
Digital Resilience Pays Off
Download this e-book to learn about the role of Digital Resilience across enterprises.

In sync with the upcoming release of Splunk’s Machine Learning Toolkit 5.2, we have launched a new release of the Deep Learning Toolkit for Splunk (DLTK) along with a brand new “golden” container image. This includes a few new and exciting algorithm examples which I will cover in part 2 of this blog post series. Examples include forecasting with Prophet, graph analysis with NetworkX, distributed machine learning with DASK and a new hybrid CPU/GPU example for PyTorch and a very recent contribution from the Splunk community for a NLP library for Japanese.
Up until DLTK version 3.0 we’ve only had Docker as a target environment to run containers for advanced machine learning and deep learning use cases. It was useful at the beginning and still is for local development, but now many enterprise customers want to connect to their Openshift or Kubernetes stack, either on-prem or in the cloud.
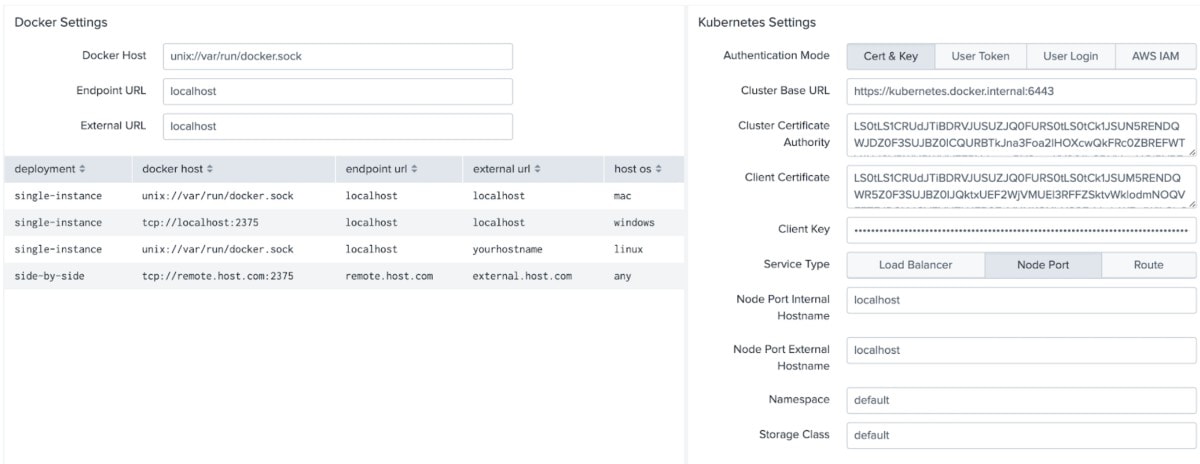
The latest version 3.1 spells good news for those deployment scenarios as the Deep Learning Toolkit now allows you to connect to Kubernetes and OpenShift with a series of authentication options. We’ll organise them in an overview matrix to better illustrate all options at a glance:
| Splunk> | Docker | Kubernetes | Openshift |
| Authentication Options | Docker Client Standard | Certificate & Key, User Token, Username & Password, AWS IAM | Certificate & Key, User Token, Username & Password, AWS |
| Ingress Type | Docker Networking Standard | Load Balancer, Node Port | Route |
| Cluster Connection Examples | unix://var/run/docker.sock, tcp://remotehost:2375 | https://ec2-xx-xx-xxx-xxx.compute-1.amazonaws.com:16443 | https://dltk.openshift.my |
With the new setup options you can even connect to both, Docker and Kubernetes/Openshift in parallel. This can be handy for situations where developing in a local Docker environment is needed to then move over to Kubernetes for putting models into production. In any case, please make sure your setup of DLTK is appropriately secure as it involves network communication between your Splunk search head and your container environment.
