
Digital Resilience Pays Off
Download this e-book to learn about the role of Digital Resilience across enterprises.
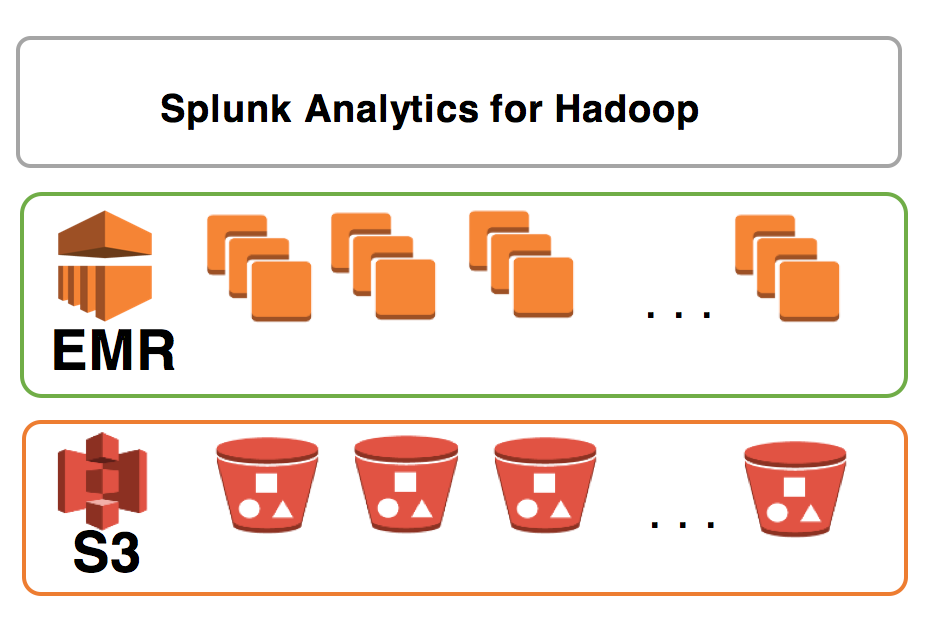
Using Amazon EMR and Splunk Analytics for Hadoop to explore, analyze and visualize machine data
Machine data can take many forms and comes from a variety of sources; system logs, application logs, service and system metrics, sensors data etc. In this step-by-step guide, you will learn how to build a big data solution for fast, interactive analysis of data stored in Amazon S3 or Hadoop. This hands-on guide is useful for solution architects, data analysts and developers.
This guide will see you:
You will need:
To get started, go into Amazon EMR from the AWS management console page:

From here, you can manage your existing clusters, or create a new cluster. Click on ‘Create Cluster’:
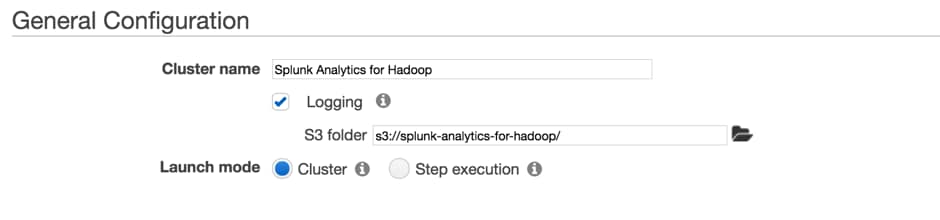
This will take you to the configuration page. Set a meaningful cluster name, enable logging (if required) to an existing Amazon S3 bucket, and set the launch mode to cluster:
Under software configuration, choose Amazon EMR 5.x as per the following:
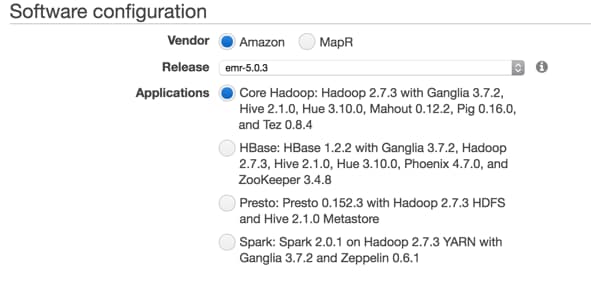
Several of the applications included are not required to run Splunk Analytics for Hadoop, however they may make management of your environment easier.
Choose the appropriate instance types, and number of instances according to your requirements:

