
Digital Resilience Pays Off
Download this e-book to learn about the role of Digital Resilience across enterprises.

Apache BookKeeper is an enterprise-grade storage system designed to provide strong durability guarantees, consistency, and low latency. It was originally developed at Yahoo! Research as a high availability (HA) solution for the Hadoop Distributed File System (HDFS) NameNode, which had previously been a highly problematic single point of failure in the system. BookKeeper was incubated as a subproject under Apache ZooKeeper since 2011 and graduated to being a Top-level Project in January, 2015. For over 4 years, BookKeeper has been widely adopted by enterprises like Twitter, Yahoo and Salesforce to store and serve mission-critical data and supporting different use cases. In this blog post, we provide a gentle introduction to concepts of BookKeeper and terminology.
The authors of BookKeeper—Benjamin Reed, Flavio Junqueira, and Ivan Kelly—used their experience building ZooKeeper to design a flexible system for supporting various workloads. In addition to its primary use as a Write-ahead Logging (WAL) mechanism for distributed systems. BookKeeper has grown beyond its original scope and has become a fundamental building block for several enterprise-grade systems, including Twitter’s EventBus and Yahoo’s Apache Pulsar (incubating).
BookKeeper is a scalable, fault-tolerant, and low-latency storage service optimized for real-time workloads. Based on our several years of experience, an enterprise-grade, real-time storage platform should have the following requirements:
BookKeeper was designed to meet these requirements and is widely deployed to serve several use cases, such as building high availability or replication facilities for distributed systems (e.g. the HDFS NameNode, Twitter’s Manhattan key-value store), providing replication between machines in a single cluster and also across clusters (multi-datacenter replication), serving as a store for publish/subscribe (pub-sub) messaging systems, Twitter’s EventBus and Apache Pulsar (incubating), and also storing immutable objects for streaming jobs, for example snapshots of checkpointed data.
BookKeeper provides replicated, durable storage of log streams, that is, streams of records that form a sequence with a well-defined order.
Data is written into logs in Apache BookKeeper as a sequence of indivisible records rather than as individual bytes. A record is the smallest I/O unit in BookKeeper, as well as the unit of address. Each record contains sequencing numbers (e.g. monotonically increasing long numbers) associated with or assigned to it. Clients always start reading from a particular record, or they tail a sequence, which means that they listen to the sequence for the next record to be appended to the log. Clients can receive data one record at a time or in chunks of multiple records. Sequencing numbers can also be used for retrieving records randomly.
BookKeeper provides two storage primitives for representing logs: one is the ledger (aka log segment); the other is the stream (aka log stream).
A ledger is a sequence of data records that gets terminated either when a client explicitly closes it or when a writer—a client who writes records into it—has crashed. Once a ledger is sealed, no records can be appended to it. The ledger is the lowest-level storage primitive in BookKeeper. Ledgers can be used for storing either bounded sequences of data or unbounded streams.
