
Digital Resilience Pays Off
Download this e-book to learn about the role of Digital Resilience across enterprises.
It’s no secret anymore: metrics are one of the most powerful tools an engineering team can have at its disposal when building modern, distributed applications. From observability to monitoring and from insights to alerting, historical trends and forecasting, metrics and timeseries data have the potential to deliver immense value across a wide gamut of engineering, operational and business questions.
From the very beginning at SignalFx, we understood that monitoring had become an analytics problem. A new generation of monitoring system was needed to unlock this potential. Whatever shape that system took, we also knew that metadata had to be a first-class citizen.
We set off to build the real-time streaming analytics platform for monitoring: a system capable of processing the largest amounts of data in real-time with metadata deeply integrated within its data store and streaming analytics service and leveraging this metadata to answer the most complex of questions from any member of the organization.
In this blog post, I dive into how our metadata model works and how our SignalFlow real-time analytics engine can use that metadata to correlate timeseries with each other when combining multiple plots or timeseries together via an algebraic formula.
In line with the Metrics 2.0 guidelines, the identity of timeseries in SignalFx is defined by a metric name and a set of dimensions:
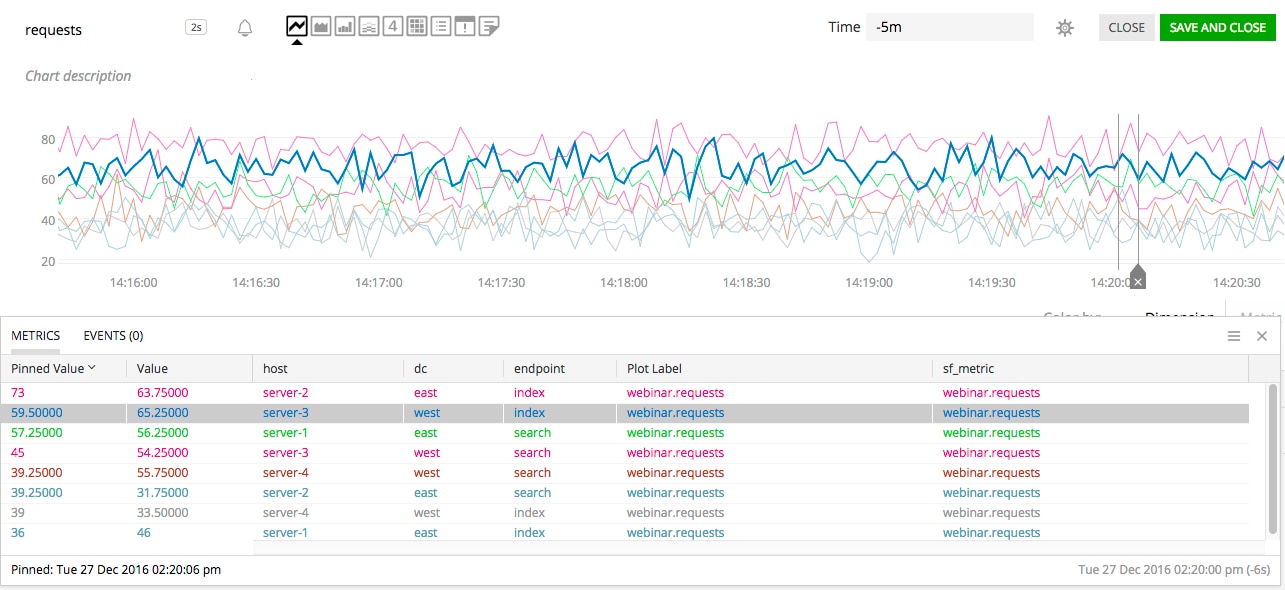
sf_metric: requests endpoint: signalflow/execute method: post host: server-1
In SignalFx, the timeseries described above, the "requests" metric and each of those dimension key/value pairs is a distinct metadata object. Each of them can be accessed through our API. But more importantly, each of them supports additional, user-defined properties. Our metadata database automatically and transparently propagates those properties from the metric and dimension objects onto the timeseries, enhancing the timeseries object with all this additional information, making it visible to the SignalFlow analytics engine.
