
Digital Resilience Pays Off
Download this e-book to learn about the role of Digital Resilience across enterprises.

When people talk about effectively-once (or exactly-once) guarantees, it’s often in the context of stream processing engines. SPEs, however, are usually just one piece of a larger data pipeline consisting of many components, all of which can fail. If you want your data pipeline to provide effectively-once guarantees, you’ll need the other, non-SPE components of your pipeline to provide corresponding guarantees.
This blog post lays out what those guarantees are and explains how they are provided by Apache Pulsar, the messaging system at the heart of Streamlio’s intelligent platform.
The diagram below illustrates a word count application:
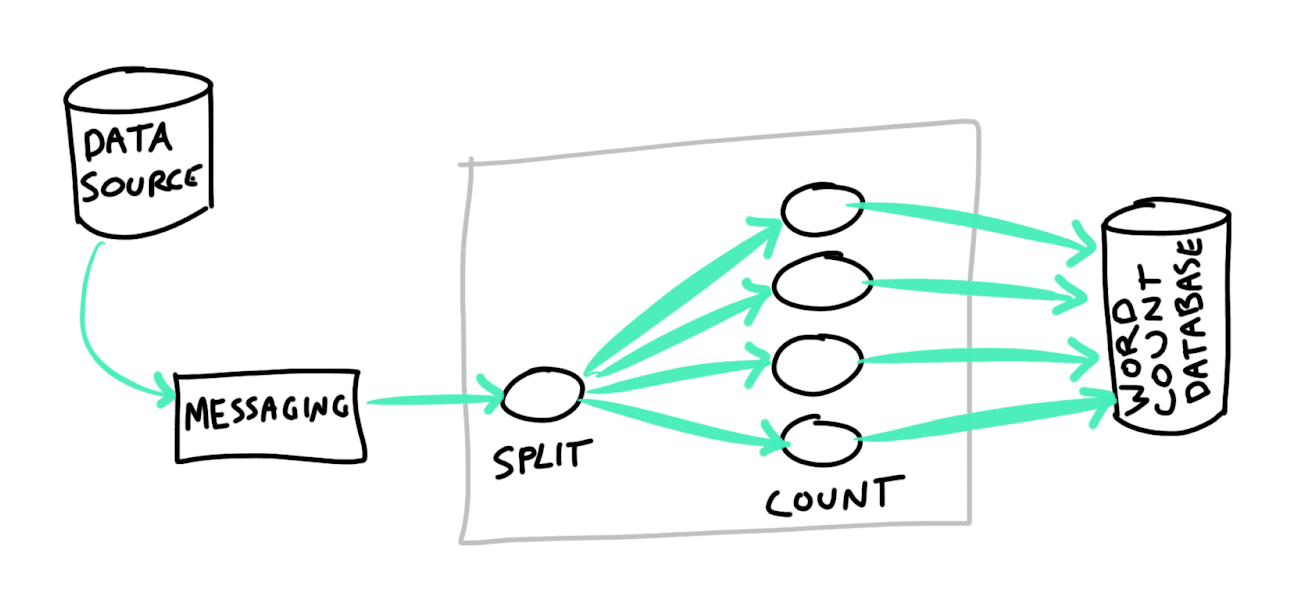 Figure 1. An example word count application
Figure 1. An example word count application
Data originates at the data source, such as the Twitter firehose, and gets pushed into a messaging system, which then transports it to the stream processing engine, where it gets processed (i.e. where the words are counted). The data gets processed by the SPE. The resulting counts are then stored in the word count database where they can be used for analytics.
In previous blog posts we discussed how effectively-once guarantees can be provided by the stream processing engine (Heron in particular). In the word count application shown above, however, there can also be failures both in the messaging system and in the data source (the point at which the data is pushed into the messaging system). In order to ensure that effectively-once guarantees can be maintained within the data pipeline, we need to provide effectively-once guarantees at the messaging and data source stages as well. The word count database can fail, compounding the problem. This database, however, is merely a replica of the data contained in the word-counting nodes of the application, which can be recovered easily, so it will not be discussed further in this post.
To provide effectively-once guarantees, the following needs to happen when a failure occurs in either the messaging system or the SPE: the stream processing engine must be able to reattach to the messaging system at a point in time before the failure occurred and start reprocessing. When it reattaches, it needs to receive all the same messages it received prior to the failure. There should be no messages lost and no messages duplicated. And for the vast majority use cases, the messages should be in the same order.
While the “same order” requirement is not a correctness requirement per se, consider the case that the messages do not come in the same order. For the receiver, in this case the SPE, to ensure that there are no duplicates, it must keep a track of all messages it has already seen. The storage requirement for this grows linearly with time, which makes it impractical for systems that run for a long time. This makes ordering, while not absolutely required, very very nice to have.
No message loss, no duplicates, and ordering: taken together, they describe total order atomic broadcast (TOAB), which is known to be equivalent to consensus in distributed systems.
It thus follows that a messaging system must either implement consensus or use something that does for it to be able to provide effectively-once guarantees.
There are a number of well-known systems implementing consensus in the open source world. Unfortunately, these systems typically provide key-value-type interfaces, which are unsuitable for storing streams of messages. Moveover, they store data over a single replicated log per cluster, which means that they run into serious difficulty when scaling out to the many streams required for a messaging system. What you need instead is a system that both provides a log like-interface and can scale out to many streams.
Apache BookKeeper is one of a very small handful of systems that provide both. BookKeeper is a replicated log store, which takes the consensus primitive provided by ZooKeeper and scales it out horizontally. For details on how BookKeeper provides scalable total order atomic broadcast, see this blog post.
Apache Pulsar uses BookKeeper to store the message streams associated with each of its topics, which allows it to provide effectively-once guarantees. As it has the TOAB guarantees provided by BookKeeper, it is then possible to allow clients to re-attach to an arbitrary point in the past. Pulsar does this using cursors.
In this blog post, I’ve described how Pulsar provides end-to-end effectively-once guarantees. There is still one piece missing, though: we still need guarantees on the data as it is pushed into the messaging system from applications producing messages on Pulsar topics. This is done using Pulsar’s message deduplication mechanism, which we cover in depth in a previous blog post.
----------------------------------------------------
Thanks!
Ivan Kelly

The Splunk platform removes the barriers between data and action, empowering observability, IT and security teams to ensure their organizations are secure, resilient and innovative.
Founded in 2003, Splunk is a global company — with over 7,500 employees, Splunkers have received over 1,020 patents to date and availability in 21 regions around the world — and offers an open, extensible data platform that supports shared data across any environment so that all teams in an organization can get end-to-end visibility, with context, for every interaction and business process. Build a strong data foundation with Splunk.

Get the latest articles from Splunk straight to your inbox.
© 2005 - 2024 Splunk Inc. All rights reserved.
