
Digital Resilience Pays Off
Download this e-book to learn about the role of Digital Resilience across enterprises.

Monitoring modern infrastructure poses fundamentally new challenges in terms of data volume and velocity. Collecting the metrics emitted by machines is only the first step. To extract value from that data, we need a method of expressing service, team, or business goals against that stream of data. That method is analytics.
Monitoring is a very broad topic and we do not believe any single method or algorithm is appropriate for all scenarios. Most of our users are building services and applications on what we call modern infrastructure: public clouds like AWS and GC; private clouds utilizing Docker containers; and open source technologies like Kafka, Elasticsearch, and Cassandra. Although there are common metrics everyone should monitor for any given component service or technology, what matters to the total application depends on the goals most important to your business.
This is the first in a series of posts on how to use analytics to both compose the most salient signals to monitor out of raw metrics and also how to configure useful alerts. In this post, we will discuss some ways to use SignalFx’s SignalFlow analytics engine to construct high-quality alerts on a single stream of metrics (“signal”) in real time. Through concrete examples, we will explore how to use analytics to not only get better signals, but also how to get to better alerting on those signals.
In future posts, we’ll look at transformation with dynamic thresholds, ranged and constructing a synthetic test signal, and rates of change.
In SignalFx, the device which converts a signal to a(n ideally empty!) sequence of alerts is called a detector. Users create detectors, which contain rules defining triggering behavior for a signal; violation of a rule triggers an alert, which then creates an event in SignalFx and sends notifications if configured.
The most basic kinds of alerts trigger when a simple metric crosses a static threshold, for example anytime CPU utilization goes above 60%. Fixed thresholds are easy to implement and interpret when there are absolute goals to measure against. For example, if we know the typical memory/CPU profile of a certain application, we can define bounds which encode normal state; if we have a business requirement to serve requests within a certain time period, we know what is an unacceptable latency for that function.
Alerting immediately every time a signal crosses a threshold has the benefit of timeliness: if elevated values of the signal reveal problems to come, we will be informed as soon as possible. But even if we choose relevant signals and decent thresholds, the elevated value may only reveal a transient stress on the system.
We use SignalFx internally to monitor the whole lifecycle of services, from dev through test, canary deployments, and full production operation. The data in the chart below reflects CPU utilization across our Elasticsearch cluster. The owners of that service have observed that typical utilization stays under 50%. When the CPU utilization is high for the cluster, Elasticsearch nodes are performing more work than we configured them to do, and this is likely to introduce delays in search and/or indexing requests. For illustrative purposes, imagine a detector set to fire when CPU utilization is above 60%.

This would have fired and cleared three times within a one-minute span. As users experience more and more alarms which require no action, or are flappy, they lose confidence in their alerts and learn to ignore them. Traditional check, polling, and static threshold using monitoring systems are notorious for firing too many alerts during events like these and turning a useful signal into too much noise to be immediately actionable.
There are several ways to handle this phenomenon within SignalFx. A straightforward method is to set both a threshold and a duration for the alert. In our case, we could require that utilization be above 60% for 2 minutes. In SignalFx the severity of the alert and associated notification are also configurable. For example, we can have a minor alert (above 60% for 2 minutes, say) send a message to a Slack channel, while a critical alert (above 75% for 5 minutes, say) pages the on-call.
One issue with duration conditions is that they may be too stringent: a single reading below the threshold means the detector will not fire an alert. To handle this case, SignalFx detectors can be configured with refined duration conditions. For example, we could require that utilization be above 60% for 80% of a 5 minute period (4 out of a 5 minute moving window). SignalFx has the ability to perform this apparently innocent calculation in real time across a variety of metrics and large populations of hosts.
Another approach uses more powerful analytics functionality offered by SignalFx: instead of firing an alert on the raw metric, we can first apply a smoothing transformation to obtain a better signal which experiences less fluctuation. The goal of smoothing transformations is to reduce the impact of a single (possibly spurious) extreme observation.
One such transformation is the rolling mean, which replaces the original signal by the mean (average) of its last several values, where “several” is a parameter (the “window length”) that we can specify. In effect we replace the signal with a summary of its behavior during the last window.
One motivation for the rolling mean is to think of the observed values as gotten by sampling the “true” signal at regular intervals. Then averaging the last few sample values is a method of approximating the true signal. Here is what the rolling mean looks like in the Elasticsearch example.

