
Digital Resilience Pays Off
Download this e-book to learn about the role of Digital Resilience across enterprises.
It must have been about a year ago now that I was talking with a Data Scientist at a Splunk Live event about some of the quite advanced use cases he was trying to achieve with Splunk. That conversation seeded some ideas in my mind , they fermented for a while as I toyed with designs , and over the last couple of months I’ve chipped away at creating a new Splunk App , Protocol Data Inputs (PDI).
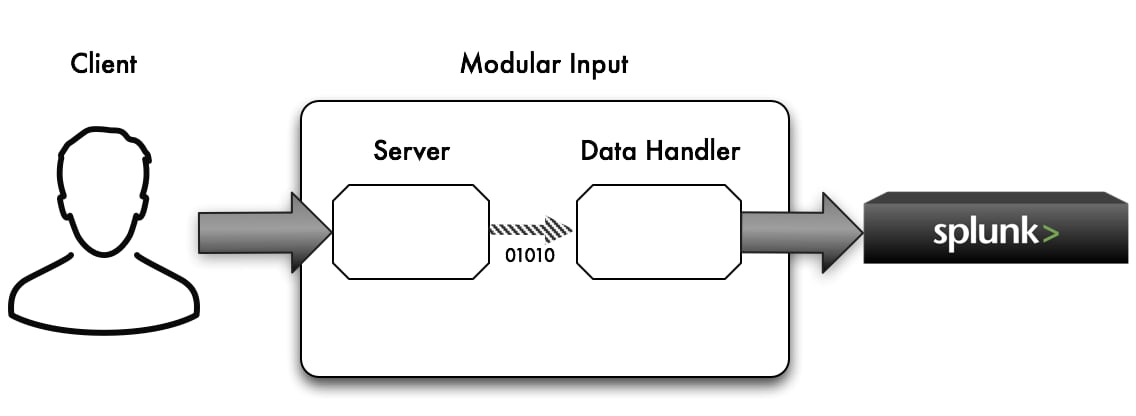
So what is this all about ? Well to put it quite simply , it is a Modular Input for receiving data via a number of different protocols, with some pretty cool bells and whistles.
So let’s break down some of the features.
PDI is implemented as a Modular Input , but the internal architecture relies on a little bit of special sauce.A framework called Vertx is utilized under the hood. I came across this framework because in a past life I had a great deal of success building very robust and scalable applications using Netty , and Vertx builds upon Netty. So I have become a bit of a fanboy of this ecosystem![]()
This framework provides for an implementation that is :
So what sort of protocols can PDI establish servers for ?
When the server receives some raw data (bytes) it does not alter the data in anyway. It simply receives the data and places it on an internal event bus. On the other side of this event bus is a data handler that you configure for each stanza you setup. It is then the job of the data handler to take these raw bytes and do something with them ie: turn them into text and output to Splunk.
The way in which the Modular Input processes the received raw data is entirely pluggable with custom implementations should you wish.
This allows you to :
To do this you code a Vertx “Verticle“ to handle the received data.
These data handlers can be written in numerous JVM languages.
You then place the handler in the protocol_ta/bin/datahandlers directory.
On the Splunk config screen for the Modular Input there is a field where you can then specify the name of this handler to be applied.
If you don’t need a custom handler then a default handler is used.This simply rolls out any received bytes to text.
To get started , you can refer to the default handler examples in the datahandlers directory.
As mentioned above , you can write your data handlers in numerous languages.
Currently available languages and their file suffixes are :
Experimental Nashorn support is included for js and coffee (requires Java 8). To use the Nashorn JS/Coffee engine rather than the default Rhino engine , then edit protocol_ta/bin/vertx_conf/langs.properties
A DynJS Javascript language engine is also available. This means that you can use Nodyn to run your Node.js scripts as Vertx Verticles. Check out this blog from the Nodyn team.
Due to the nature of the async/event driven/non blocking architecture , the out of the box default settings may just well suffice for you. But you can certainly “turn the amp up to 11” if you need to.
In the above diagram , you can see just 1 instance for the server and data handler. However if you want to achieve more scale and more effectively utillise your CPU cores , then you can declaratively add more instances.
This is provisioned using your own Java Keystore that you can create using the keytool utility that is part of the JDK.
Client certificate based authentication can be enabled for the TLS channels you setup.
Any required Vertx modules , such as various language modules for the polyglot functionality, will be dynamically downloaded from online repositorys and installed in your protocol_ta/bin/vertx_modules directory.
You can edit your repository locations in protocol_ta/bin/vertx_conf/repos.txt
Yes we do. And by all means use those if they suit your use case. But if you want to perform some custom data handling and pre-processing of the received data before it gets indexed (above and beyond what you can accomplish using Splunk conf files) ,then this Modular Input presents another option for you.Furthermore , this Modular Input also implements several other protocols for sending data to Splunk.
View PDI Source and example Data Handlers on Github
Download PDI App from apps.splunk.com
Presentation by Tim Fox (Tim is employed by Red Hat where he is the creator and project lead for Vertx)
Download it, use it, tell me how to make it better , create data handlers in your language of choice and share them with the community. But most importantly….. get crazy and innovative with your data !!

----------------------------------------------------
Thanks!
Damien Dallimore

The Splunk platform removes the barriers between data and action, empowering observability, IT and security teams to ensure their organizations are secure, resilient and innovative.
Founded in 2003, Splunk is a global company — with over 7,500 employees, Splunkers have received over 1,020 patents to date and availability in 21 regions around the world — and offers an open, extensible data platform that supports shared data across any environment so that all teams in an organization can get end-to-end visibility, with context, for every interaction and business process. Build a strong data foundation with Splunk.

Get the latest articles from Splunk straight to your inbox.
© 2005 - 2024 Splunk Inc. All rights reserved.