What this means is that if you add a "dc:west" property to the "host:server-1" dimension object (and similarly, to other values of "host"), you can now search, filter or aggregate requests timeseries by this dc property from SignalFlow:
data('requests').sum(by='dc').publish('requests by dc')
This mechanism is also used by our Amazon AWS EC2 integration: we automatically query AWS for information about your EC2 instances and add this metadata as properties to the corresponding "host" dimensions (by AWS unique ID, instance ID and hostname). These properties then propagate to the timeseries reported with those dimensions, making it possible to filter or aggregate across a much more extensive set of dimensions and properties. Without any additional work and instrumentation, you can now filter on aggregate on things like instance type, availability zone, auto-scaling group, etc!
Before getting to how correlations work in SignalFlow, it’s important to understand how the metadata of the timeseries in a stream processed by SignalFlow is affected by aggregations performed on those timeseries. In a “basic” stream of timeseries, the metadata and available dimensions are that of the timeseries themselves:
data('requests') -> {host, endpoint}
When doing an aggregation, the resulting timeseries have their own identity, built from whatever dimension or property the stream was aggregated against:
data('requests').sum(by='dc') -> {dc}
Here, even though "dc" was not a dimension of the input timeseries (it was a metadata property available on those timeseries), the resulting timeseries will have a "dc" dimension – and only that dimension; each of them representing the sum of the values of all the "requests" timeseries of the same datacenter, for each datacenter.
One of the coolest features of SignalFx is the ability to use arbitrary algebraic expressions and math to combine data. Those expressions directly translate into SignalFlow and, if you’ve been following some of our previous blog posts on anomaly detection, you have most certainly seen them in use before.
Continuing with the example above, let’s say that we want to know: for each host in each datacenter, which part of the total load of that datacenter the host handles. We can write the following SignalFlow program to answer that question:
requests = data('requests')
by_host = requests.sum(by=['host', 'dc'])
