
Digital Resilience Pays Off
Download this e-book to learn about the role of Digital Resilience across enterprises.
Splunk is committed to using inclusive and unbiased language. This blog post might contain terminology that we no longer use. For more information on our updated terminology and our stance on biased language, please visit our blog post. We appreciate your understanding as we work towards making our community more inclusive for everyone.
Fast-evolving anomalies can quickly turn into outages. If your monitoring system is too slow, or not granular enough, you may not be able to catch the anomaly in time. Even when you do, manual remediation steps may not be put in place fast enough to prevent the outage.
In this blog, we explore what it takes to efficiently counteract fast-evolving anomalies and take automatic remediation actions before your service melts down.
Today’s systems are increasingly more complex and distributed, with large amounts of real-time traffic flowing across the stack at any given time. Sometimes, those systems fail in new or unexpected ways that could not be anticipated because of the complex interdependencies that exist in such systems. Among those failures, there is a particular subset that is the most difficult to deal with: lightning fast outages.
In this context, I define a lightning fast outage as a sudden meltdown of one or more components or services. They happen when an anomaly appears in the system and very quickly degenerates into a full blown, customer-impacting outage. From my experience, the causes of these outages range from unusual user activity, to unexpected traffic or load on the system, or simply because of a bug lurking down a less-traveled code path.
The biggest challenge with those fast-evolving anomalies is that they are very difficult to catch soon enough to do anything about them. Most monitoring systems simply aren’t granular enough — or fast enough — to even detect them.
Periodic checks most often can’t even see the anomaly develop before it turns into an outage, and they can’t provide any context as to what transpired prior to incident. Metrics give enterprises a step in the right direction. Yet metrics-based monitoring systems still need to be granular enough, fast enough, and know how to deal with the real-time nature of the data. A lot of metrics-based systems like Graphite, InfluxDB or Prometheus don’t offer satisfactory guarantees on the completeness and accuracy of the most recent data. You should always be able to trust your charts’ right edge.
Even within the (sad) reality that most engineering and operations teams are effectively blind to what is truly happening “right now” in their systems, being able to detect the anomaly is just one part of the story. Addressing the anomaly before it turns into an outage is the of course the next step, but walking that path is the ultimate weak link in this process: the on-call human! How quickly and accurately do you realistically address issues when getting paged half-asleep at 3am?
The main challenge in efficiently dealing with those lightning fast anomalies is that it takes a coordinated effort between your monitoring system and your application: you need a fast and powerful real-time monitoring and alerting system, coupled with a dynamic stack that gives you the necessary levers or safety valves to impact real-time changes on your application.
Metrics are the best vehicle to gain observability into your system. But to be an effective part of a solution against lightning fast outages, a metrics-based monitoring system needs three key characteristics:
With a strong culture of code instrumentation, you can get visibility into every level of your stack, from host to container to application. Many stop at infrastructure and framework-level metrics via drop-in agents, but custom application metrics often bring the most value and better surface what your application is doing. This is especially true in backend platforms with a lot of first party microservices.
To capture those, use a metrics library for your language of choice. If necessary, build utilities to reduce friction and make it easier for your engineers to instrument their code. For example, at SignalFx, we have a wrapper around the Dropwizard metrics library to easily capture dimensions on our metrics, or to easily declare a gauge that will update its value when reported:
metrics.counter("requests", "endpoint", "search").inc();
/*
* When reporting errors, using the exception class name as a dimension
* can be useful to quickly see what exceptions happen more often than
* others.
*/
metrics.counter("errors", "class", e.getClass().getName()).inc();
// A gauge that reports the size of a queue. Very little boilerplate!
metrics.registerGauge("queue_size", queue::size);
/*
* Timers allow you to count how many times the block of code is executed
* and how long they take (with min/median/mean/max and p9x values).
*/
try (Timer.Context c = metrics.timer("request.timer").time()) {
// process data
}
At SignalFx, those custom application metrics account for more than 75% of the metrics engineers care about, look at, or alert on to keep a finger on our systems’ pulse.
