
Digital Resilience Pays Off
Download this e-book to learn about the role of Digital Resilience across enterprises.

There are some streaming use cases where you want to store the data in the stream for a very long time. While Apache Pulsar places no limit on the size of a topic backlog, storing all your data in Pulsar can get expensive after a while. This blog post introduces the Tiered Storage feature of Apache Pulsar, available in version 2.1, which allows older data to be moved to long term storage, with zero impact to the end-user.
Recommendation services are one instance of a use-case where you don’t want a limit on size of your backlog. Take the example of a music service. Each time a user listens to a song, a message is added to a topic. This topic is fed into a recommendation algorithm to find new music that the user may like based on what they have listened to in the past. These recommendations are then served to the user, and the cycle continues.
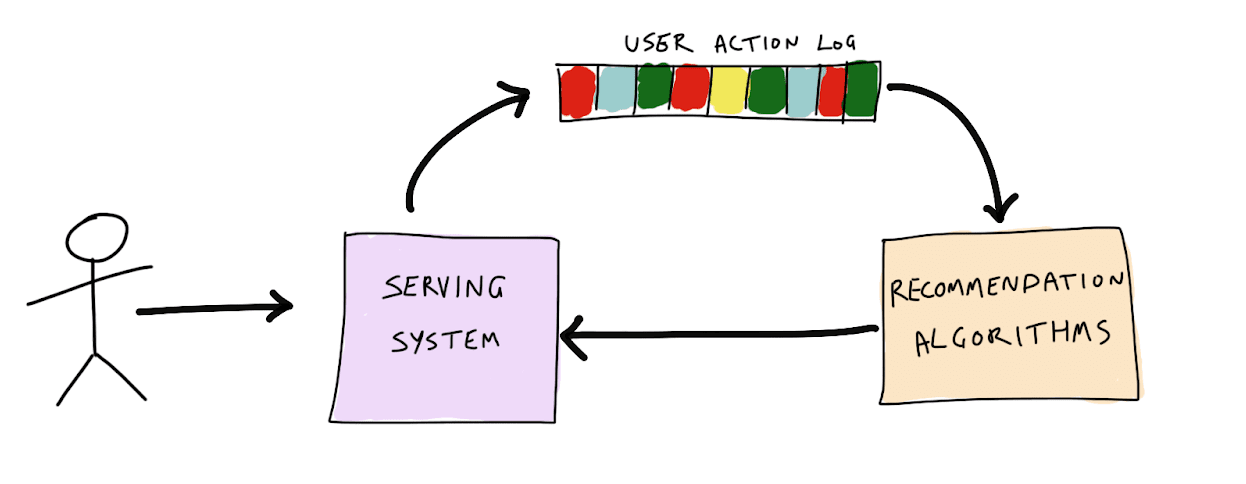
Figure 1. Recommendation engine illustration
Of course, the recommendation algorithm is not static. The music service’s data scientist are constantly tweaking it to try to better predict what music the user will like, thereby increasing the user’s satisfaction and engagement with the service.
However, if each time the algorithm was modified it only ran against the user data from that point in time onward, the predictions would not be very accurate and it would take a long time to figure out if the change to the algorithm was a good one or not. To get a better picture, the algorithm needs to run against as much historical user data as possible.
Fortunately, with Pulsar you can store a topic backlog as large as you want. When the cluster starts to run out of space, you just add another storage node, and the system will automatically rebalance the data. Unfortunately, this can start to get expensive after a while.
Pulsar mitigates this cost/size trade-off by providing Tiered Storage, a feature first available with Apache Pulsar 2.1. With Tiered Storage you can allow your backlog to grow very large without having to add storage nodes; older topic data is offloaded to long term storage, which is generally an order of magnitude cheaper than the storage in the Pulsar cluster itself. To the end user there is no perceivable difference between consuming a topic whose data is stored on the Pulsar cluster or on tiered storage. They still produce and consume messages in exactly the same way.
Pulsar can do this because of its segment oriented architecture. The message log for a Pulsar topic is composed of a sequence of segments. The last segment in this sequence is the segment that Pulsar is currently writing to. All segments before the current sequence are sealed, which is to say, the data in these segment is immutable. Because the data is immutable, it can easily be copied to another storage system, without having to worried about consistency issues. Once the copy is complete, the pointer to the data can be updated in the message log metadata, and the copy of data stored by Pulsar in Apache BookKeeper can be deleted.