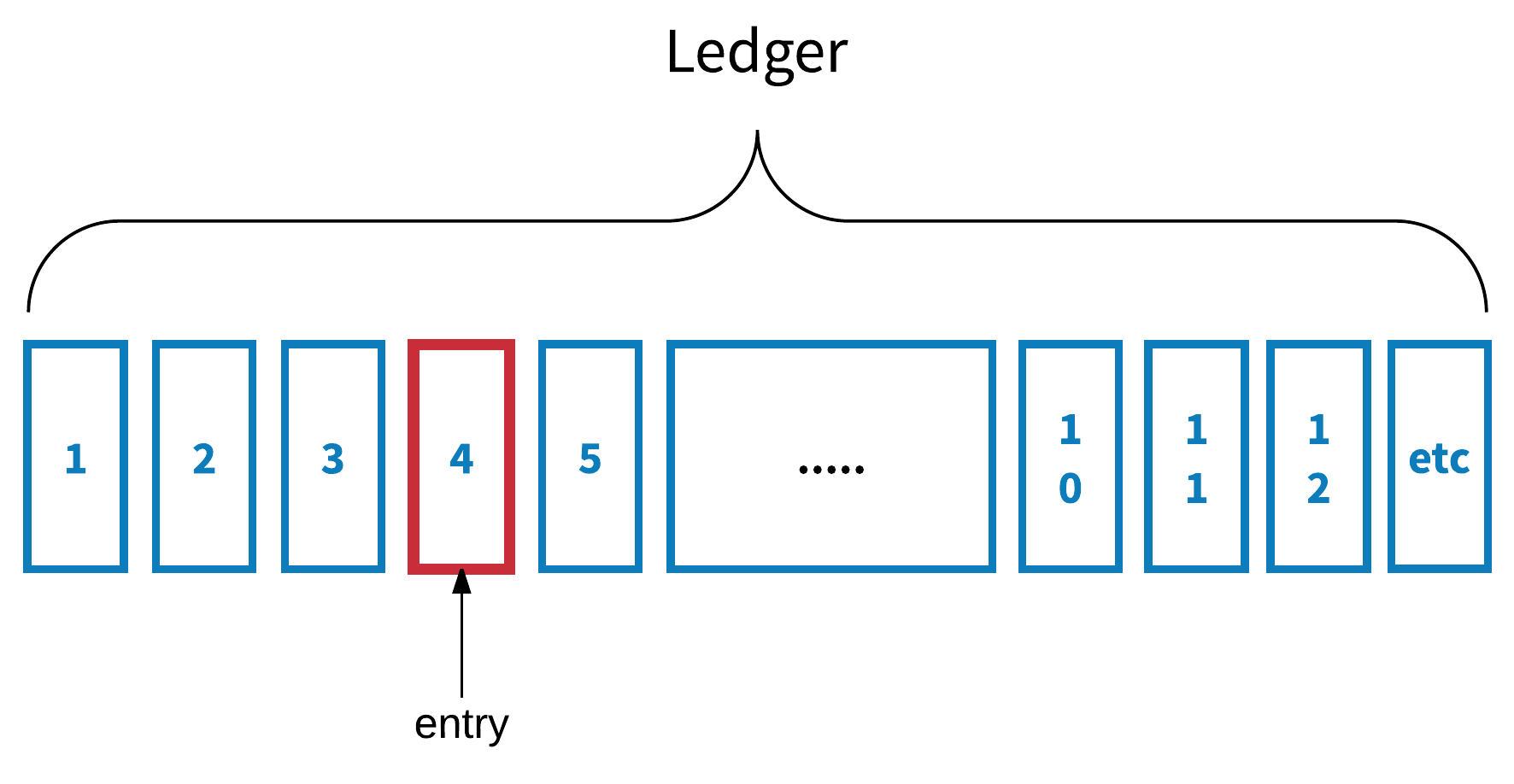
Figure 1. BookKeeper ledger: a bounded sequence of data entries
A stream (aka log stream) is an unbounded, infinite sequence of data records, which by default will never be terminated. Unlike a ledger, which can only be opened one time to append records, a stream can be opened multiple times to append records. A stream is physically comprised of multiple ledgers; each ledger is rotated according to either a time- or space-based rolling policy. Streams are expected to live for a relatively long time—days, months, or even years—before being deleted. The primary data retention mechanism for streams is truncating, which involves dropping the oldest ledgers according to either a time- or space-based retention policy.
