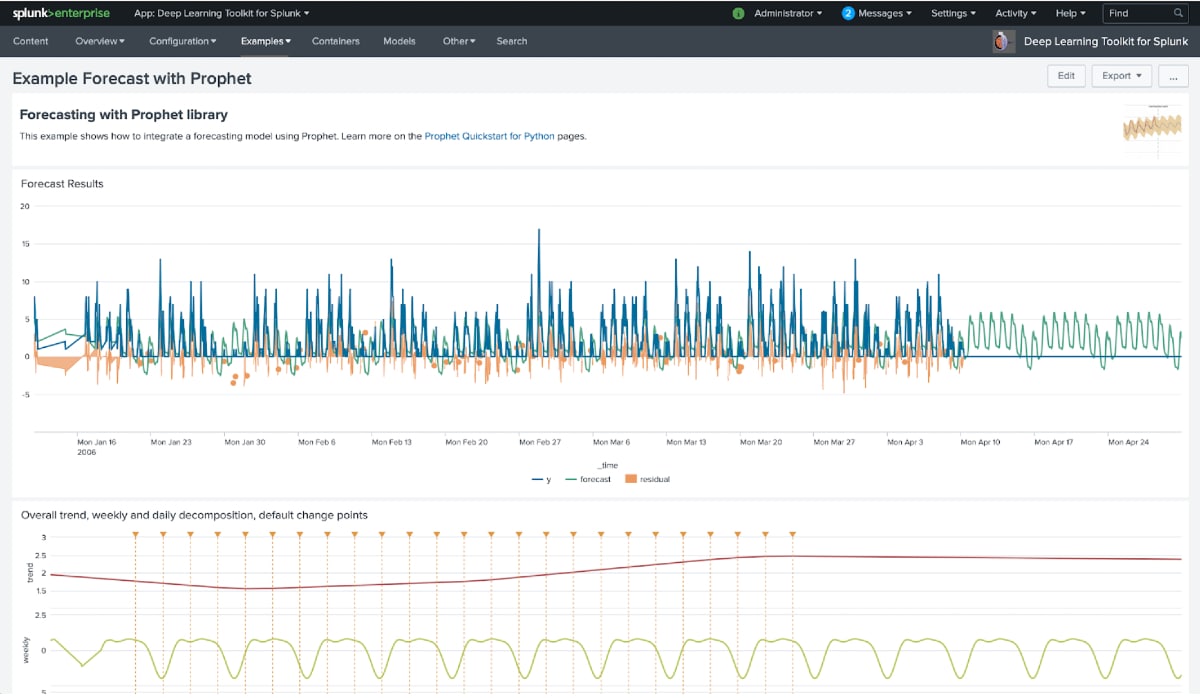
Despite the fact that the forecast (green line) on the dashboard above is far from perfect, it can definitely serve as an example to get started quickly with experimentation. However, it also clearly shows that not every time series dataset is perfectly suited for Prophet, so don’t forget to check other robust forecasting methods like the StateSpaceForecast in Splunk’s Machine Learning Toolkit, which can be easily applied with the Smart Forecasting Assistant.
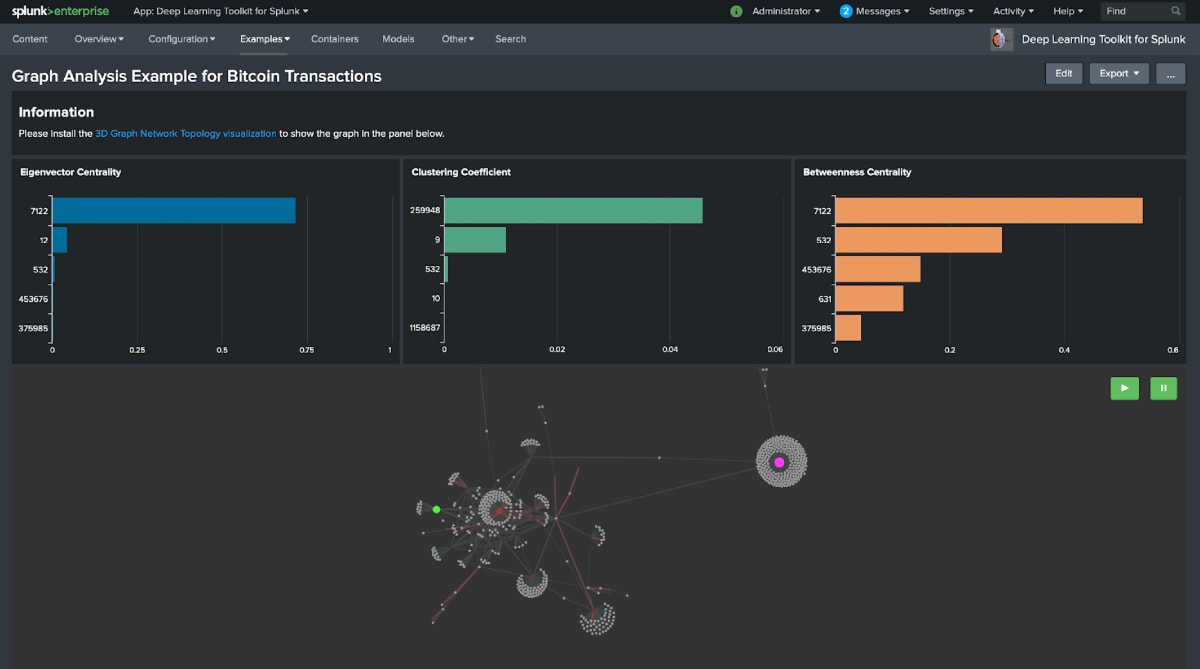
You may have read about the latest possibilities for graph analytics in Splunk using the freely available 3D Graph Network Topology Visualization app from splunkbase. My colleague Greg recently published two articles on how those techniques can be used for understanding and baselining network behavior.
If it comes down to quickly developing code or experimenting with graph models, the graph analysis example in Deep Learning Toolkit 3.1 should help you get started quickly and explore more advanced modelling techniques with graphs.
Recently a DLTK user in Japan built an extension to be able to apply the Ginza NLP library on Japanese Language text and to make the NLP example work for Japanese. Luckily we were able to get his contribution merged into the DLTK 3.1 release. I’m really happy to see this community mindset and I want to thank you, Toru Suzuki-san for your contribution, ありがとうございました!
Last but not least I would like to thank so many colleagues and contributors who have helped me finish this release. A special thanks again to Anthony, Greg, Pierre and especially Robert for his continued support on DLTK and making Kubernetes a reality today!
With the upcoming .conf20 and the recently opened 'Call For Papers' I want to encourage you to submit your amazing machine learning or deep learning use cases by May 20. Let me know in case you have any questions!
Happy Splunking,
Philipp

The Splunk platform removes the barriers between data and action, empowering observability, IT and security teams to ensure their organizations are secure, resilient and innovative.
Founded in 2003, Splunk is a global company — with over 7,500 employees, Splunkers have received over 1,020 patents to date and availability in 21 regions around the world — and offers an open, extensible data platform that supports shared data across any environment so that all teams in an organization can get end-to-end visibility, with context, for every interaction and business process. Build a strong data foundation with Splunk.

Get the latest articles from Splunk straight to your inbox.
© 2005 - 2024 Splunk Inc. All rights reserved.