** please note that Splunk recommends Hadoop nodes to be 8 cores / 16 vCPU. The M3.xlarge instances were used for demonstration here only.
For security and access settings, choose those appropriate to your deployment scenario. Using the defaults here can be an appropriate option:
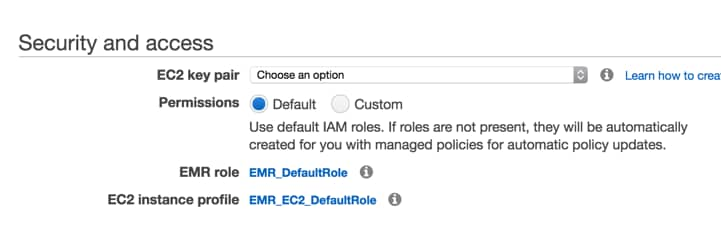
Click ‘Create Cluster’.
This process may take some time. Keep an eye on the Cluster list for status changes:

When the cluster is deployed and ready:

Clicking on the cluster name will provide the details of the set up:
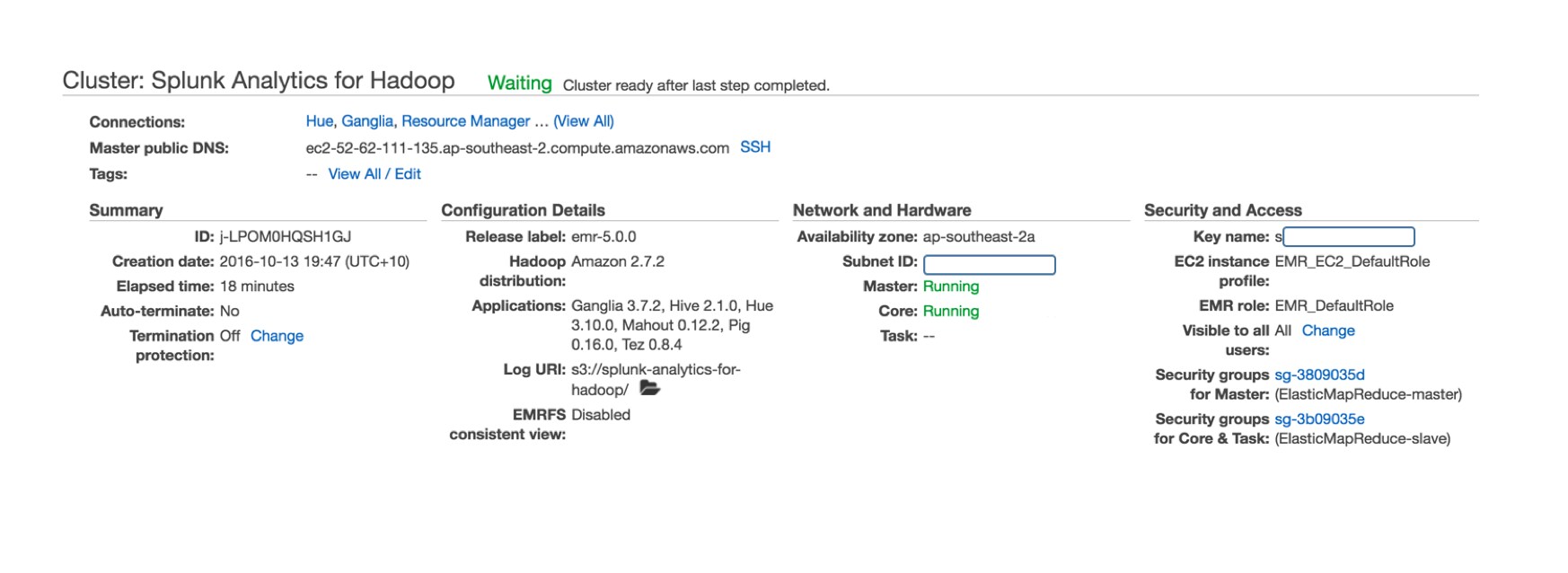
At this point, browse around the platform, and get familiar with the operation of the EMR cluster. Hue is a good option for managing the filesystem, and the data that will be analyzed through Splunk Analytics for Hadoop.
Installing Splunk Analytics for Hadoop on a separate Amazon EC2 instance, removed from yourAmazon EMR cluster is the Splunk recommended architectural approach. In order to configure this setup, we run up a Splunk 6.5 AMI from the AWS Marketplace, and then add the necessary Hadoop,Amazon S3 and Java libraries. This last step is further outlined on Splunk docs at -http://docs.splunk.com/Documentation/HadoopConnect/1.2.3/DeployHadoopConnect/HadoopCLI
To kick off, launch a newAmazon EC2 instance from the AWS Management Console:

Search the AWS Marketplace for Splunk and select the Splunk Enterprise 6.5 AMI:

Choose an instance size to suit your environment and requirements:
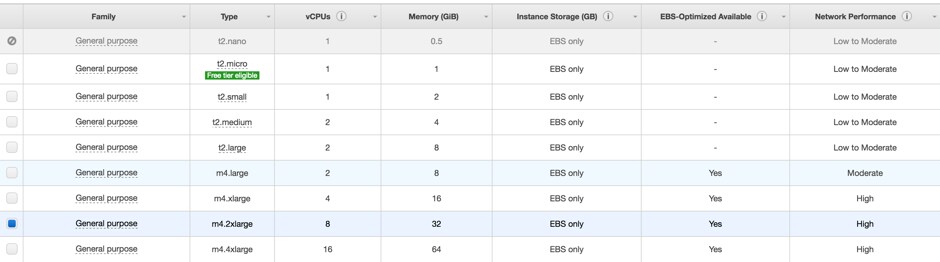
**please note that Splunk recommends minimum hardware specs for a production deployment. More details at http://docs.splunk.com/Documentation/Splunk/6.5.0/Installation/Systemrequirements
From here you can choose to further customize the instance (should you want more storage, or to add custom tags), or just review and launch:

Now, you’ll need to add the Hadoop,Amazon S3 and Java client libraries to the newly deployed Splunk AMI. To do this, first grab the versions from theAmazon EMR master node for each, to ensure that you are matching the libraries on your Splunk server. Once you have them, install them on the Splunk AMI:

