
Digital Resilience Pays Off
Download this e-book to learn about the role of Digital Resilience across enterprises.

Deutsche Bahn (DB) describes itself as the second largest transport company in the world and is the largest railway and infrastructure operator in Europe. With the popularity of Industry 4.0 and IoT in Germany, DB recently ran a “Deutsche Bahn goes 4.0” Hackathon over the weekend of May 8-9 2015. The concept was “We provide the data, you innovate with it”. Splunk participated with a crack team of two people, a copy of Splunk Enterprise running on a laptop and got their hands dirty digging into a labyrinth of infrastructure data. The challenge was tough: starting at 5pm we had 24 hours straight to analyze the data and demonstrate the value from it. After the final presentation of our solution and results, a panel of DB experts awarded the first prize to Team Splunk.
The hackathon consisted of three tasks and each team tried to solve one of them:
The Splunk team decided to work on Task 1 and look at track position defects. The questions DB wanted answers to included:
A deviation from the original track position in horizontal or vertical direction or a deviation of the tracks altitude. Such defects may occur during the construction or by transformation of the track bed.
Is it possible to extract reasons for the appearance of track position defects from the given data? Could you even think about building a model which illustrates correlations in this context? What are the reasons and possible models?
Are track position defects and the development of these defects predictable before they occur? Which correlations are recognizable between these defects and the used technology (e.g. wooden vs. concrete railroad ties) or weather conditions? Is there a link between indication notifications (Befundmeldungen) and disfunction notifications (Störmeldungen).