by_dc = requests.sum(by='dc')
(100 * by_host / by_dc).publish('relative host load')
As you can see, we’re using the "host" dimension, as well as the "dc" property (coming from each "host") to create two streams: "by_host"and "by_dc". Each of those streams will have multiple timeseries, respectively one per host, and one per datacenter. But how is the expression "100 * by_host / by_dc" evaluated?
It starts by identifying which of those two streams is the most specific: the one with the most specific grouping and dimensions. That stream will be the base for the correlation and it defines what dimensions the output timeseries will have. In the program above, "by_host" is the most specific stream and the output of the expression will have the same "{host=..., dc=...}" grouping.
Let’s assume that we have timeseries for "endpoint"s "search" and "index", from "hosts server-1" and "server-2" in the "east" datacenter, and "server-3" and "server-4" in the "west" datacenter, for a total of 8 timeseries.
The "by_host" stream will have 4 timeseries, for each "host" in each "dc". The "by_dc" stream will only have 2 timeseries: the "east" and "west" datacenters.
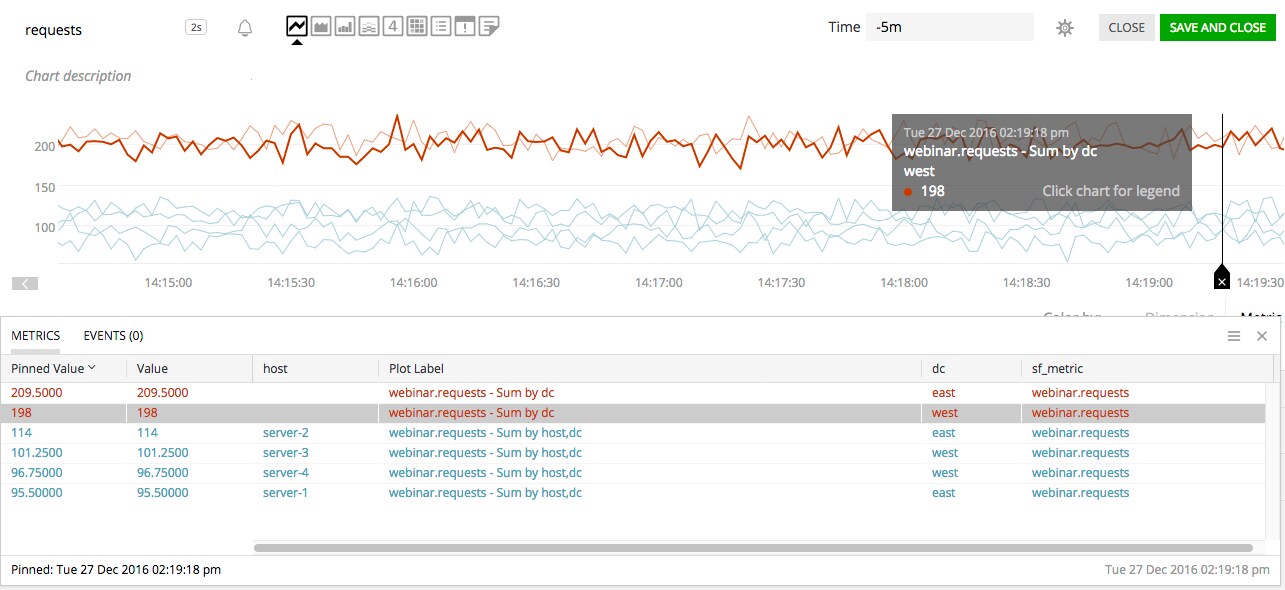
For each of the 4 timeseries of that "by_host" base, we’ll find the timeseries from "by_dc" that has the same "dc" value (the only common dimension), evaluate the expression with the corresponding values from each timeseries, and output the result as a new timeseries with the "host" and "dc" dimensions of that particular "by_host" timeseries.
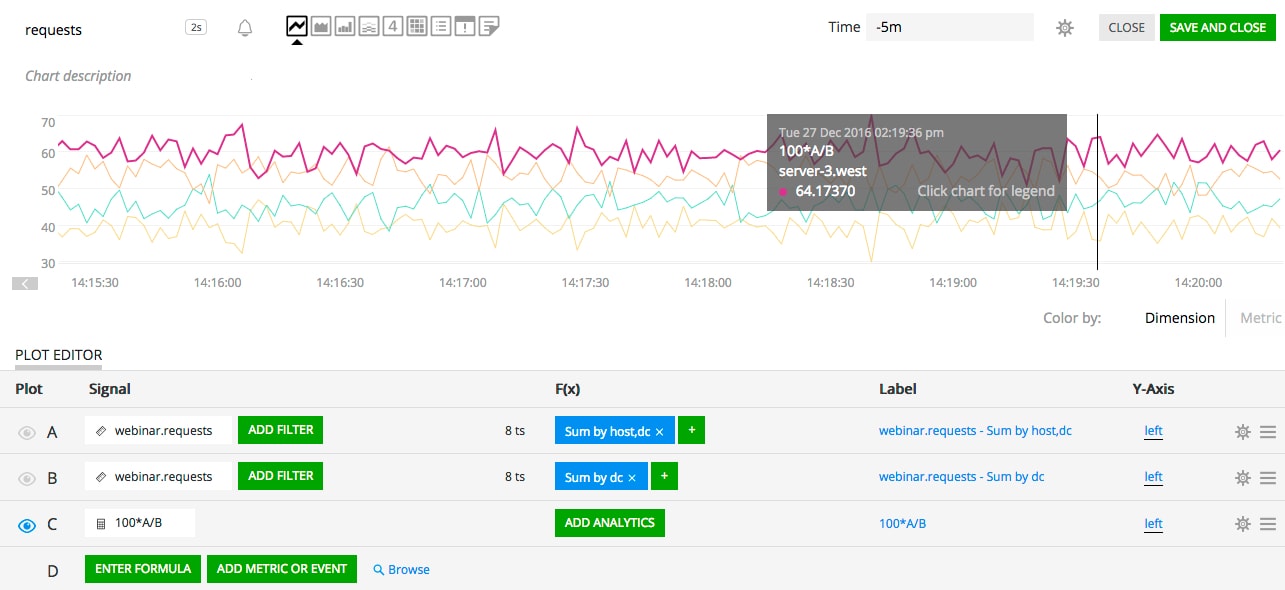
The same logic, by extension, works when correlating against a fully aggregated stream. Since that stream will have no dimensions other than its metric, the single timeseries that results from this aggregation always directly correlates with any other timeseries from another stream. The following SignalFlow program computes the percentage share of the request load handled by each host:
requests = data('requests')
by_host = requests.sum(by='host')
total = requests.sum()
(100 * by_host / total).publish('host load share')
Each timeseries of "by_host" (one per host, as per the sum aggregation) will correlate with the single timeseries of "total". The output will have one timeseries for each host, resulting from the evaluation of the "100 * by_host / total" expression for each one.