Move this to /usr/bin and unpack it.
In order to search theAmazon S3 data, we need to ensure we have access to the S3 toolset. Add the following line to the file /usr/bin/hadoop/etc/hadoop/hadoop-env.sh:
export HADOOP_CLASSPATH=$HADOOP_CLASSPATH:$HADOOP_HOME/share/hadoop/tools/lib/*
Finally, we need to setup the necessary authentication to access Amazon S3 via our new virtual index connection. You’ll need a secret key ID and access key from your AWS Identity and Access Management (IAM) setup. In this instance, we have setup these credentials for an individual AWS user:
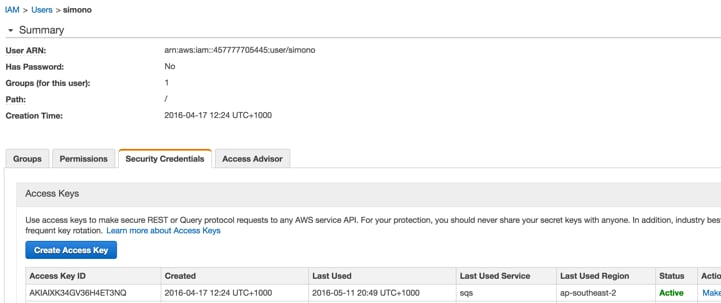
Ensure that when you create the access key, you record the details. You then need to include these in the file located at /usr/bin/hadoop/etc/hadoop/hdfs-site.xml. Include the following within the <configuration> tag:
<property> <name>fs.s3.awsAccessKeyId</name> <value>xxxx</value> </property> <property> <name>fs.s3.awsSecretAccessKey</name> <value>xxxx</value> </property> <property> <name>fs.s3n.awsAccessKeyId</name> <value>xxxx</value> </property> <property> <name>fs.s3n.awsSecretAccessKey</name> <value>xxxx</value> </property>
You need to include the s3n keys, as that is the mechanism we will use to connect to the Amazon s3 dataset.
We have multiple options for connecting to data for investigation within Splunk Analytics for Hadoop. In this guide, we will explore adding files to HDFS via Hue, and connecting to an existing Amazon S3 bucket to explore data.
From the AWS Management Console, go into Amazon S3, and create a new bucket:
![]()
Give the bucket a meaningful name, and specify the region in which you would like it to exist:
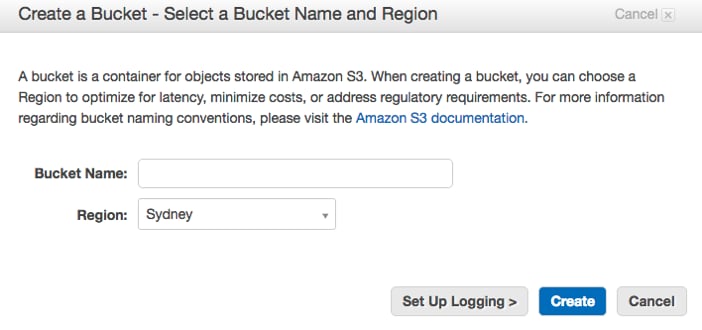
Click create, and add some files to this new bucket as appropriate. You can choose to add the files to the top level, or create a directory structure:
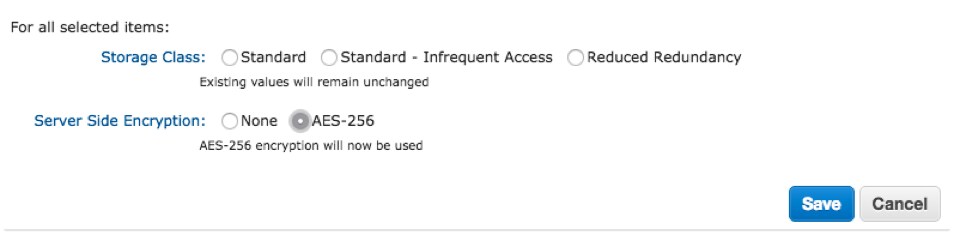
The files or folders that you create within the Amazon S3 bucket need to have appropriate permissions to allow the Splunk Analytics for Hadoop user to connect and view them. Set these to allow ‘everyone’ read access, and reduce this scope to appropriate users or roles after testing.
To proceed, first you’ll need to grab some parameters from the Hadoop nodes:
Collect Hadoop and Yarn variables:
Now, we need to verify that the name node is correct. You can do this by executing this command:
hadoop fs –ls hdfs://masternodeaddress:8020/user/root/data
Now we can configure our Virtual Provider in Splunk. To do this, go to settings, and then Virtual Indexes:
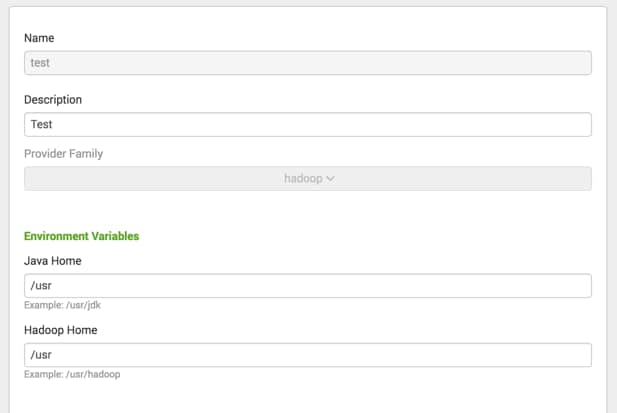
Then choose to create a new provider:

Using the parameters that we gathered earlier, fill this section out:
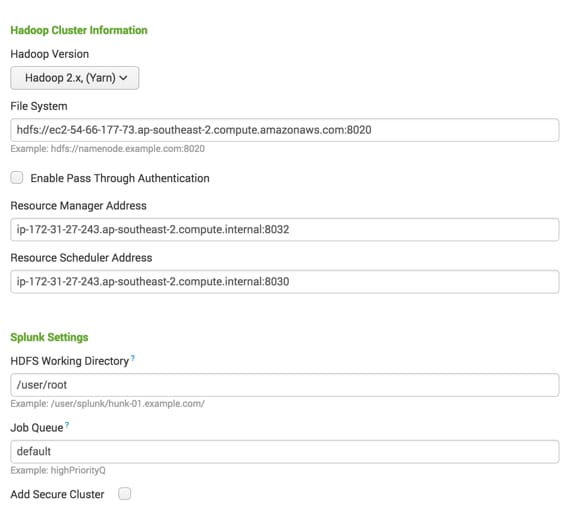
Save this setup, and go to set up a new Virtual Index:

Here you can specify the S3 bucket that was created:
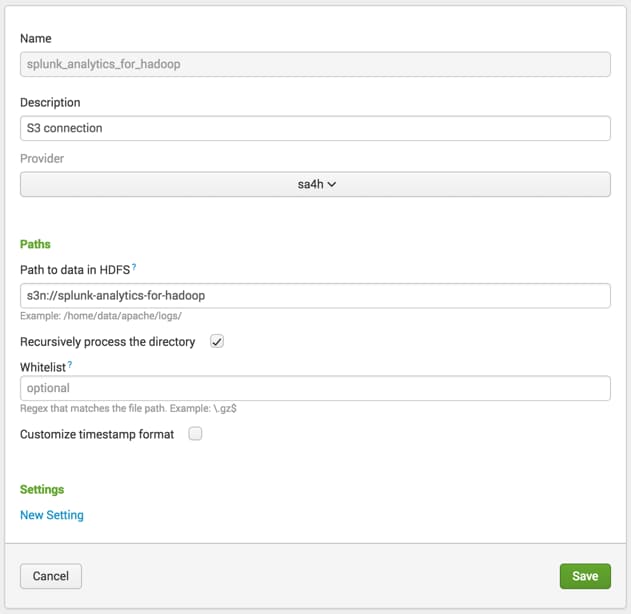
Ensure that you use the s3n prefix here.
Save this set up, and you should now be able to search the data within Amazon S3 (or HDFS) using Splunk Analytics for Hadoop!
Click search on the virtual index config:
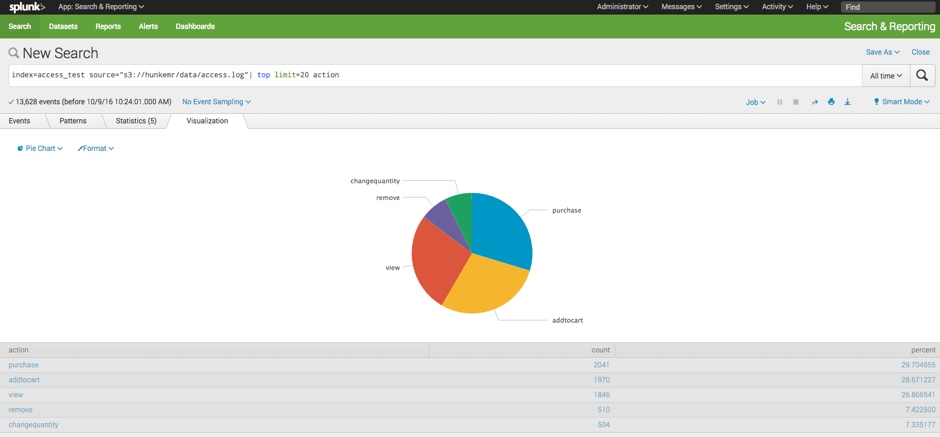
Which will take you to the Splunk search interface. You should see something like the following:
**Please note: The following is an example approach outlining a functional Splunk Analytics for Hadoop environment running on AWS EMR. Please talk to your local Splunk team to determine the best architecture for you.

The Splunk platform removes the barriers between data and action, empowering observability, IT and security teams to ensure their organizations are secure, resilient and innovative.
Founded in 2003, Splunk is a global company — with over 7,500 employees, Splunkers have received over 1,020 patents to date and availability in 21 regions around the world — and offers an open, extensible data platform that supports shared data across any environment so that all teams in an organization can get end-to-end visibility, with context, for every interaction and business process. Build a strong data foundation with Splunk.

Get the latest articles from Splunk straight to your inbox.
© 2005 - 2024 Splunk Inc. All rights reserved.