To solve this task, we onboarded a lot of heterogeneous data including data for geographical classification, data for tracks and points, level crossings, electrical equipment, bridges, tunnels and passages, orders, construction equipment, earthworks and retaining structures, telecommunication facilities, signaling construction, catenary system, machine techniques, conductor rail, MakSi-FM (construction works in tracks, time table changes etc.) and data for defects in tracks. The data was given in a bunch of CSV files, each containing its own structure, but without a visible connection among them. That’s why we described it as “unstructured structured” data.
One of our major challenges was to actually understand the data set and determine which parts of the data were relevant to answer the questions in the task. After onboarding the data into Splunk we used real time search and automatic field extraction to quickly dig into the data set and identify interesting aspects to the data.
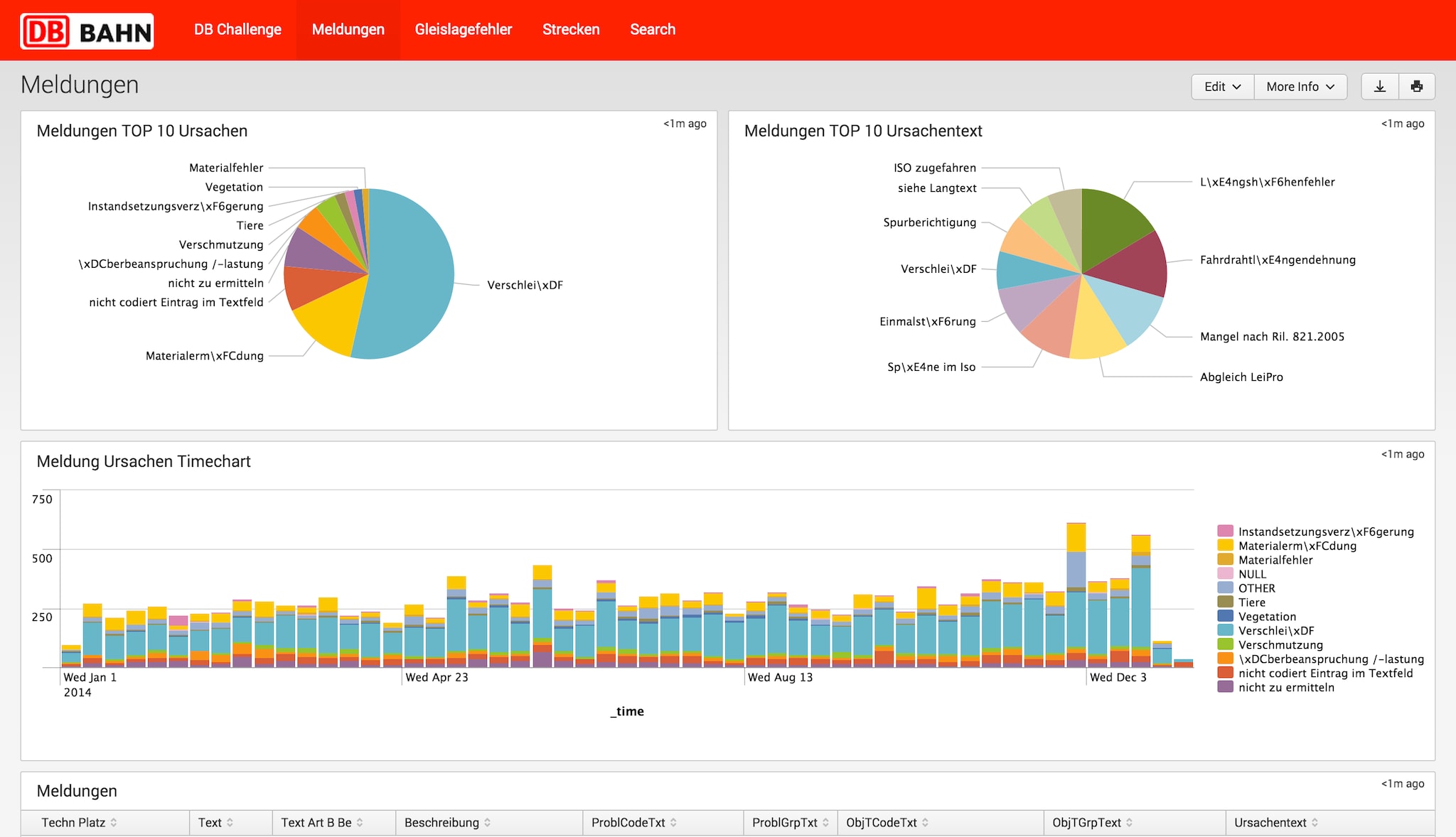
To help DB gain insights related to track defects, we first provided a breakdown of the major sources of indication notifications which specify problems on the railway tracks. The ‘Meldungen’ dashboard provides an overview of the top ten types of notifications about issues that have occurred in the transportation infrastructure. With the help of Splunk we were able to quickly create an overview of relevant data sources for further analysis:
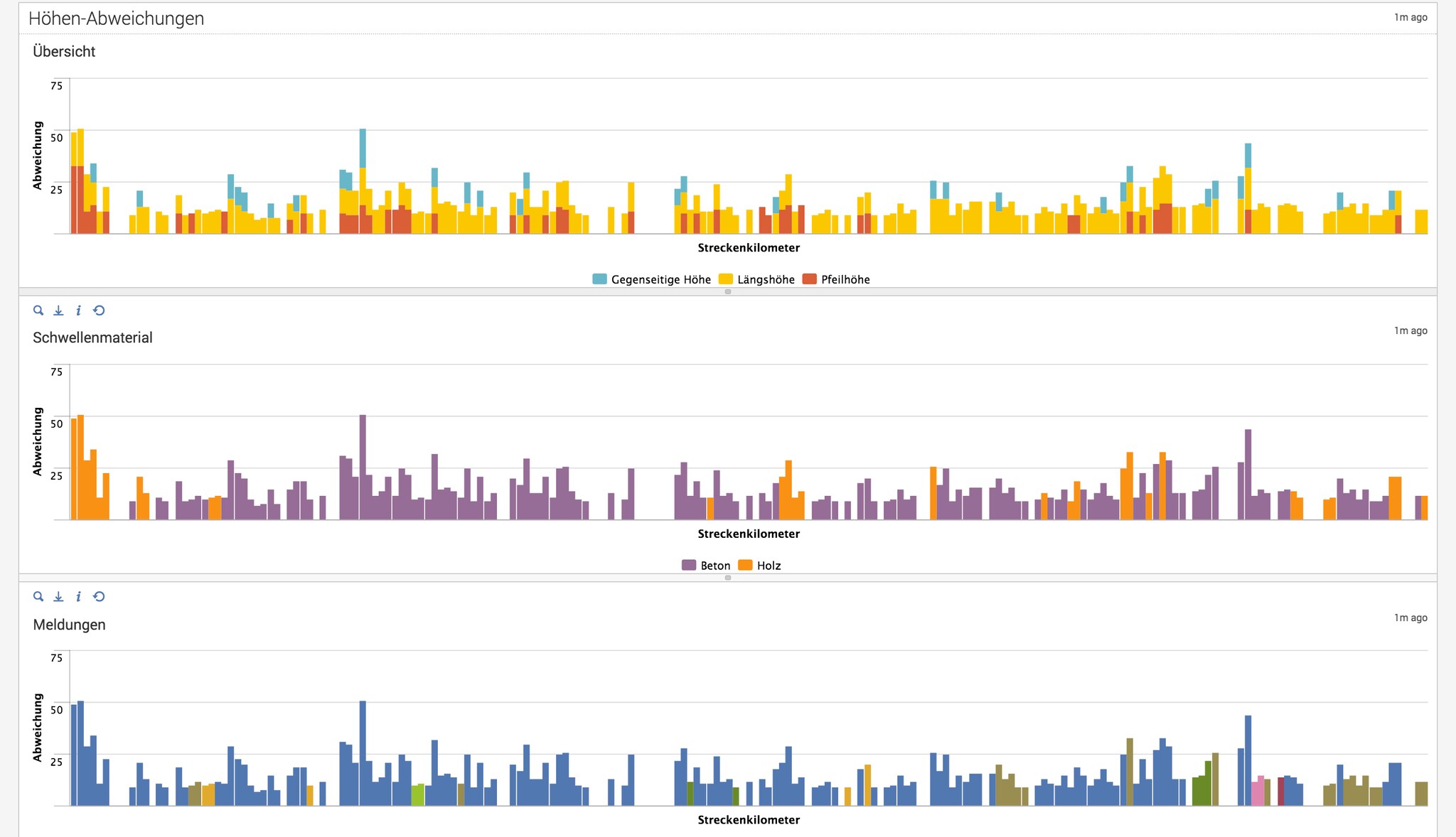
After creating this overview we focused on the task of finding possible reasons for track defects. First we created a visualization of different types of track defects for a given track number. Using stacked bar charts, we could easily show in which parts of the track what kinds of defects occur and quantify how big the deviations are (the first row in the screenshot below).
The second row (purple and yellow – below) represents the same deviations but correlates them with the materials of the track sleepers: concrete (“Beton”) vs. wood (“Holz”). After analyzing the data and flowing it into this dashboard, we found out that the wooden tracks (orange parts in the second chart) are often related to high track deviations, resulting in potential issues.
Further analysis of the whole data set revealed that using concrete results in 18% fewer track defects compared to wood. This supports the fact that concrete has a longer lifespan than wood and as a result, Deutsche Bahn could use this analysis to determine which parts of their tracks could be renewed with a material that is more resistant to natural erosion.
Finding reasons for track defects is key for DB to successfully maintain their infrastructure, improve operations, minimize potential travel disruption and offer better service for customers. With regards to predictive maintenance the third row (blue bars – above) correlates track deviations with indication notifications. Blue bars denote “no known issues” at the parts of the track. Interestingly, parts of the track with high deviations are not reflected in the notifications data. This presents DB with an opportunity to improve predictive maintenance by including this deviation data in their notifications. Splunk could be used to generate alerts when high deviations are identified in comparison to a historical moving average, but where no notification has been triggered yet. With this analysis DB could generate reports to find out which parts of their track should be considered for on-site investigation to proactively repair and maintain their infrastructure.