As you may have read in Anthony’s blog post, you can easily build your own custom container images for DLTK using the bits from Github. Conveniently, you can simply pull the existing, prebuilt images from Dockerhub to work with frameworks like TensorFlow, PyTorch or NLP libraries. However, you might ask: “Why are there 4 different images?” And you are right, there should be a much simpler way which we will now follow by introducing the new “Golden Image GPU (3.1)”.
To improve security, this image was further modified to run model code as non-root user in the container which is a must have for most production deployments. All libraries and frameworks have been updated to the most current stable versions and consolidated into a unified image that now supports both CPU and GPU execution. On top of that, Jupyter Lab has added extensions to run TensorBoard and DASK directly as widgets in its UI interface.
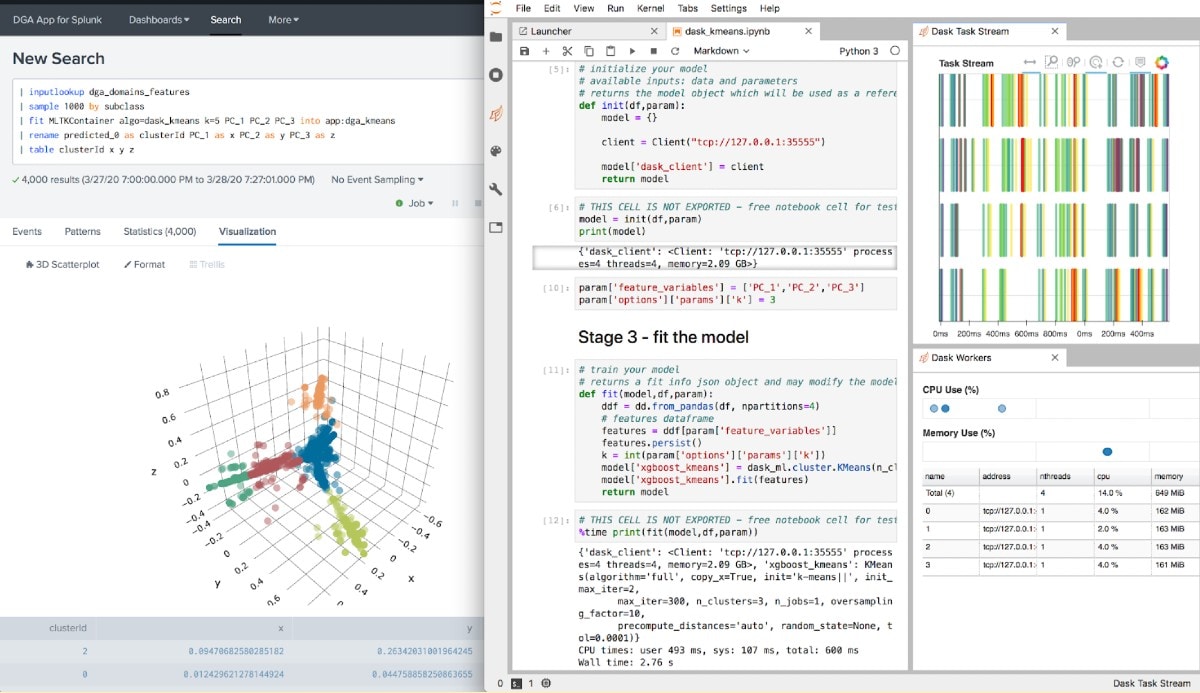
With the upcoming .conf20 and the recently opened 'Call For Papers', I want to encourage you to submit your amazing machine learning or deep learning use cases by May 20. Let me know in case you have any questions or need support.
Last but not least I would like to thank all colleagues and contributors who helped me a lot to finish this release. Special thanks to Robert Fujara for his continued support on DLTK and making Kubernetes a reality today!
Read about all the exciting new examples in part 2 of this blog post.
Happy Splunking,
Philipp

The Splunk platform removes the barriers between data and action, empowering observability, IT and security teams to ensure their organizations are secure, resilient and innovative.
Founded in 2003, Splunk is a global company — with over 7,500 employees, Splunkers have received over 1,020 patents to date and availability in 21 regions around the world — and offers an open, extensible data platform that supports shared data across any environment so that all teams in an organization can get end-to-end visibility, with context, for every interaction and business process. Build a strong data foundation with Splunk.

Get the latest articles from Splunk straight to your inbox.
© 2005 - 2024 Splunk Inc. All rights reserved.