The resulting signal jumps around the threshold less frequently; in this example, the rolling mean never crosses the threshold of 60%. A rolling mean is a general statistical procedure for ironing out the kinks in a signal so that its tendency to cause a detector to fire/clear in quick succession is lessened. While many software products and statistical packages calculate rolling means, in SignalFx that calculation is performed in real time so alerts can be based on the transformed signal and expected to be both timely and accurate. Using the rolling mean transformation improved the quality of the signal emitted by the Elasticsearch cluster.
In practice, setting a threshold on the rolling mean is similar to creating a static threshold on a raw metric for some duration. For example, if a metric is above 60% for a 2 minute duration, the 2 minute rolling mean will be at least 60%. Setting a 60% threshold against the 2 minute rolling mean will trigger in a variety of scenarios, corresponding roughly to several static threshold and percent of duration combinations; here are a few examples of 2 minute periods where the rolling mean is at least 60%:
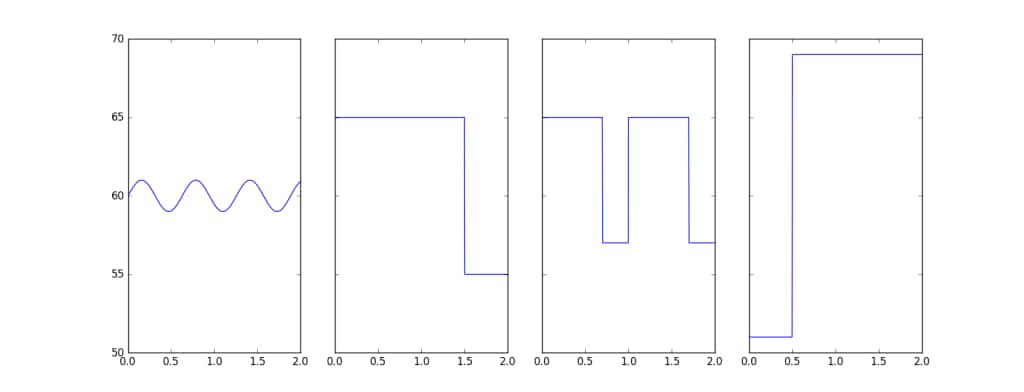
For the rolling mean to reach a given threshold, time spent under the threshold must be balanced out by time spent above the threshold. The rolling mean is also insensitive to the ordering of the points in the window. Using the rolling mean thus allows us to cover a wide range of scenarios with a single detector.
Both the duration requirement and the rolling mean transformation give up a little timeliness in exchange for less noise — requiring the duration condition gives problems more time to persist while the rolling mean tends to lag behind the sample values (depending on the window length). But compared to alerting immediately every time a static threshold is crossed, they have fewer false alarms and exhibit less flappy behavior. As a result, users have higher confidence in the alerts, and pay attention to them when they are received. Real-time analytics is the essential tool for navigating the tradeoff between timeliness and avoiding noisy alerts through the creation of better signals in the first place, as well as better alerts on those signals.

The Splunk platform removes the barriers between data and action, empowering observability, IT and security teams to ensure their organizations are secure, resilient and innovative.
Founded in 2003, Splunk is a global company — with over 7,500 employees, Splunkers have received over 1,020 patents to date and availability in 21 regions around the world — and offers an open, extensible data platform that supports shared data across any environment so that all teams in an organization can get end-to-end visibility, with context, for every interaction and business process. Build a strong data foundation with Splunk.

Get the latest articles from Splunk straight to your inbox.
© 2005 - 2024 Splunk Inc. All rights reserved.