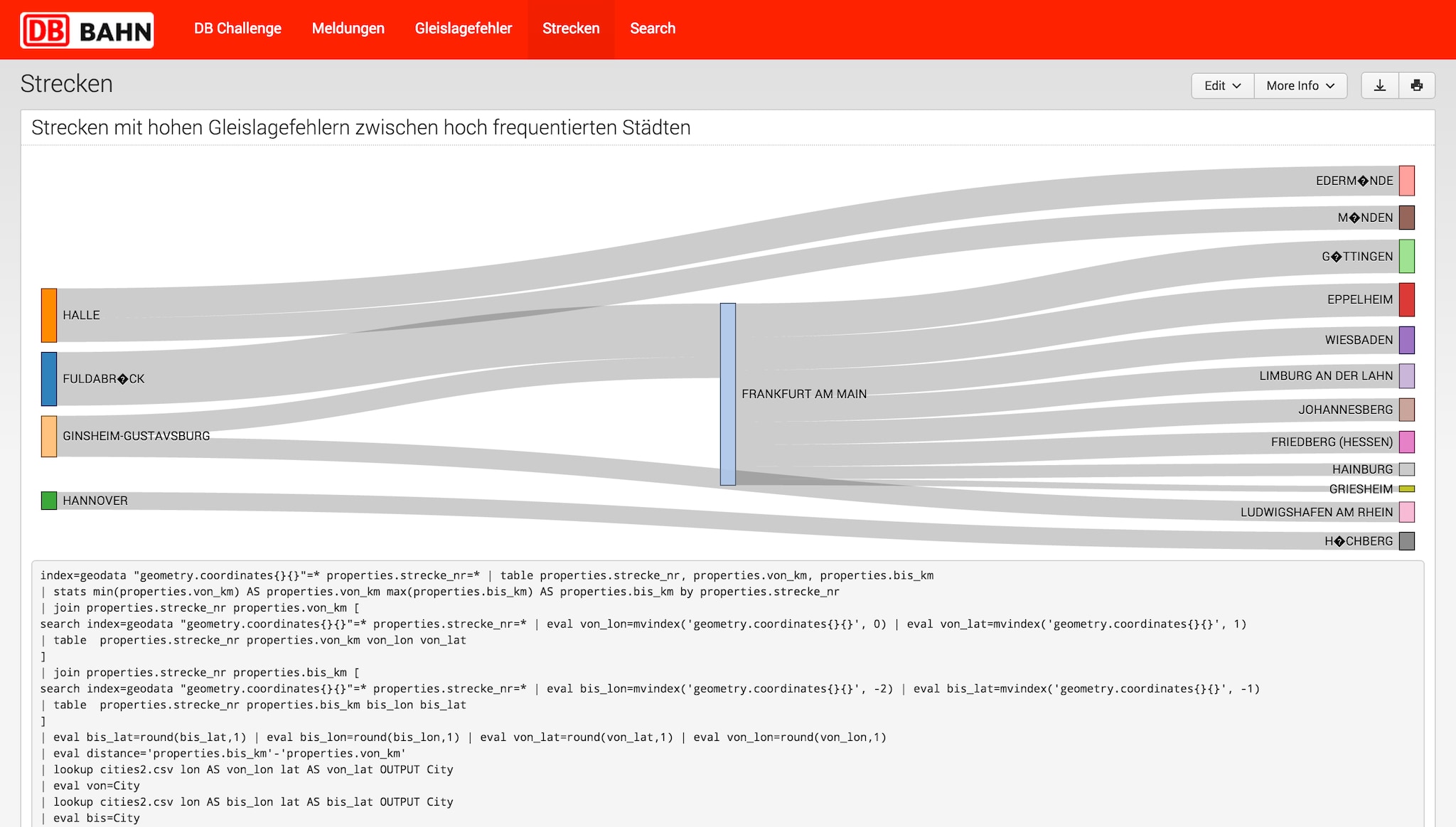
Furthermore, DB needs to understand what its top priorities should be. We conducted some more analysis and created another data visualization to understand where these defects are happening most frequently and therefore causing them (and their customers) the most pain. The sankey chart below shows the impact of track defects for connections between cities. In this case, the visualization shows the most frequently connected cities to the major hub of Frankfurt. The thickness of the lines to connecting cities indicates the amount of track deviations between different destinations from Frankfurt. One key finding for this example is that the connection between Fulda and Frankfurt has high track deviations (it is the widest bar) and therefore indicates the need for upcoming repair, maintenance and possible renewal of this connection.
Finally, we spend some time on the creative part of the challenge (“do what you want”) and discussed ideas how to enrich the given data. In the light of track position defects we thought about adding external data sources like earthquake or weather data. As railway infrastructure and especially tracks are highly exposed to nature we had the idea to correlate for example the geolocation of track defects to historic weather data to investigate natural erosion of the tracks. Our hypothesis was that there is a correlation between high humidity or extreme temperature changes to parts of the tracks with high defect rates. Even earthquake data could be considered together with any other data source that reflects natural conditions.
