How to Use the PAN Data Pipeline Template
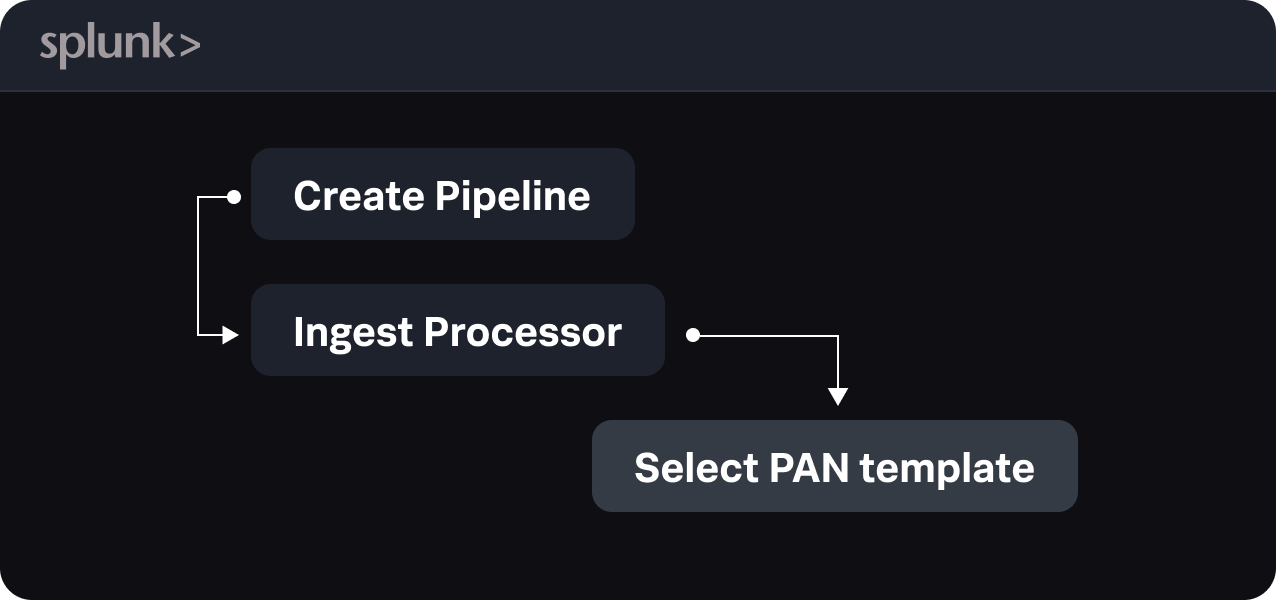
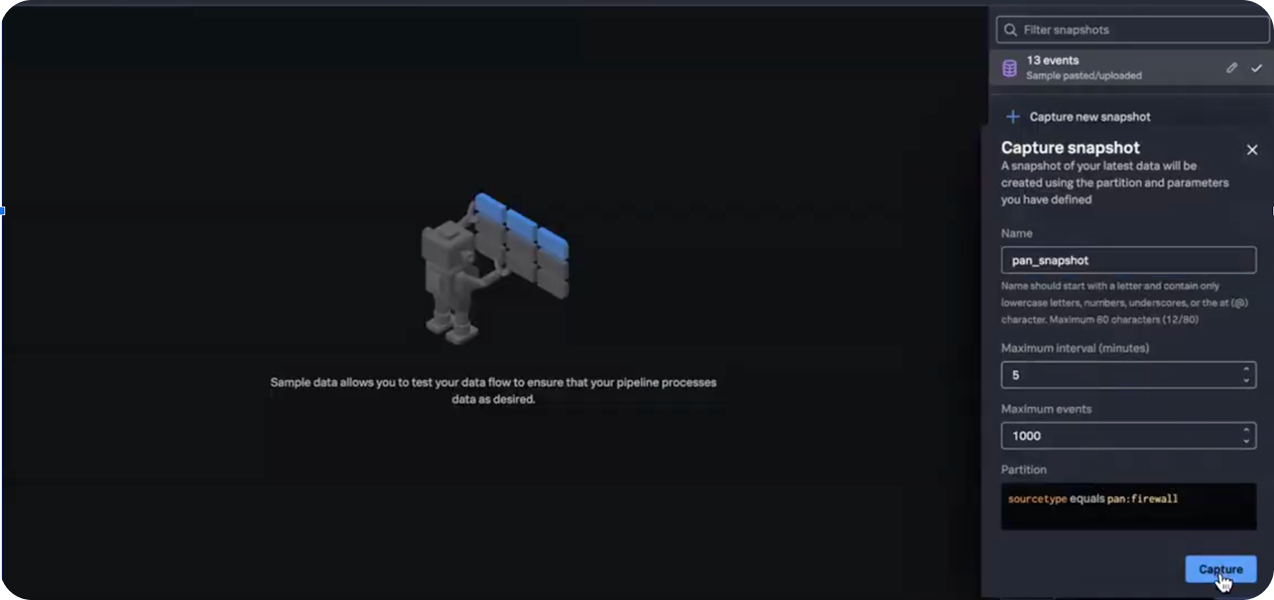
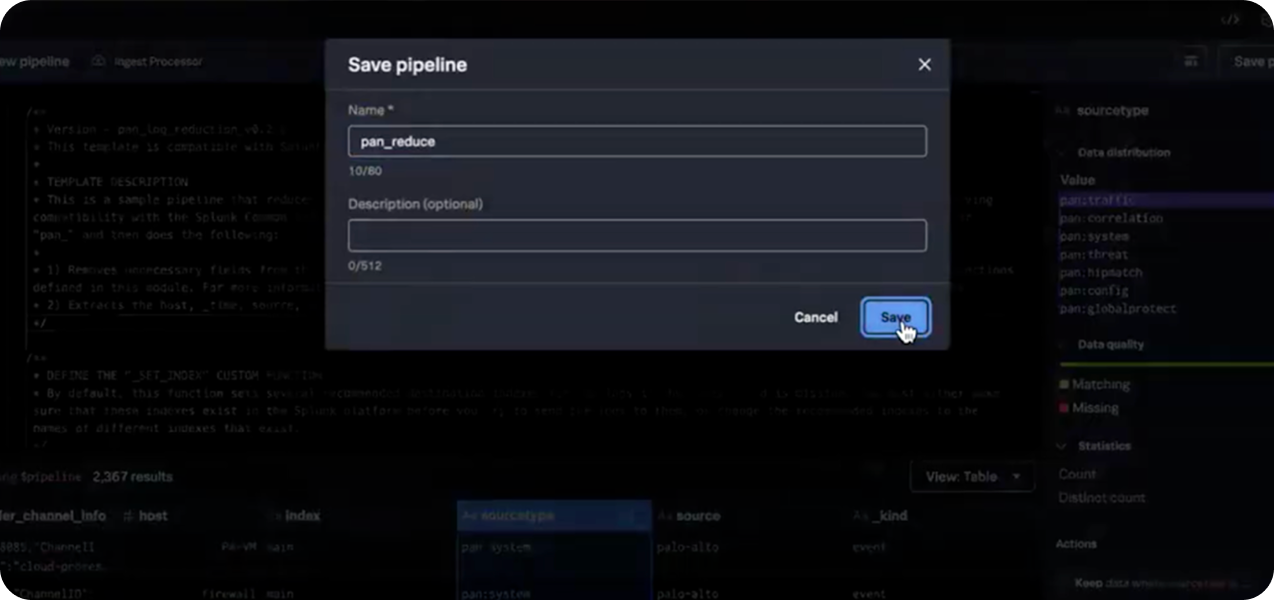
The PAN Pipeline Template is a pre-built SPL2-based logic that helps you classify, enrich, and optimize Palo Alto Networks logs, improving field extractions and reducing event sizes before they’re indexed in Splunk.
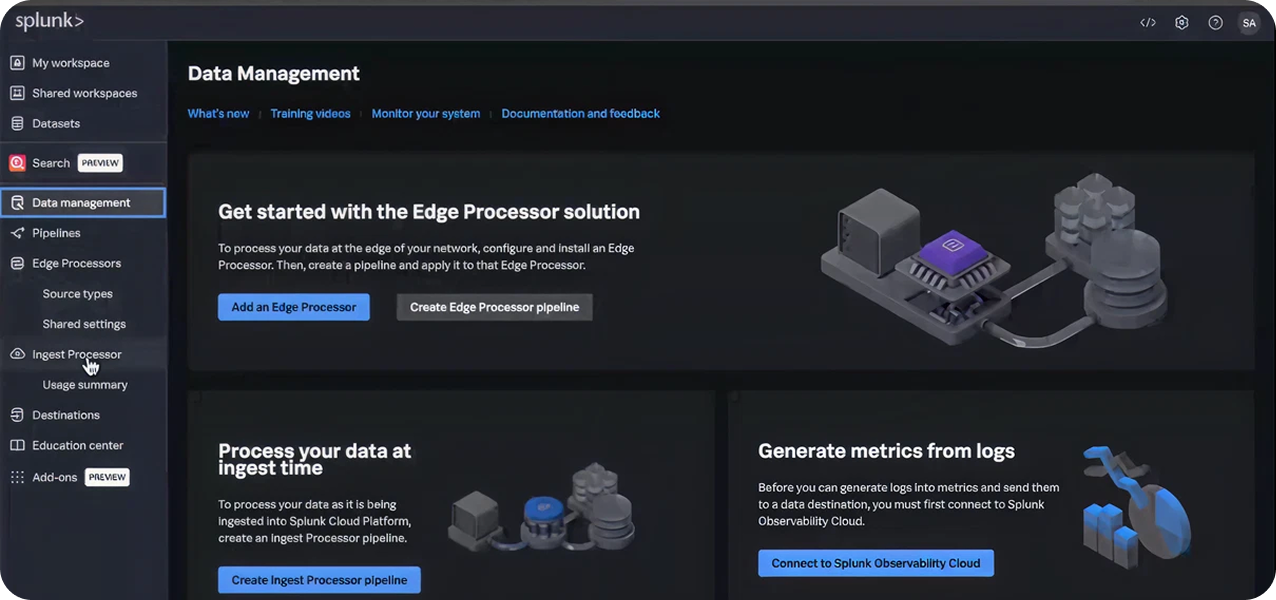
Note: This pipeline template can be applied in both Edge Processor and Ingest Processor. Unless you already have Edge Processor configured, we recommend using Ingest Processor to avoid additional configuration steps.
Here’s how you can get started:

Watch the PAN Template Demo Video
This video walks you through how to apply the PAN log reduction pipeline template. Follow along to quickly start filtering and routing your PAN logs. .