Quickly detecting fast-evolving anomalies requires fast, real-time, metrics analytics based anomaly detection and alerting. A system that is accurate “right now”, that can detect a historical anomaly within seconds, even on the most recent data. A system with a strong understanding of the reporting behavior of your data so that, even if one server has a slight reporting delay, your monitoring system can wait the right amount of time (but no more!) to capture that.
There is obviously always a tradeoff between the timeliness of an alert and the accuracy of the calculation that lead to it. But it’s important to be in control of that tradeoff.
An advanced metrics analytics system will allow you to build smarter, dynamic alerts that don’t depend on inflexible static thresholds but can instead automatically identify “normal” and quickly detect when veering off from that normal.
Once you are able to quickly detect an anomaly, you need to be able to apply changes to your application dynamically and prevent this anomaly from getting worse and turning into an outage. What change or action you need to take obviously depends on what’s happening with your system: you may need to increase capacity, shed some load, adjust queues or buffer sizes, temporarily disable certain features or functionality, etc.
The point is that you need to build your application stack with this dynamicity in mind, from infrastructure provisioning to application configuration. Building an elastic infrastructure with automated provisioning and built-in support for horizontal scalability and service discovery gives you the flexibility that you need to dynamically scale up and down to respond to load and traffic.
Just like instrumentation, deeply integrating service discovery into your application framework can make horizontal scalability completely seamless to downstream services. At SignalFx, a combination of Guice, Thrift, and the Curator service discovery library allow us to write very simple code that automatically load balances requests to a backend:
public class Foo {
private final AnalyticsService.Iface analytics;
@Inject
public Foo(AnalyticsService.Iface analytics) {
/*
* Injects an implementation of the service interface that
* makes Thrift RPC calls to the target discovered service.
*/
this.analytics = analytics;
}
public void doSomething(String program) {
/*
* Call is always backed by currently advertised instances,
* partitioned and load-balanced as defined by the service.
*/
analytics.execute(program);
}
}
Internally exposing control endpoints from your application (via internal HTTP APIs, JMX operations, a control console, etc) can give you additional levers to impact change on your infrastructure. Endpoints to trigger load shedding, taking an instance in or out of its load balancer, or controlling the consumption of data from Kafka topics, etc. Finally, the ability to perform real-time configuration changes to your application allows you to virtually control every tunable aspect of your system’s behavior. Dynamically impacting the size of thread pools, buffers and queues; controlling task execution intervals; enabling or disabling features and safety valves, etc.. Those are all examples of operations and tuning that can save your system in time of need.
Dynamic configuration is, again, something for which a deep integration into your application framework can make its use more widespread by being easier for your engineers. At SignalFx, configuration values are stored in ZooKeeper and seen in real-time by all service instances. In our code, we can easily access those values and even define callbacks to take more complex actions when a configuration value changes:
config.getThreadPoolSize().addCallback(() -> {
int threads = config.getThreadPoolSize().get();
executor.setCorePoolSize(threads);
executor.setMaximumPoolSize(threads);
});
By now, you probably know where this is going. With both a fast, powerful monitoring system and a dynamic application stack, you have the tools you need to put in place an automatic remediation system. By automating certain key operations in response to fast evolving anomalies, you can finally react fast enough to save your system before the meltdown.
Automatic remediation is of course complicated and limited. The hardest part is to take those remediation actions that you would normally find in a runbook (or as part of your team’s “tribal knowledge”), and turn them into an automated process or a script. The goal is to figure out what action to take, and to what extent, in response to a specific kind of anomaly.
Now, when an alert triggers, you can hook up that notification to the appropriate automated remediation. You’re building your very own “if-this-then-that” system. The technical details here will vary a lot on your specific situation, infrastructure, and tooling, but webhook alert notifications and lambdas are a good place to start wiring all of this together.