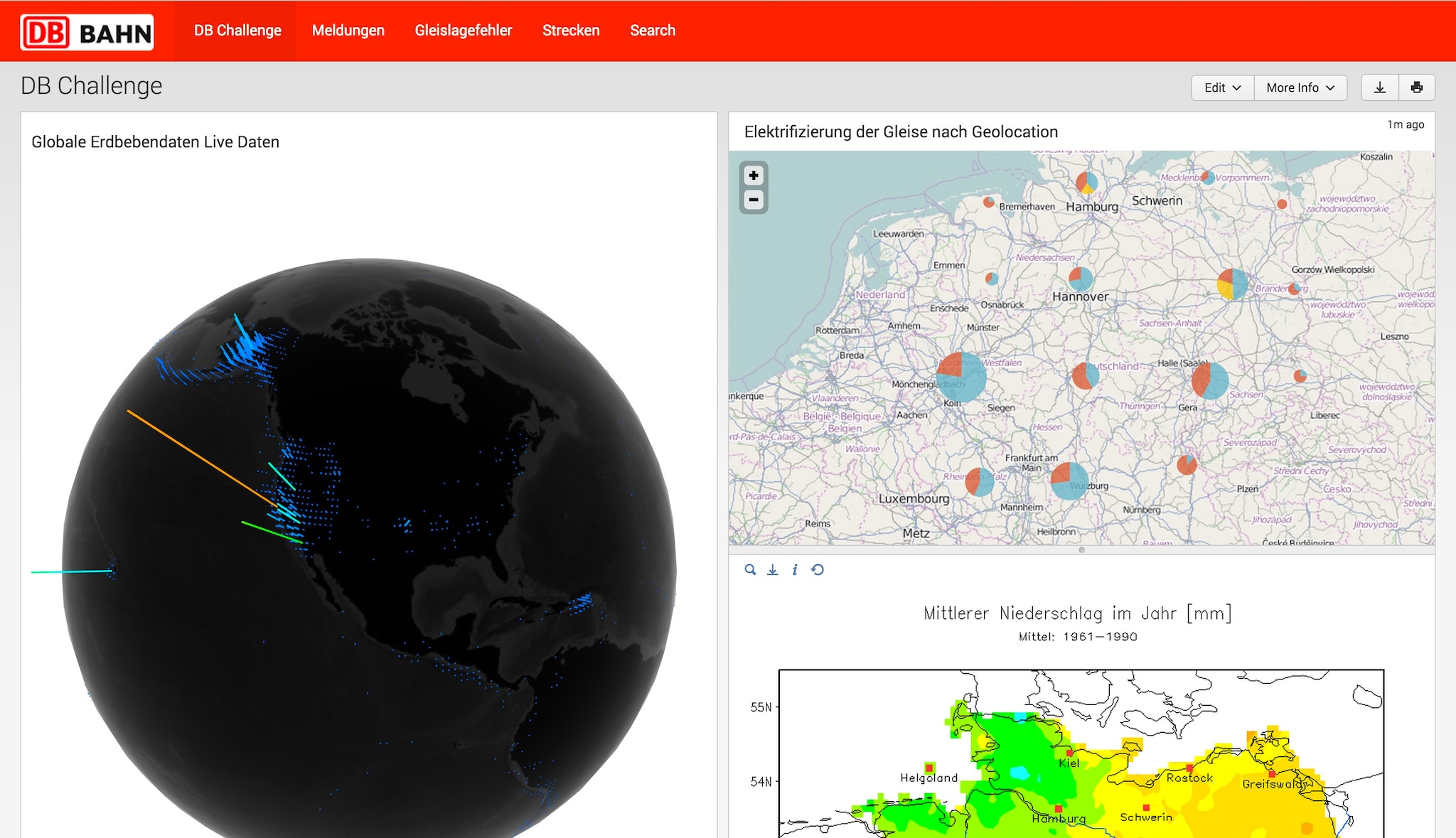
After a sleepless night, plenty of caffeine and 24 hours hard work, we presented our results to the jury and the audience. The success criteria were usability, potential business value, creativity and quality of demo and presentation. In all aspects we convinced the jury and we were delighted to win 1st place. Moreover, we demonstrated the flexibility of Splunk to analyze the very varied, diverse infrastructure data set that DB gave us.
Just imagine what we could do if we just had another 24 hours to play with the data…

The Splunk platform removes the barriers between data and action, empowering observability, IT and security teams to ensure their organizations are secure, resilient and innovative.
Founded in 2003, Splunk is a global company — with over 7,500 employees, Splunkers have received over 1,020 patents to date and availability in 21 regions around the world — and offers an open, extensible data platform that supports shared data across any environment so that all teams in an organization can get end-to-end visibility, with context, for every interaction and business process. Build a strong data foundation with Splunk.

Get the latest articles from Splunk straight to your inbox.
© 2005 - 2024 Splunk Inc. All rights reserved.