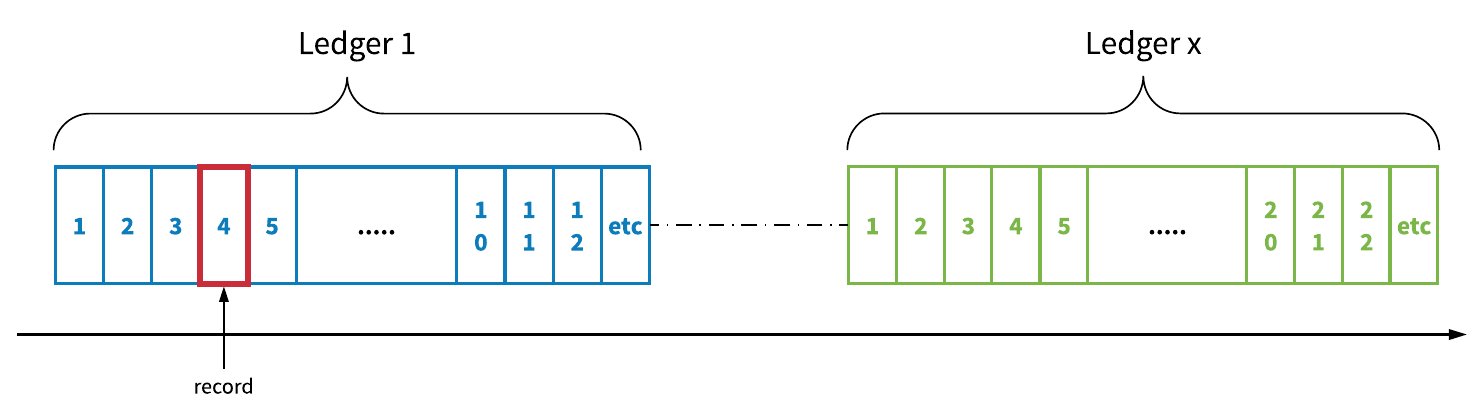
Figure 2. BookKeeper stream: an unbounded stream of data records
Ledgers and streams provide a unified storage abstraction for both historic and real-time data. Log streams provide the ability to stream or tail to propagate real-time data records as they are written. The real-time data stored as ledgers become historic data. The data accumulated in stream is not bounded by any single machine’s capacity.
Log streams are usually categorized and managed under a namespace. A namespace is a mechanism used by tenants to create streams. A namespace is also a deployment or administrative unit enabling you to configure the data placement policy at namespace level. All streams within the same namespace inherit the same namespace settings and place the records in the storage nodes configured by this data placement policy. This provides a powerful mechanism for managing many streams at once.
BookKeeper replicates and stores data entries across multiple storage servers called bookies. A bookie is an individual BookKeeper storage server that stores data records. For the sake of performance, individual bookies store fragments of ledgers rather than entire ledgers. Bookies thus function as part of an ensemble. For any given ledger L, an ensemble is the group of bookies storing the entries in L. Whenever entries are written to a ledger, they are striped across the ensemble (written to a sub-group of bookies rather than to all bookies).
BookKeeper requires a metadata storage service to store information related to ledgers and available bookies. It currently uses ZooKeeper for this task (as well as for some other coordination and configuration management tasks).
BookKeeper applications have two main roles when interacting with bookies. First, they create ledgers or open streams to write data; second, they open ledgers or streams to read. BookKeeper provides two APIs for interacting with these two different storage primitives in BookKeeper:
| API | Description |
|---|---|
| Ledger API | A lower-level API that enables you to interact with ledgers directly, give you full flexibility to interact with bookies however you’d like. |
| Stream API | A higher-level, streaming-oriented API, offered via Apache DistributedLog, that enables you to interact with streams without managing the complexity of interacting with ledgers. |
The choice of which API to use depends on how much granular control you need over ledger semantics. Both APIs can be simultaneously used within a single application as well.
The following diagram shows a typical BookKeeper installation.