Metadata is, of course, never static. Metadata properties are updated, new timeseries appear when new hosts or new instances are spun up, while others stop reporting when instances are torn down. The SignalFlow analytics engine of SignalFx keeps its view of your metadata up-to-date in real-time so your charts, your detectors or the programs that you execute through the SignalFlow API always show you the most accurate picture of what’s going on in your infrastructure.
But, because the semantics of how correlation is done in SignalFlow are defined by the SignalFlow program itself, not by the timeseries, you’ll always get exactly what you ask for regardless of how many timeseries match your queries or if new timeseries appear and others disappear while your program is executing.
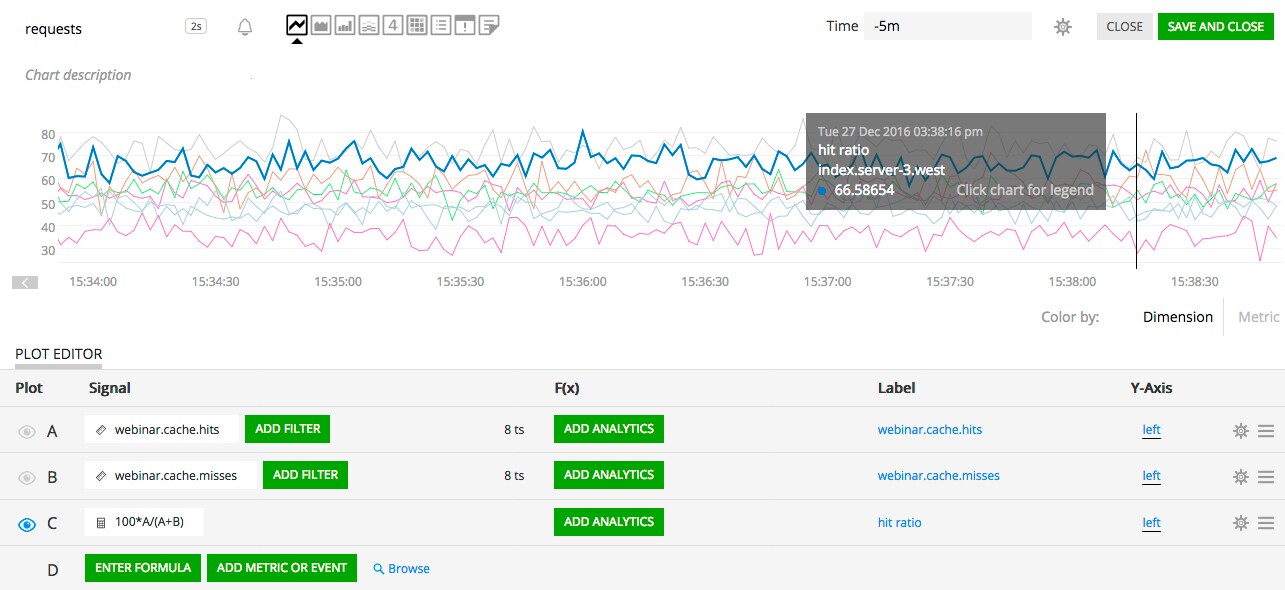
Another very common use case involves doing math on timeseries from different metrics, like the ratio of one over the other. A common example is the calculation of a cache hit rate, given two counters: "cache.hits" and "cache.misses":
hits = data('cache.hits')
misses = data('cache.misses')
(100 * hits / (hits + misses)).publish('hit ratio')
In the presence of multiple timeseries for each of those two metrics, the correlation algorithm does what you expect: match timeseries one-to-one from each metric and evaluate the expression for each matching pair, effectively “ignoring” the metric. Of course, the timeseries for each metric need to share enough dimensions to compose non-ambiguous matching pairs.
