
Digital Resilience Pays Off
Download this e-book to learn about the role of Digital Resilience across enterprises.

When I am talking about Apache Pulsar at conferences or discussing it in a smaller group, I am often asked what makes Pulsar different from existing messaging systems. There are a number of specific differences in capabilities and features that we’ve looked at previously in our blogs, such as unified queuing and streaming, multitenancy, resiliency and more, but far and away the most important difference is the Apache Pulsar architecture.
Architecture is the most fundamental design decision for a technology, and once implemented it is extremely difficult to change. Architecture is what differentiates and makes possible (or impossible) the most important capabilities of a technology, and that is certainly the case for Apache Pulsar.
In this blog I’ll look at Pulsar’s multi-layer architecture and explain how it is fundamental to making Pulsar ideal for the performance, scalability and availability requirements of streaming access patterns in ways that are not possible with existing messaging architectures.
From databases to messaging systems, most distributed data processing technologies have taken the approach of co-locating data processing and data storage on the same cluster nodes or instances. That design choice offered a simpler infrastructure and some possible performance benefits due to reducing transfer of data over the network, but at the cost of a lot of tradeoffs that impact scalability, resiliency, and operations.
Pulsar’s architecture takes a very different approach, one that’s starting to be seen in a number of “cloud-native” solutions and that is made possible in part by the significant improvements in network bandwidth that are commonplace today, namely separation of compute and storage. Pulsar’s architecture decouples data serving and data storage into separate layers: data serving is handled by stateless “broker” nodes, while data storage is handled by “bookie” nodes.

Figure 1. Single-layered vs Pulsar multi-layered architecture
That decoupling has many benefits. For one, it enables each layer to scale independently to provide infinite, elastic capacity. By leveraging the ability of elastic environments (such as cloud and containers) to automatically scale resources up and down, this architecture can dynamically adapt to traffic spikes. It also improves system availability and manageability by significantly reducing the complexity of cluster expansions and upgrades. Further, this design is container-friendly, making Pulsar the ideal technology for hosting a cloud native streaming system.
The architectural differences in Pulsar also extend to how Pulsar stores data. As described in detail in my blog on Pulsar’s segment-based architecture, Pulsar breaks topic partitions into segments and then stores those segments distributed across the “bookie” nodes in the storage layer to get better performance, scalability and availability. A topic partition becomes a logical concept, divided into multiple smaller segments and distributed and stored in the storage layer.
Next, let us dive deeper into the benefits of this architecture by looking at how it supports the common access patterns for streaming with better performance and resiliency than other architectures.
There are generally three I/O patterns in a streaming system:
Unlike most other messaging systems, in Pulsar each of these I/O patterns is isolated from the other patterns. In order to illustrate this point, I will compare and contrast how I/O occurs within Pulsar vs. how it occurs within other messaging systems whose monolithic architecture uses tightly coupled serving and storage layers, such as Apache Kafka.
In a monolithic system (the left-hand diagram in Figure 2 below), each broker can only utilize the storage capacity provided from local disk, which introduces several limitations:

Figure 2. Monolithic architecture compared to Pulsar multi-layered architecture
In contrast, within Apache Pulsar (the right-hand diagram in Figure 2 above), the data serving and data storage are decoupled, allowing any single Pulsar broker to access the ENTIRE capacity of the storage layer. The implications of this from a system availability perspective are profound. As long as there is a single Pulsar broker running, you will be able to read ANY data that was previously stored and also be able to continue writing data.
Now let's look at each pattern in more detail.
In a single-layered system, ownership of a given partition is assigned to one broker elected as the leader. That leader accepts writes and replicates the data to the other brokers. As shown on the left side of Figure 3 below, the data is written to the leader broker first and replicated to followers. That means that it takes two network round trips for data to be durably written.
In a multi-layer system, the data serving is done by stateless brokers, while the data is stored in a durable storage. The data will be sent to the broker who is serving the partition, and that broker will write data in parallel to the storage layer. Once the storage layer successfully writes the data and acknowledges the write, the broker caches the data in local memory for serving tailing reads (we will discuss in the following paragraph).