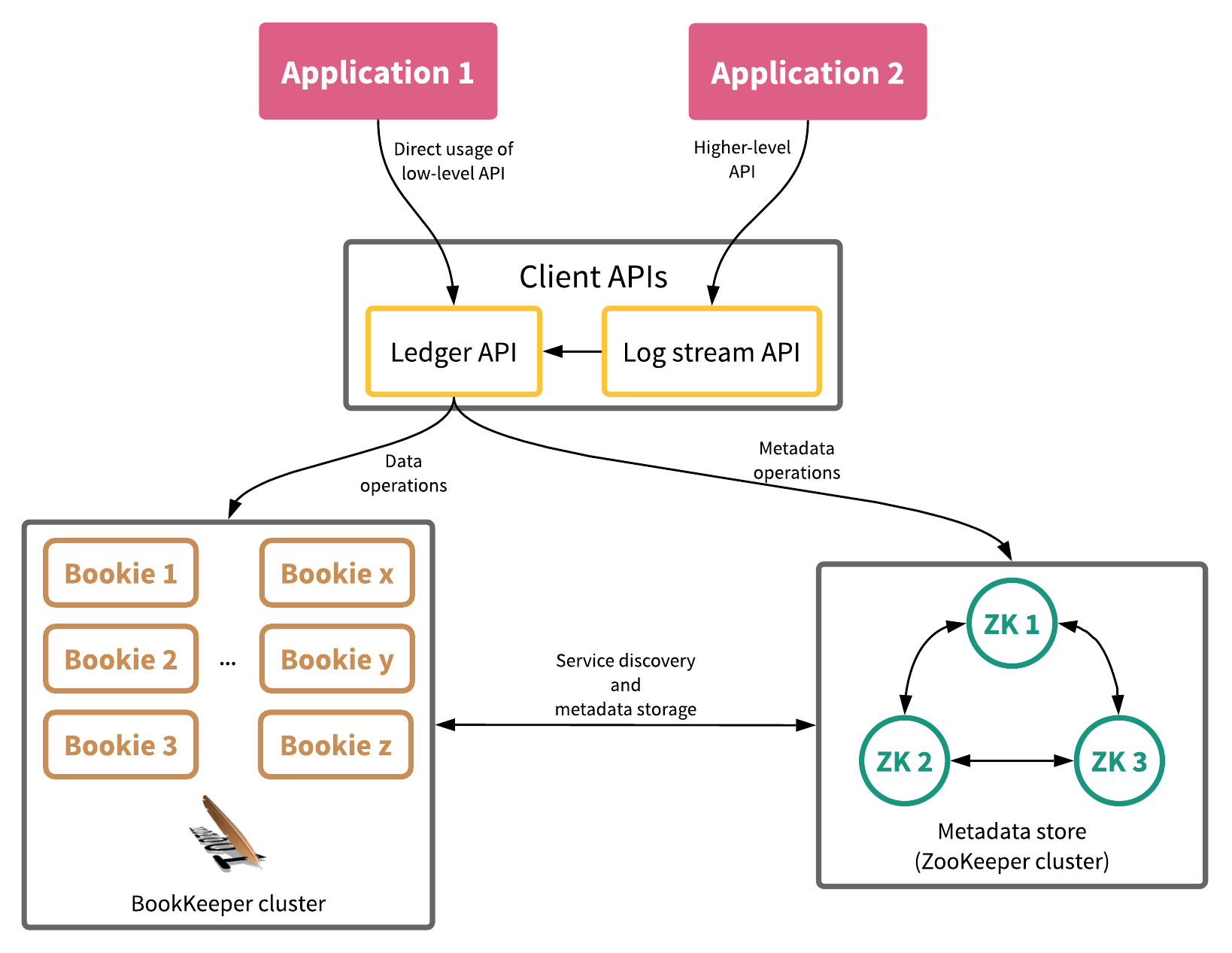
Figure 3. A typical BookKeeper installation (plus applications connecting via multiple APIs)
A few things to note in this diagram:
This post provided a high-level overview of BookKeeper and introduced the concepts of entries, ledgers, streams, namespaces, and bookies. Finally, we saw what a typical BookKeeper deployment looks like and how data flows through it. In the next blog post, we’ll examine how BookKeeper provides consistency, durability, and low latency.
If you’re interested in BookKeeper or DistributedLog, you may want to participate in the BookKeeper community via:
For more information about the Apache BookKeeper project in general, please visit the official website at https://bookkeeper.apache.org and follow the project on Twitter @asfbookkeeper.
Thanks,
Sijie Guo

The Splunk platform removes the barriers between data and action, empowering observability, IT and security teams to ensure their organizations are secure, resilient and innovative.
Founded in 2003, Splunk is a global company — with over 7,500 employees, Splunkers have received over 1,020 patents to date and availability in 21 regions around the world — and offers an open, extensible data platform that supports shared data across any environment so that all teams in an organization can get end-to-end visibility, with context, for every interaction and business process. Build a strong data foundation with Splunk.

Get the latest articles from Splunk straight to your inbox.
© 2005 - 2024 Splunk Inc. All rights reserved.