Keeping with our example above, we can imagine that each request does a cache lookup and that we record the cache hit or cache miss for each endpoint from each host. Our "cache.hits" and "cache.misses" timeseries would all have an "endpoint" dimension and a "host" dimension.
Because those two sets of timeseries have effectively equivalent dimensions, so will the output of the expression and the resulting stream, published with the "hit ratio" label, will consist of 8 timeseries, one for each "host" and "endpoint".
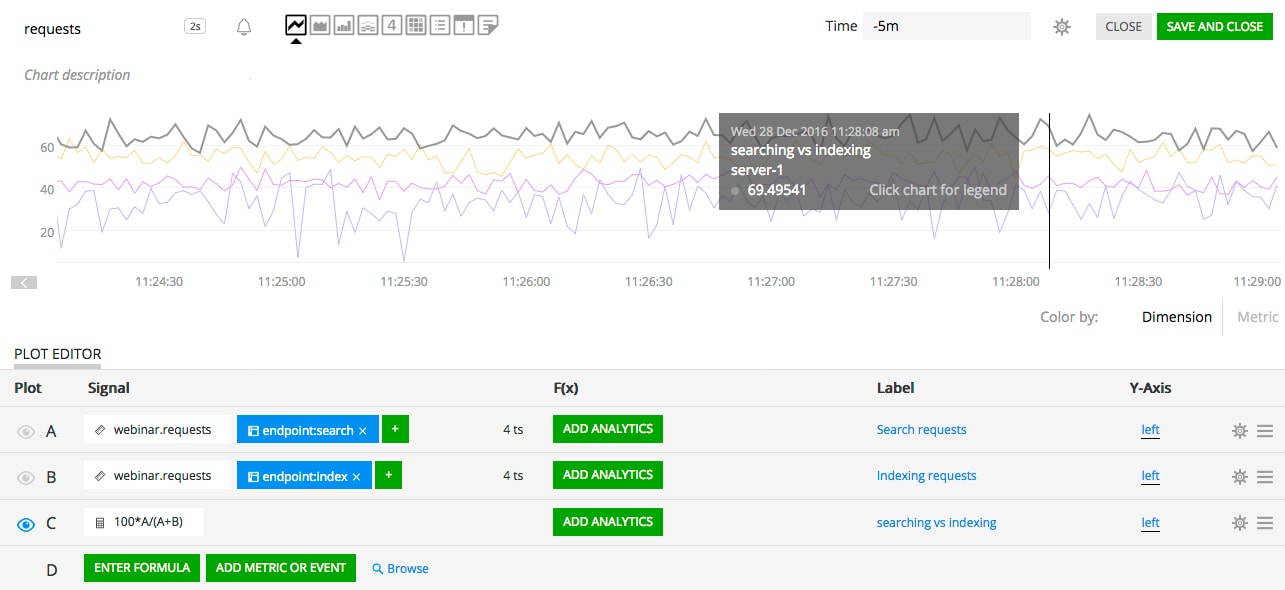
A variation of the example above is when you need to compare distinct sets of timeseries from the same metric, based on a different filter. The program below computes the proportion of search requests versus indexing requests.
search = data('requests', filter('endpoint', 'search'))
index = data('requests', filter('endpoint', 'index'))
(100 * search / (search + index)).publish('searching vs indexing')
The magic that actually takes place here and in the previous example is that SignalFlow automatically identifies the explicit constants of the correlation that should be ignored when matching up timeseries. We call them fixed dimensions because they are timeseries dimensions (the metric is technically also a dimension) that are fixed by the nature of the query and filters in the user’s SignalFlow program.
When correlating across different metrics, the metrics are fixed and we look at the rest of the dimensions (the variable dimensions) to match timeseries together. Similarly, when filters are present, they pin those particular dimensions or properties and we use the remainder of the dimensions to match timeseries together.
The output is defined by the common fixed dimensions between the inputs and the variable dimensions, which by definition of the correlation have to match up. In this example, there are no common fixed dimensions, and the only other dimension on our "requests" timeseries is "host". This means we’ll get 4 timeseries, one per host, showing this calculated proportion.