Figure 3. Comparison of write access pattern
As that demonstrates, a multi-layer architecture doesn’t introduce additional network hops or bandwidth on the write I/O path--both the monolithic architecture and the multi-layer architecture make two network round trips in parallel. However, the multi-layer architecture does significantly increase the flexibility and availability because of this separation.
In a single-layered architecture, consumers read the data from the leader, which reads the data from its local storage. In the Pulsar multi-layer architecture, consumers read the data from the serving broker, which already has that data cached in memory.

Figure 4. Comparison of tailing read access pattern
Note that in both cases, the read only requires on network trip to get the data. However, tailing read performance is better in the multi-layer system because tailing reads benefit from accessing data directly from the broker's in-memory cache, without needing to read from disk and without competing for resources with writes. Although not impossible for a monolithic architecture to implement an in-memory cache, reads and writes in that architecture are competing for resources (including memory) not only with each other but also with other processing tasks happening on the broker, making it difficult to implement such a cache and still scale.
It becomes more interesting when taking a look at catch-up reads. In a single-layer architecture, the access pattern is the same for both tailing reads and catch-up reads. All the catch-up reads are still sent to the leader broker, even when there are multiple followers, because of consistency concerns.
In Pulsar's multi-layer architecture, historic (old) data is stored in the storage layer. Catch-up reads go to the storage layer to read data in parallel, without competing or interfering with writes and tailing reads.
The most interesting part is when you put all of the different traffic patterns together, which is of course what happens in the real world. This is where the limitations of a single-layer architecture are the most painful. In that single-layer architecture, all the different workloads are sent to one central place and it is almost impossible to provide any performance isolation between workloads.
However in a multi-layer system, these I/O patterns can be easily isolated: the serving layer's in-memory cache of the latest data becomes an L1 cache of the canonical copy of data for serving up-to-date consumers, while the storage layer is the canonical storage of data for serving historical processing and analytics consumers.