Of course, you still want to page whoever’s on-call in a lot of cases so they can make sure the system is responding well to the remediation actions, to assess the impact, and to progressively restore the system to its nominal state once it has stabilized. At least until you’ve automated that aspect of “returning to normal” when the alert clears and are confident in your automation to kick back, relax and let robots do the work!
We often mention that SignalFx is our one and only observability and monitoring tool at SignalFx. As you may imagine, the technology behind SignalFx has some pockets of complexity and we sometimes encounter production anomalies that can lead to degradation of service. Most of the time, anomalies are identified and managed before any major impact on our customers or SLAs. But sometimes, some anomalies evolve and degenerate so quickly that a human response is too slow.
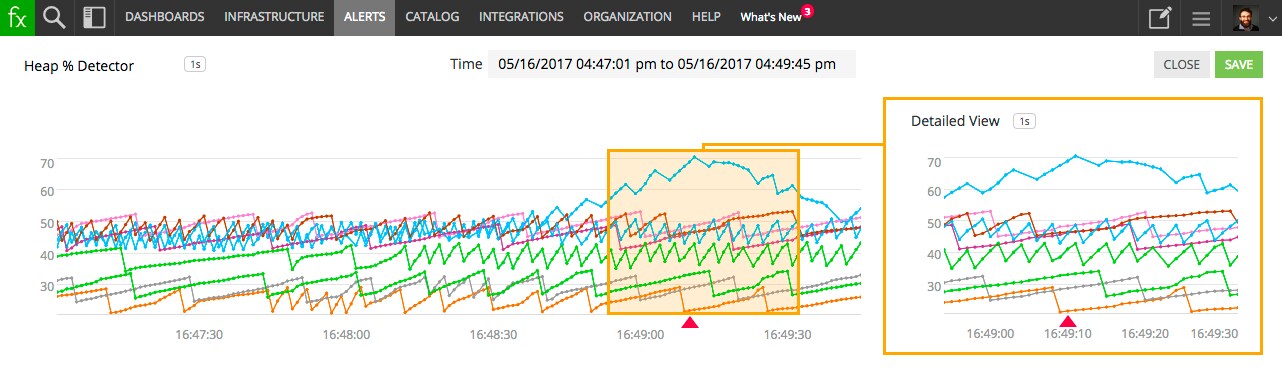
One such anomaly was an unpredictable, very sudden rise in heap usage in one of our components. In a matter of seconds, the heap usage would start to rise well past the garbage collection threshold, and the JVM would eventually run out of memory. The root cause was difficult to identify and it would take a lot of detective work and engineering time to understand and fix whatever bug led to this sudden increase in memory allocation rate.
To make sure that no service degradation happens because of this, we created a detector that would fire when a sudden rise in heap usage percentage happens. Working off 1-second resolution data, SignalFx’s real-time streaming analytics platform is able to quickly identify with great confidence when the heap usage sees an abnormal increase, and fires an alert. By configuring a webhook notification on this alert, we automatically trigger a routine that identifies the abnormal task on that JVM and cancels it. As you can see on the chart above, the remediation happens and takes effect very quickly after the alert fires, saving the JVM before it runs out of heap and preserving the quality of service for our users.
There are new, emerging challenges with dealing with today’s systems. I hope this blog provides some key considerations in handling fast-evolving anomalies through fast monitoring, a dynamic application stack, and a IFTTT system. Take action before your service melts and your customers are impacted!
Check out our webinar on Cloud-Ready Alerting featuring SignalFx customer Acquia »

The Splunk platform removes the barriers between data and action, empowering observability, IT and security teams to ensure their organizations are secure, resilient and innovative.
Founded in 2003, Splunk is a global company — with over 7,500 employees, Splunkers have received over 1,020 patents to date and availability in 21 regions around the world — and offers an open, extensible data platform that supports shared data across any environment so that all teams in an organization can get end-to-end visibility, with context, for every interaction and business process. Build a strong data foundation with Splunk.

Get the latest articles from Splunk straight to your inbox.
© 2005 - 2024 Splunk Inc. All rights reserved.