The one twist on identifying fixed dimensions from the metric query and filters is that it’s only possible to do so when they absolutely pin a particular dimension to a specific value. Wildcards, regexs and "or"-ed filters do not guarantee this so they have to be ignored, and those remain as variable dimensions.
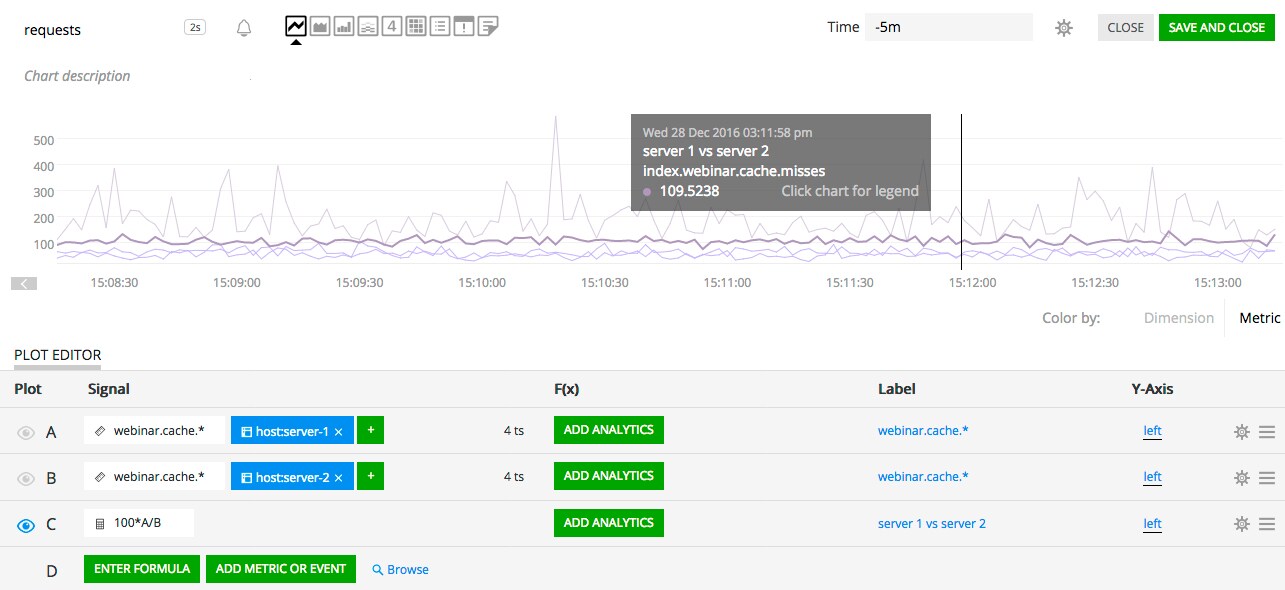
Keeping with our example above with the "cache.hits" and "cache.misses" timeseries (which all have "host" and "endpoint" dimensions), the following program will correlate timeseries based on both the metric name and the endpoint:
s1 = data('cache.*', filter('host', 'server-1'))
s2 = data('cache.*', filter('host', 'server-2'))
(100 * s1 / s2).publish('server 1 vs server 2')
Each timeseries from "s1" is matched to the timeseries of "s2" that shares the same metric name and the same "endpoint". The output has 4 timeseries: the "cache.hits" and the "cache.misses" for each endpoint, "search" and "index".
As you can see, timeseries metadata is a really important part of making powerful analytics possible, especially when you have SignalFlow’s built-in understanding of that metadata at your disposal! The support for those various and sometimes complex correlation scenarios in our SignalFlow analytics engine is the cornerstone of many of SignalFx’s advanced features and anomaly detection capabilities.
Try it out yourself in a new chart or in a SignalFlow program!

The Splunk platform removes the barriers between data and action, empowering observability, IT and security teams to ensure their organizations are secure, resilient and innovative.
Founded in 2003, Splunk is a global company — with over 7,500 employees, Splunkers have received over 1,020 patents to date and availability in 21 regions around the world — and offers an open, extensible data platform that supports shared data across any environment so that all teams in an organization can get end-to-end visibility, with context, for every interaction and business process. Build a strong data foundation with Splunk.

Get the latest articles from Splunk straight to your inbox.
© 2005 - 2024 Splunk Inc. All rights reserved.