Figure 5. Comparison of combined access pattern
This I/O isolation is one of the fundamental differences between a monolithic system and Pulsar, and is one of the key reasons that Pulsar can be used to replace multiple siloed systems.
We've focused on how Pulsar's multi-layer architecture is able to deliver performance and scalability for the different types of streaming workloads, but that's not all that this architecture makes possible. Here are a few of the ways in which this architecture enables Pulsar to go beyond just traditional streaming messaging.
This multi-layer architecture, with its decoupled storage layer, also makes it possible to use Pulsar as a stream storage system, providing a way to make both the most recent and historical data available to users and applications in a single system.
Because of Pulsar's segment-based architecture, a Pulsar topic does not have any size limit. The storage layer can be easily scaled by simply adding containers or nodes, without requiring rebalancing of data. When new nodes are added, they are immediately used for new segments or copies of new segments.
Also, Pulsar's decoupling of storage from processing makes it possible for Pulsar to use multiple tiers of storage to store data in a scalable and cost-efficient way. Apache Pulsar introduced this Tiered Storage feature in its 2.0 release. You can think of tiered storage as a “read-only” segment store. Older segments are offloaded from the writable segment store (i.e. BookKeeper) to read-only segment storage (e.g. cloud object storage) as they age out. In this way, Pulsar can fully leverage low-cost, scalable storage systems like cloud object storage. For more details about Tiered Storage, you can read the Pulsar documentation and our blog posts.
As a result, Pulsar can be a repository for not just current data but also for the full history of a stream of data.
The ability to act as a repository for the entire history of a stream of data makes it possible for users to run a wide array of data tools on their data. The Pulsar integration with Presto is a prime example of this as shown below. This integration allows the Presto SQL engine to connect directly to the data in the storage layer, enabling interactive SQL querying of data without interfering with other Pulsar workloads.
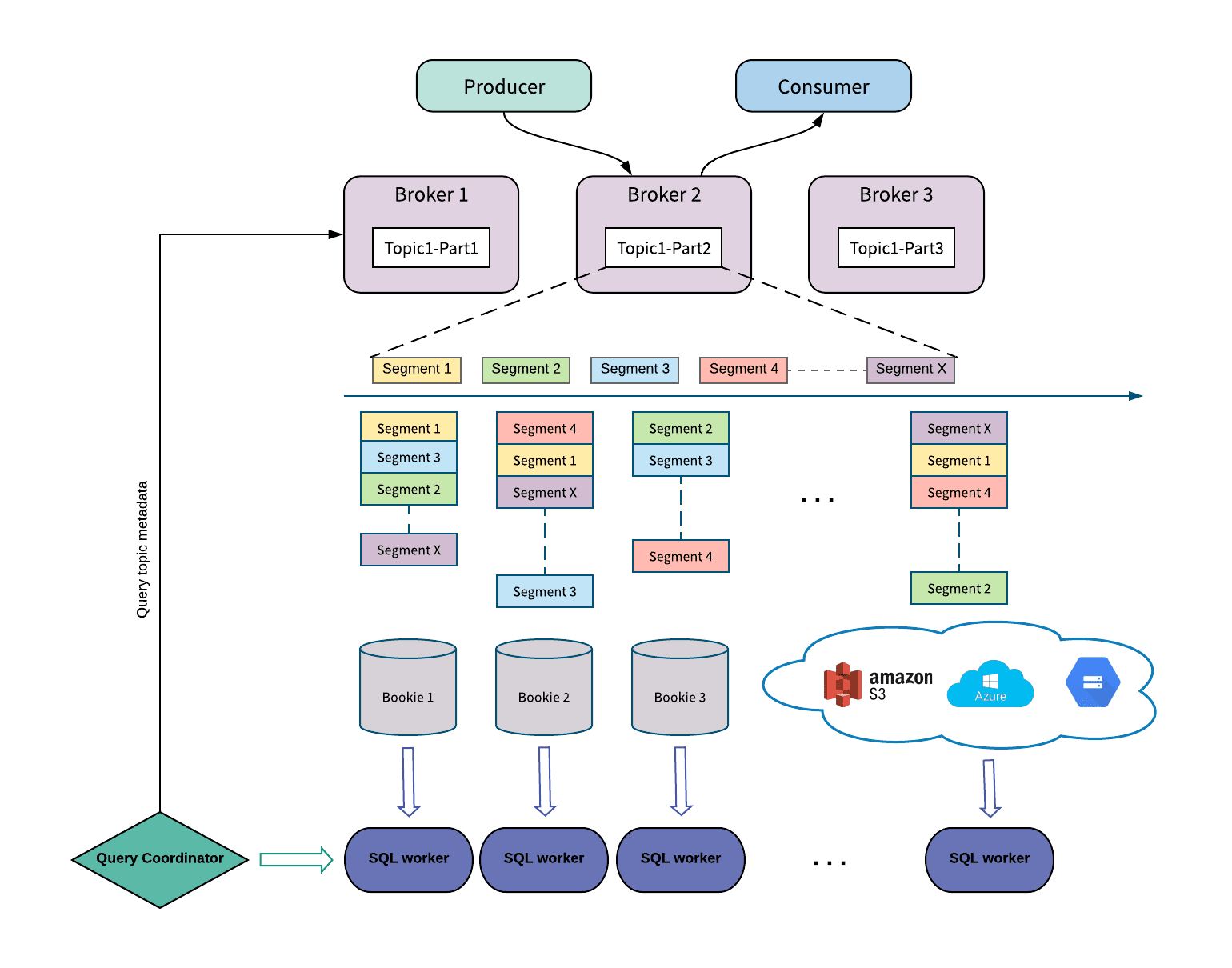
Figure 6. Presto integration with Apache Pulsar
Pulsar can also be integrated with other processing engines, such as Apache Spark or Apache Flink, to further expand the use cases for which Pulsar can play a role.
If you are interested in Pulsar and would like to learn more about its multi-layer, segment-centric architecture, feel free to reach out to us via email, slack or github. I am also giving a talk about using Apache Flink with Apache Pulsar at Flink Forward at Beijing on December 20. If you are attending Flink Forward Beijing, you are welcome to stop by our talk - “Unifying the Batch and Stream Elastic Processing with Apache Pulsar® and Apache Flink®”.
Thanks,
Sijie Guo

The Splunk platform removes the barriers between data and action, empowering observability, IT and security teams to ensure their organizations are secure, resilient and innovative.
Founded in 2003, Splunk is a global company — with over 7,500 employees, Splunkers have received over 1,020 patents to date and availability in 21 regions around the world — and offers an open, extensible data platform that supports shared data across any environment so that all teams in an organization can get end-to-end visibility, with context, for every interaction and business process. Build a strong data foundation with Splunk.

Get the latest articles from Splunk straight to your inbox.
© 2005 - 2024 Splunk Inc. All rights reserved.