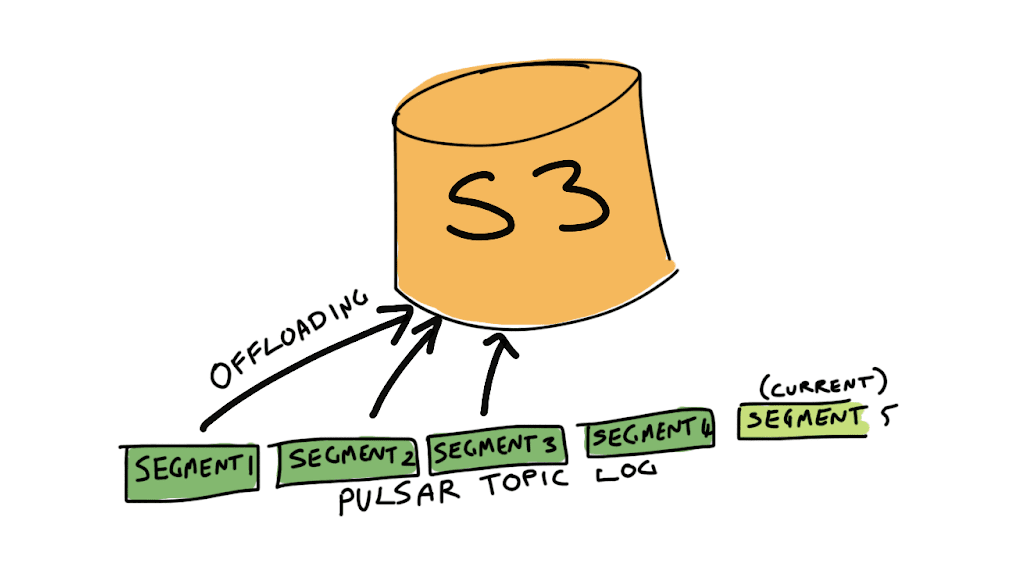
Figure 2. Offloading topic segments to cloud storage
Pulsar currently supports Amazon S3 for long term storage. To use S3 as tiered storage, the administrator must first create a bucket in S3. Then, each broker must be configured with the bucket and the region in which the bucket was created.
managedLedgerOffloadDriver=S3 s3ManagedLedgerOffloadRegion=eu-west-3 s3ManagedLedgerOffloadBucket=pulsar-topic-offload
Authentication is not configured directly in Pulsar. Instead, Pulsar uses the DefaultAWSCredentialsProviderChain, which looks for credentials in a number of places.
The simplest way to configure the credentials is to set environment variables in pulsar-env.sh.
The tiered storage documentation provides more information on how to configure the other authentication methods.
Once all brokers are configured, you can start using tiered storage.
The offloading of data to tiered storage can be configured to run automatically or it can be triggered manually.
A namespace administrator can set a size threshold policy on a namespace. With this policy, any topic in the namespace, whose data size on the Pulsar cluster exceeds the threshold, will have some segments offloaded to long term storage, until the size on the Pulsar cluster no longer exceeds the threshold.
For example, to specify that the topics in a namespace should offload segments if the data size on the Pulsar cluster exceeds 1 gigabyte, you would use the following command:
pulsar-admin namespaces set-offload-threshold --size 1G my-tenant/my-namespace
When any topic in the namespace then exceeds the threshold, data will be moved to long term storage and storage space will be freed up on the Pulsar cluster.
Offloading can also be triggered manually, on individual topics, through a REST interface, or CLI. To trigger via the cli, the user must specify the maximum amount of data that should be retained on the Pulsar cluster for that topic. If the size of topic’s data on the Pulsar cluster exceeds this threshold, segments from the topic will be moved to long term storage until the threshold is no longer exceeded. Older segments are moved first.
pulsar-admin topics offload --size-threshold 10M my-tenant/my-namespace/topic1
For more details on configuring and using tiered storage, check out the docs.
Tiered storage is available in Apache Pulsar 2.1 (incubating).
----------------------------------------------------
Thanks!
Ivan Kelly

The Splunk platform removes the barriers between data and action, empowering observability, IT and security teams to ensure their organizations are secure, resilient and innovative.
Founded in 2003, Splunk is a global company — with over 7,500 employees, Splunkers have received over 1,020 patents to date and availability in 21 regions around the world — and offers an open, extensible data platform that supports shared data across any environment so that all teams in an organization can get end-to-end visibility, with context, for every interaction and business process. Build a strong data foundation with Splunk.

Get the latest articles from Splunk straight to your inbox.
© 2005 - 2024 Splunk Inc. All rights reserved.
